Humanizing Machine-Generated Content: Evading AI-Text Detection through Adversarial Attack
2404.01907
0
0
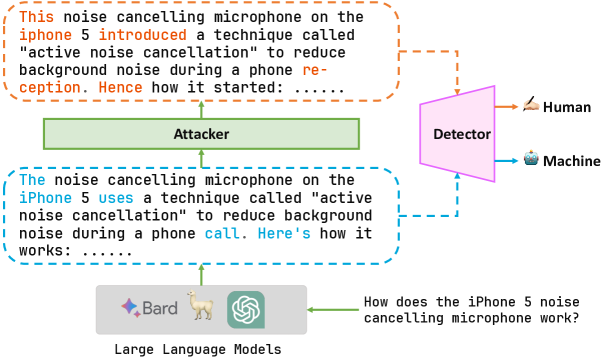
Abstract
With the development of large language models (LLMs), detecting whether text is generated by a machine becomes increasingly challenging in the face of malicious use cases like the spread of false information, protection of intellectual property, and prevention of academic plagiarism. While well-trained text detectors have demonstrated promising performance on unseen test data, recent research suggests that these detectors have vulnerabilities when dealing with adversarial attacks such as paraphrasing. In this paper, we propose a framework for a broader class of adversarial attacks, designed to perform minor perturbations in machine-generated content to evade detection. We consider two attack settings: white-box and black-box, and employ adversarial learning in dynamic scenarios to assess the potential enhancement of the current detection model's robustness against such attacks. The empirical results reveal that the current detection models can be compromised in as little as 10 seconds, leading to the misclassification of machine-generated text as human-written content. Furthermore, we explore the prospect of improving the model's robustness over iterative adversarial learning. Although some improvements in model robustness are observed, practical applications still face significant challenges. These findings shed light on the future development of AI-text detectors, emphasizing the need for more accurate and robust detection methods.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper explores techniques to make machine-generated text appear more human-like and evade detection by AI-based text classifiers.
- The researchers developed an "adversarial attack" approach that can subtly modify machine-generated text to make it less detectable as artificial.
- This has implications for areas like content generation, chatbots, and other applications where AI-generated text is used.
Plain English Explanation
The goal of this research is to make it harder for computers to tell the difference between text written by humans and text generated by artificial intelligence (AI) systems. The researchers developed a method that can take AI-generated text and modify it in small ways to make it seem more human-like.
Imagine you have an AI that can write short articles or stories. Even though the text sounds natural, there may be subtle patterns or quirks that give away the fact it was written by a machine. This new technique the researchers created can identify those machine-like elements and tweak the text to hide them.
So the end result is text that reads just as smoothly as human-written content, but was actually generated by an AI. This could be useful for things like chatbots, virtual assistants, content creation tools, and other applications where AI-generated text is used. By making the text more human-like, it becomes harder for other AI systems to detect that it's artificial.
The key idea is to use an "adversarial attack" - this means deliberately trying to fool or confuse an AI system, in this case a text classifier that tries to detect machine-generated content. The researchers developed algorithms that can identify the subtle cues that give away AI-generated text, and then make targeted changes to mask those cues.
Technical Explanation
The paper presents a novel adversarial attack approach to make machine-generated text appear more human-like and evade detection by AI-based text classifiers. The core idea is to identify the specific linguistic features that distinguish AI-generated text from human-written text, and then carefully modify the generated text to obfuscate those distinguishing characteristics.
The researchers first trained a text classifier to identify machine-generated content with high accuracy. They then developed an adversarial attack method that iteratively perturbs the input text in a way that fools the classifier into misclassifying the text as human-written. This is achieved through a gradient-based optimization process that targets the model's decision boundaries.
The key technical innovations include:
- A comprehensive linguistic feature set to capture stylistic, syntactic, and semantic differences between human and AI-generated text
- A differentiable text generation model that allows gradient-based optimization of the input text
- A multi-objective optimization approach that balances semantic preservation and classifier evasion
Experiments on a range of machine-generated text datasets demonstrated the effectiveness of the proposed adversarial attack in generating human-like text that successfully evades state-of-the-art AI detectors. This has significant implications for applications like content moderation, chatbots, and other domains where the ability to distinguish human from machine-generated text is crucial.
Critical Analysis
The research provides a compelling technical approach to make machine-generated text more difficult to detect. However, the paper does not extensively discuss the potential societal implications and ethical concerns around this technique.
One limitation is that the paper does not explore how the adversarial attack could be abused to enable the large-scale production of misleading or deceptive content. Malicious actors could potentially leverage this method to generate convincing fake reviews, social media posts, or other types of content intended to mislead readers. The researchers should have acknowledged these risks and discussed potential mitigation strategies.
Additionally, the paper does not address how this attack could undermine content moderation and verification efforts. If AI detectors become less reliable at identifying machine-generated text, it could enable the spread of misinformation, propaganda, and other harmful content online. The researchers could have delved into these societal implications in more depth.
That said, the technical contributions of the paper are significant and could also have beneficial applications, such as improving the realism of AI-generated text for creative writing, educational chatbots, and other legitimate use cases. Further research is needed to better understand the tradeoffs and develop responsible guidelines for the use of these techniques.
Conclusion
This research presents a novel adversarial attack that can make machine-generated text appear more human-like and evade detection by AI-based classifiers. While the technical approach is impressive, the paper does not adequately address the potential for misuse and the broader societal implications of this capability.
As language models and other AI systems become more advanced, the ability to generate convincing human-like text will only increase. This research demonstrates that even state-of-the-art detectors can be fooled, highlighting the need for more robust techniques to verify the origin of online content. Moving forward, the research community should prioritize studying the ethical considerations and developing safeguards to ensure these powerful techniques are used responsibly.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
Adapting Fake News Detection to the Era of Large Language Models
Jinyan Su, Claire Cardie, Preslav Nakov
0
0
In the age of large language models (LLMs) and the widespread adoption of AI-driven content creation, the landscape of information dissemination has witnessed a paradigm shift. With the proliferation of both human-written and machine-generated real and fake news, robustly and effectively discerning the veracity of news articles has become an intricate challenge. While substantial research has been dedicated to fake news detection, this either assumes that all news articles are human-written or abruptly assumes that all machine-generated news are fake. Thus, a significant gap exists in understanding the interplay between machine-(paraphrased) real news, machine-generated fake news, human-written fake news, and human-written real news. In this paper, we study this gap by conducting a comprehensive evaluation of fake news detectors trained in various scenarios. Our primary objectives revolve around the following pivotal question: How to adapt fake news detectors to the era of LLMs? Our experiments reveal an interesting pattern that detectors trained exclusively on human-written articles can indeed perform well at detecting machine-generated fake news, but not vice versa. Moreover, due to the bias of detectors against machine-generated texts cite{su2023fake}, they should be trained on datasets with a lower machine-generated news ratio than the test set. Building on our findings, we provide a practical strategy for the development of robust fake news detectors.
4/16/2024
🔮
Semantic Stealth: Adversarial Text Attacks on NLP Using Several Methods
Roopkatha Dey, Aivy Debnath, Sayak Kumar Dutta, Kaustav Ghosh, Arijit Mitra, Arghya Roy Chowdhury, Jaydip Sen
0
0
In various real-world applications such as machine translation, sentiment analysis, and question answering, a pivotal role is played by NLP models, facilitating efficient communication and decision-making processes in domains ranging from healthcare to finance. However, a significant challenge is posed to the robustness of these natural language processing models by text adversarial attacks. These attacks involve the deliberate manipulation of input text to mislead the predictions of the model while maintaining human interpretability. Despite the remarkable performance achieved by state-of-the-art models like BERT in various natural language processing tasks, they are found to remain vulnerable to adversarial perturbations in the input text. In addressing the vulnerability of text classifiers to adversarial attacks, three distinct attack mechanisms are explored in this paper using the victim model BERT: BERT-on-BERT attack, PWWS attack, and Fraud Bargain's Attack (FBA). Leveraging the IMDB, AG News, and SST2 datasets, a thorough comparative analysis is conducted to assess the effectiveness of these attacks on the BERT classifier model. It is revealed by the analysis that PWWS emerges as the most potent adversary, consistently outperforming other methods across multiple evaluation scenarios, thereby emphasizing its efficacy in generating adversarial examples for text classification. Through comprehensive experimentation, the performance of these attacks is assessed and the findings indicate that the PWWS attack outperforms others, demonstrating lower runtime, higher accuracy, and favorable semantic similarity scores. The key insight of this paper lies in the assessment of the relative performances of three prevalent state-of-the-art attack mechanisms.
4/9/2024

Deciphering Textual Authenticity: A Generalized Strategy through the Lens of Large Language Semantics for Detecting Human vs. Machine-Generated Text
Mazal Bethany, Brandon Wherry, Emet Bethany, Nishant Vishwamitra, Anthony Rios, Peyman Najafirad
0
0
With the recent proliferation of Large Language Models (LLMs), there has been an increasing demand for tools to detect machine-generated text. The effective detection of machine-generated text face two pertinent problems: First, they are severely limited in generalizing against real-world scenarios, where machine-generated text is produced by a variety of generators, including but not limited to GPT-4 and Dolly, and spans diverse domains, ranging from academic manuscripts to social media posts. Second, existing detection methodologies treat texts produced by LLMs through a restrictive binary classification lens, neglecting the nuanced diversity of artifacts generated by different LLMs. In this work, we undertake a systematic study on the detection of machine-generated text in real-world scenarios. We first study the effectiveness of state-of-the-art approaches and find that they are severely limited against text produced by diverse generators and domains in the real world. Furthermore, t-SNE visualizations of the embeddings from a pretrained LLM's encoder show that they cannot reliably distinguish between human and machine-generated text. Based on our findings, we introduce a novel system, T5LLMCipher, for detecting machine-generated text using a pretrained T5 encoder combined with LLM embedding sub-clustering to address the text produced by diverse generators and domains in the real world. We evaluate our approach across 9 machine-generated text systems and 9 domains and find that our approach provides state-of-the-art generalization ability, with an average increase in F1 score on machine-generated text of 19.6% on unseen generators and domains compared to the top performing existing approaches and correctly attributes the generator of text with an accuracy of 93.6%.
4/4/2024
🤖
Detecting AI Generated Text Based on NLP and Machine Learning Approaches
Nuzhat Prova
0
0
Recent advances in natural language processing (NLP) may enable artificial intelligence (AI) models to generate writing that is identical to human written form in the future. This might have profound ethical, legal, and social repercussions. This study aims to address this problem by offering an accurate AI detector model that can differentiate between electronically produced text and human-written text. Our approach includes machine learning methods such as XGB Classifier, SVM, BERT architecture deep learning models. Furthermore, our results show that the BERT performs better than previous models in identifying information generated by AI from information provided by humans. Provide a comprehensive analysis of the current state of AI-generated text identification in our assessment of pertinent studies. Our testing yielded positive findings, showing that our strategy is successful, with the BERT emerging as the most probable answer. We analyze the research's societal implications, highlighting the possible advantages for various industries while addressing sustainability issues pertaining to morality and the environment. The XGB classifier and SVM give 0.84 and 0.81 accuracy in this article, respectively. The greatest accuracy in this research is provided by the BERT model, which provides 0.93% accuracy.
4/17/2024