Methodology for Interpretable Reinforcement Learning for Optimizing Mechanical Ventilation
2404.03105
0
0
Abstract
Mechanical ventilation is a critical life-support intervention that uses a machine to deliver controlled air and oxygen to a patient's lungs, assisting or replacing spontaneous breathing. While several data-driven approaches have been proposed to optimize ventilator control strategies, they often lack interpretability and agreement with general domain knowledge. This paper proposes a methodology for interpretable reinforcement learning (RL) using decision trees for mechanical ventilation control. Using a causal, nonparametric model-based off-policy evaluation, we evaluate the policies in their ability to gain increases in SpO2 while avoiding aggressive ventilator settings which are known to cause ventilator induced lung injuries and other complications. Numerical experiments using MIMIC-III data on the stays of real patients' intensive care unit stays demonstrate that the decision tree policy outperforms the behavior cloning policy and is comparable to state-of-the-art RL policy. Future work concerns better aligning the cost function with medical objectives to generate deeper clinical insights.
Create account to get full access
Overview
- This paper proposes a methodology for using interpretable reinforcement learning to optimize mechanical ventilation, a critical medical procedure for patients with respiratory issues.
- The key idea is to develop an AI system that can autonomously adjust ventilator settings to improve patient outcomes, while also providing explanations for its decisions to help clinicians understand and trust the system.
- The researchers design experiments to evaluate their approach on simulated ventilation scenarios, demonstrating its potential to outperform current ventilation practices.
Plain English Explanation
Mechanical ventilation is a vital medical treatment used to help patients who are having trouble breathing on their own. It involves a machine called a ventilator that takes over the work of breathing by pushing air in and out of the patient's lungs. Adjusting the ventilator settings correctly is crucial for the patient's recovery, but it can be challenging for clinicians to know the optimal settings.
The authors of this paper wanted to create an AI system that could automatically adjust the ventilator settings to provide the best care for the patient. They used a machine learning technique called reinforcement learning, which allows the AI to learn by trial-and-error, similar to how a person might learn a new skill. The key innovation is that the AI system not only adjusts the ventilator settings, but also provides explanations for why it is making those adjustments. This "interpretability" is important because it helps the clinicians understand the AI's reasoning and feel confident in trusting its decisions.
The researchers tested their approach using simulated ventilation scenarios, and found that the AI system was able to outperform current ventilation practices. This suggests that their methodology could be a powerful tool for improving patient outcomes in real-world medical settings, by automating ventilator adjustments while keeping clinicians informed and in control.
Technical Explanation
The paper presents a methodology for using interpretable reinforcement learning to optimize mechanical ventilation. The researchers developed a reinforcement learning agent that can autonomously adjust ventilator settings to improve patient outcomes, while also providing explanations for its decisions.
The agent is trained using a reward function that encourages it to find ventilator settings that minimize patient discomfort and complications. The agent's decision-making process is made interpretable through the use of attention mechanisms, which highlight the key factors it is considering when selecting an action.
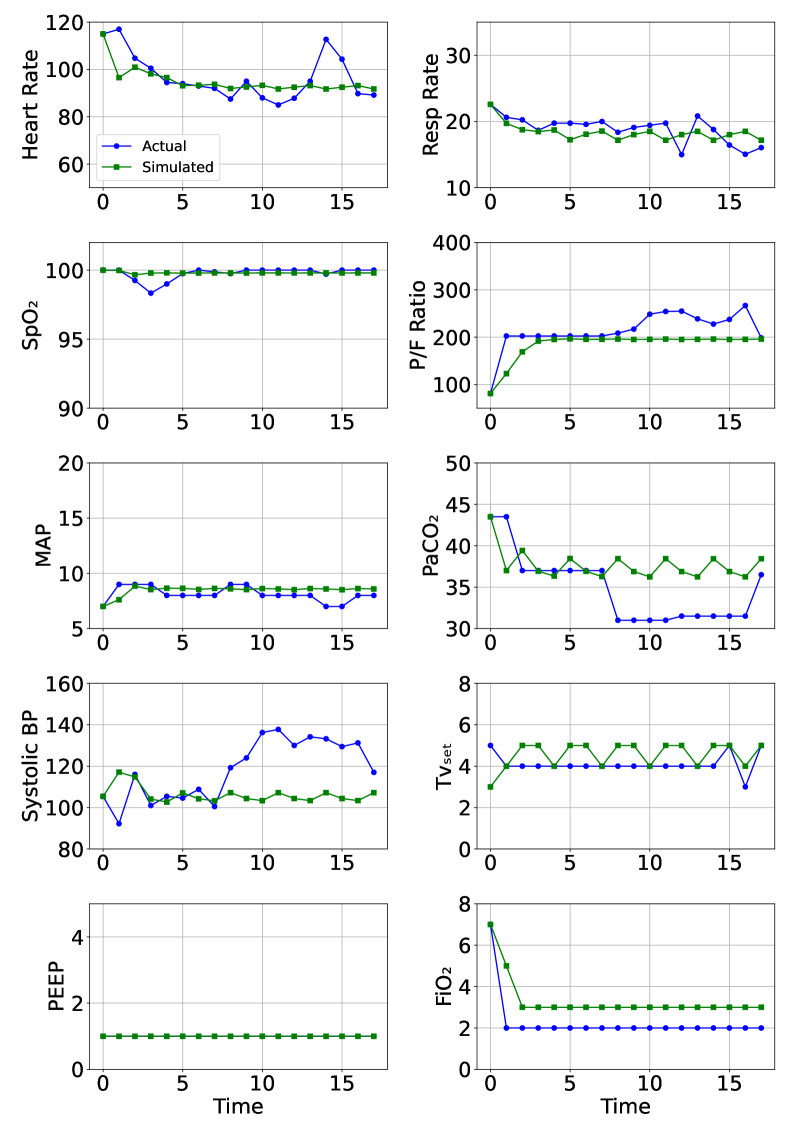
The authors evaluated their approach using simulated ventilation scenarios. They compared the performance of the reinforcement learning agent against standard ventilation protocols, and found that the agent was able to achieve better outcomes, such as faster weaning from mechanical ventilation and lower rates of ventilator-associated complications.
The interpretability of the agent's decision-making was also assessed, showing that the provided explanations aligned with clinical knowledge and helped clinicians understand the reasoning behind the agent's actions.
Critical Analysis
The authors acknowledge several limitations and areas for future research. First, the experiments were conducted in a simulated environment, and further validation is needed to assess the approach's performance in real-world clinical settings.
Additionally, the reinforcement learning agent was trained on a specific set of ventilation scenarios, and its generalization to a wider range of patient conditions and ventilation strategies remains to be seen. The authors suggest incorporating more diverse training data and scenarios to address this limitation.
Another potential concern is the reliance on the accuracy and completeness of the simulation model used to train the agent. Discrepancies between the simulation and real-world ventilation dynamics could lead to suboptimal or even harmful actions by the agent.
Finally, the interpretability of the agent's decision-making, while a key strength of the approach, may be limited in its ability to fully capture the complex and nuanced clinical reasoning that experienced clinicians employ. Further research is needed to understand the extent to which the provided explanations can be effectively integrated into clinical decision-making.
Conclusion
This paper presents a promising methodology for using interpretable reinforcement learning to optimize mechanical ventilation. By developing an AI system that can autonomously adjust ventilator settings while providing explanations for its decisions, the authors aim to improve patient outcomes while maintaining clinician trust and oversight.
The simulation-based experiments demonstrate the potential of this approach, but additional validation in real-world clinical settings is needed. Addressing the identified limitations, such as improving generalization and accounting for the limitations of simulation models, will be crucial for the successful translation of this technology into clinical practice.
Overall, this research represents a significant step towards the development of intelligent, interpretable systems that can assist clinicians in providing more effective and personalized medical care, particularly in the critical domain of mechanical ventilation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏷️
Designing Interpretable ML System to Enhance Trust in Healthcare: A Systematic Review to Proposed Responsible Clinician-AI-Collaboration Framework
Elham Nasarian, Roohallah Alizadehsani, U. Rajendra Acharya, Kwok-Leung Tsui
0
0
This paper explores the significant impact of AI-based medical devices, including wearables, telemedicine, large language models, and digital twins, on clinical decision support systems. It emphasizes the importance of producing outcomes that are not only accurate but also interpretable and understandable to clinicians, addressing the risk that lack of interpretability poses in terms of mistrust and reluctance to adopt these technologies in healthcare. The paper reviews interpretable AI processes, methods, applications, and the challenges of implementation in healthcare, focusing on quality control to facilitate responsible communication between AI systems and clinicians. It breaks down the interpretability process into data pre-processing, model selection, and post-processing, aiming to foster a comprehensive understanding of the crucial role of a robust interpretability approach in healthcare and to guide future research in this area. with insights for creating responsible clinician-AI tools for healthcare, as well as to offer a deeper understanding of the challenges they might face. Our research questions, eligibility criteria and primary goals were identified using Preferred Reporting Items for Systematic reviews and Meta-Analyses guideline and PICO method; PubMed, Scopus and Web of Science databases were systematically searched using sensitive and specific search strings. In the end, 52 publications were selected for data extraction which included 8 existing reviews and 44 related experimental studies. The paper offers general concepts of interpretable AI in healthcare and discuss three-levels interpretability process. Additionally, it provides a comprehensive discussion of evaluating robust interpretability AI in healthcare. Moreover, this survey introduces a step-by-step roadmap for implementing responsible AI in healthcare.
4/11/2024

Contextualized Policy Recovery: Modeling and Interpreting Medical Decisions with Adaptive Imitation Learning
Jannik Deuschel, Caleb N. Ellington, Yingtao Luo, Benjamin J. Lengerich, Pascal Friederich, Eric P. Xing
0
0
Interpretable policy learning seeks to estimate intelligible decision policies from observed actions; however, existing models force a tradeoff between accuracy and interpretability, limiting data-driven interpretations of human decision-making processes. Fundamentally, existing approaches are burdened by this tradeoff because they represent the underlying decision process as a universal policy, when in fact human decisions are dynamic and can change drastically under different contexts. Thus, we develop Contextualized Policy Recovery (CPR), which re-frames the problem of modeling complex decision processes as a multi-task learning problem, where each context poses a unique task and complex decision policies can be constructed piece-wise from many simple context-specific policies. CPR models each context-specific policy as a linear map, and generates new policy models $textit{on-demand}$ as contexts are updated with new observations. We provide two flavors of the CPR framework: one focusing on exact local interpretability, and one retaining full global interpretability. We assess CPR through studies on simulated and real data, achieving state-of-the-art performance on predicting antibiotic prescription in intensive care units ($+22%$ AUROC vs. previous SOTA) and predicting MRI prescription for Alzheimer's patients ($+7.7%$ AUROC vs. previous SOTA). With this improvement, CPR closes the accuracy gap between interpretable and black-box methods, allowing high-resolution exploration and analysis of context-specific decision models.
5/9/2024
🤿
An experimental evaluation of Deep Reinforcement Learning algorithms for HVAC control
Antonio Manjavacas, Alejandro Campoy-Nieves, Javier Jim'enez-Raboso, Miguel Molina-Solana, Juan G'omez-Romero
0
0
Heating, Ventilation, and Air Conditioning (HVAC) systems are a major driver of energy consumption in commercial and residential buildings. Recent studies have shown that Deep Reinforcement Learning (DRL) algorithms can outperform traditional reactive controllers. However, DRL-based solutions are generally designed for ad hoc setups and lack standardization for comparison. To fill this gap, this paper provides a critical and reproducible evaluation, in terms of comfort and energy consumption, of several state-of-the-art DRL algorithms for HVAC control. The study examines the controllers' robustness, adaptability, and trade-off between optimization goals by using the Sinergym framework. The results obtained confirm the potential of DRL algorithms, such as SAC and TD3, in complex scenarios and reveal several challenges related to generalization and incremental learning.
4/11/2024

Autonomous navigation of catheters and guidewires in mechanical thrombectomy using inverse reinforcement learning
Harry Robertshaw, Lennart Karstensen, Benjamin Jackson, Alejandro Granados, Thomas C. Booth
0
0
Purpose: Autonomous navigation of catheters and guidewires can enhance endovascular surgery safety and efficacy, reducing procedure times and operator radiation exposure. Integrating tele-operated robotics could widen access to time-sensitive emergency procedures like mechanical thrombectomy (MT). Reinforcement learning (RL) shows potential in endovascular navigation, yet its application encounters challenges without a reward signal. This study explores the viability of autonomous navigation in MT vasculature using inverse RL (IRL) to leverage expert demonstrations. Methods: This study established a simulation-based training and evaluation environment for MT navigation. We used IRL to infer reward functions from expert behaviour when navigating a guidewire and catheter. We utilized soft actor-critic to train models with various reward functions and compared their performance in silico. Results: We demonstrated feasibility of navigation using IRL. When evaluating single versus dual device (i.e. guidewire versus catheter and guidewire) tracking, both methods achieved high success rates of 95% and 96%, respectively. Dual-tracking, however, utilized both devices mimicking an expert. A success rate of 100% and procedure time of 22.6 s were obtained when training with a reward function obtained through reward shaping. This outperformed a dense reward function (96%, 24.9 s) and an IRL-derived reward function (48%, 59.2 s). Conclusions: We have contributed to the advancement of autonomous endovascular intervention navigation, particularly MT, by employing IRL. The results underscore the potential of using reward shaping to train models, offering a promising avenue for enhancing the accessibility and precision of MT. We envisage that future research can extend our methodology to diverse anatomical structures to enhance generalizability.
6/19/2024