Metric Learning from Limited Pairwise Preference Comparisons

0

Sign in to get full access
Overview
- This paper explores a novel approach to metric learning using limited pairwise preference comparisons.
- The proposed method can learn effective distance metrics from sparse and imprecise feedback, which is a common scenario in real-world applications.
- The authors introduce a computationally efficient algorithm that outperforms existing metric learning techniques, particularly in settings with limited training data.
Plain English Explanation
The paper focuses on a machine learning problem called "metric learning." In metric learning, the goal is to automatically learn a good way to measure the distance or similarity between different data points. This is an important task that has many applications, such as image retrieval, recommendation systems, and clustering.
Traditional metric learning methods often require large amounts of carefully labeled training data, where the relationships between data points are precisely specified. However, in many real-world scenarios, we only have access to limited and imprecise feedback, such as pairwise preferences (e.g., "item A is more similar to item B than item C").
The researchers in this paper developed a new algorithm that can effectively learn distance metrics from this type of sparse and noisy preference data. Their approach is computationally efficient and outperforms existing metric learning techniques, especially when the available training data is limited.
This is an important contribution because it allows for the use of metric learning in a wider range of applications where precise labels are difficult or expensive to obtain. By leveraging more readily available pairwise preferences, the algorithm can learn meaningful distance metrics that can improve the performance of various machine learning tasks.
Technical Explanation
The authors propose a novel metric learning framework called "Compressive Mahalanobis Metric Learning" (CMML) that can effectively learn distance metrics from limited pairwise preference comparisons. The key idea is to formulate the metric learning problem as a low-rank matrix recovery task, which can be solved efficiently using convex optimization techniques.
The CMML algorithm works by learning a Mahalanobis distance metric that best explains the observed pairwise preferences, while also encouraging the metric to have a low-rank structure. This allows the method to adapt to the intrinsic dimensionality of the data, even when the available training data is sparse and noisy.
The authors conduct extensive experiments on various benchmark datasets and show that CMML outperforms state-of-the-art metric learning approaches, particularly in settings with limited training data. They also provide theoretical analysis and demonstrate the algorithm's scalability and robustness to different types of preference feedback.
Critical Analysis
The paper presents a compelling and well-designed approach to metric learning from limited pairwise preference data. The authors have carefully addressed several key challenges in this domain, such as the ability to learn meaningful metrics from sparse and noisy feedback, and the need for computationally efficient algorithms that can scale to large-scale problems.
One potential limitation of the CMML method is that it assumes the underlying data has a low-rank structure, which may not always be the case in real-world applications. The authors acknowledge this and suggest that extensions to handle more general data structures could be an interesting direction for future research.
Additionally, while the paper provides extensive experimental evaluation, it would be valuable to see more real-world case studies demonstrating the practical impact of the proposed method in specific application domains. This could help to further validate the usefulness of the CMML algorithm and inspire other researchers to explore similar approaches.
Conclusion
This paper introduces a novel metric learning framework called Compressive Mahalanobis Metric Learning (CMML) that can effectively learn distance metrics from limited pairwise preference comparisons. The authors demonstrate the effectiveness of their approach through extensive experiments and provide theoretical analysis to support the algorithm's properties.
The CMML method represents an important advancement in the field of metric learning, as it allows for the use of this powerful technique in a wider range of scenarios where precise labeled data is scarce. By leveraging more readily available pairwise feedback, the algorithm can learn meaningful distance metrics that can improve the performance of various machine learning tasks.
The paper's contribution is particularly significant given the ubiquity of metric learning in many real-world applications, such as image retrieval, recommendation systems, and clustering. The CMML algorithm's ability to learn effective metrics from limited data has the potential to unlock new opportunities for the application of metric learning in a variety of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Metric Learning from Limited Pairwise Preference Comparisons
Zhi Wang, Geelon So, Ramya Korlakai Vinayak
We study metric learning from preference comparisons under the ideal point model, in which a user prefers an item over another if it is closer to their latent ideal item. These items are embedded into $mathbb{R}^d$ equipped with an unknown Mahalanobis distance shared across users. While recent work shows that it is possible to simultaneously recover the metric and ideal items given $mathcal{O}(d)$ pairwise comparisons per user, in practice we often have a limited budget of $o(d)$ comparisons. We study whether the metric can still be recovered, even though it is known that learning individual ideal items is now no longer possible. We show that in general, $o(d)$ comparisons reveal no information about the metric, even with infinitely many users. However, when comparisons are made over items that exhibit low-dimensional structure, each user can contribute to learning the metric restricted to a low-dimensional subspace so that the metric can be jointly identified. We present a divide-and-conquer approach that achieves this, and provide theoretical recovery guarantees and empirical validation.
Read more7/15/2024
📉
0
Compressive Mahalanobis Metric Learning Adapts to Intrinsic Dimension
Efstratios Palias, Ata Kab'an
Metric learning aims at finding a suitable distance metric over the input space, to improve the performance of distance-based learning algorithms. In high-dimensional settings, it can also serve as dimensionality reduction by imposing a low-rank restriction to the learnt metric. In this paper, we consider the problem of learning a Mahalanobis metric, and instead of training a low-rank metric on high-dimensional data, we use a randomly compressed version of the data to train a full-rank metric in this reduced feature space. We give theoretical guarantees on the error for Mahalanobis metric learning, which depend on the stable dimension of the data support, but not on the ambient dimension. Our bounds make no assumptions aside from i.i.d. data sampling from a bounded support, and automatically tighten when benign geometrical structures are present. An important ingredient is an extension of Gordon's theorem, which may be of independent interest. We also corroborate our findings by numerical experiments.
Read more4/16/2024
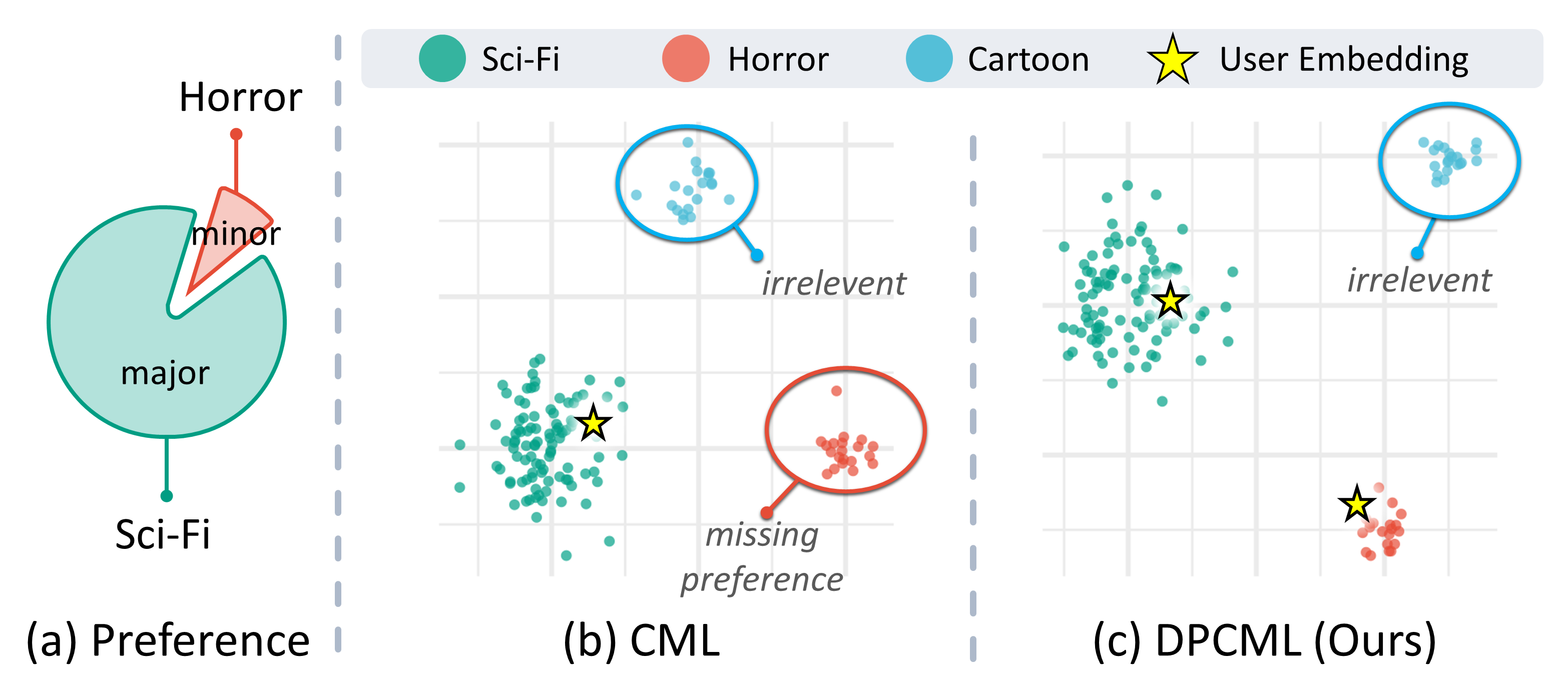
0
Improved Diversity-Promoting Collaborative Metric Learning for Recommendation
Shilong Bao, Qianqian Xu, Zhiyong Yang, Yuan He, Xiaochun Cao, Qingming Huang
Collaborative Metric Learning (CML) has recently emerged as a popular method in recommendation systems (RS), closing the gap between metric learning and collaborative filtering. Following the convention of RS, existing practices exploit unique user representation in their model design. This paper focuses on a challenging scenario where a user has multiple categories of interests. Under this setting, the unique user representation might induce preference bias, especially when the item category distribution is imbalanced. To address this issue, we propose a novel method called textit{Diversity-Promoting Collaborative Metric Learning} (DPCML), with the hope of considering the commonly ignored minority interest of the user. The key idea behind DPCML is to introduce a set of multiple representations for each user in the system where users' preference toward an item is aggregated by taking the minimum item-user distance among their embedding set. Specifically, we instantiate two effective assignment strategies to explore a proper quantity of vectors for each user. Meanwhile, a textit{Diversity Control Regularization Scheme} (DCRS) is developed to accommodate the multi-vector representation strategy better. Theoretically, we show that DPCML could induce a smaller generalization error than traditional CML. Furthermore, we notice that CML-based approaches usually require textit{negative sampling} to reduce the heavy computational burden caused by the pairwise objective therein. In this paper, we reveal the fundamental limitation of the widely adopted hard-aware sampling from the One-Way Partial AUC (OPAUC) perspective and then develop an effective sampling alternative for the CML-based paradigm. Finally, comprehensive experiments over a range of benchmark datasets speak to the efficacy of DPCML. Code are available at url{https://github.com/statusrank/LibCML}.
Read more9/4/2024
👨🏫
0
Fine-grained analysis of non-parametric estimation for pairwise learning
Junyu Zhou, Shuo Huang, Han Feng, Puyu Wang, Ding-Xuan Zhou
In this paper, we are concerned with the generalization performance of non-parametric estimation for pairwise learning. Most of the existing work requires the hypothesis space to be convex or a VC-class, and the loss to be convex. However, these restrictive assumptions limit the applicability of the results in studying many popular methods, especially kernel methods and neural networks. We significantly relax these restrictive assumptions and establish a sharp oracle inequality of the empirical minimizer with a general hypothesis space for the Lipschitz continuous pairwise losses. Our results can be used to handle a wide range of pairwise learning problems including ranking, AUC maximization, pairwise regression, and metric and similarity learning. As an application, we apply our general results to study pairwise least squares regression and derive an excess generalization bound that matches the minimax lower bound for pointwise least squares regression up to a logrithmic term. The key novelty here is to construct a structured deep ReLU neural network as an approximation of the true predictor and design the targeted hypothesis space consisting of the structured networks with controllable complexity. This successful application demonstrates that the obtained general results indeed help us to explore the generalization performance on a variety of problems that cannot be handled by existing approaches.
Read more6/24/2024