Mimicry and the Emergence of Cooperative Communication
2405.16622
0
0
Abstract
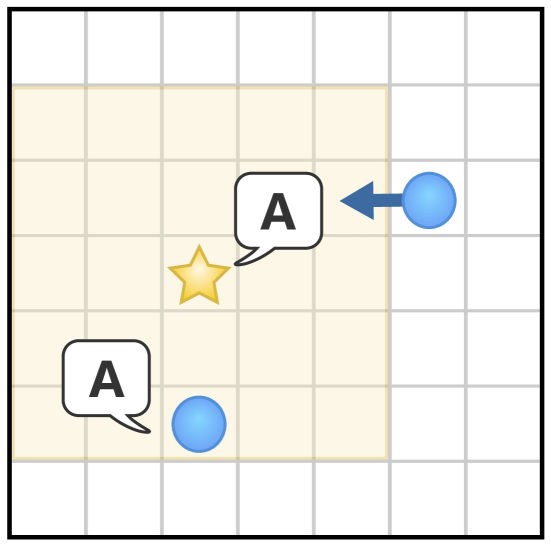
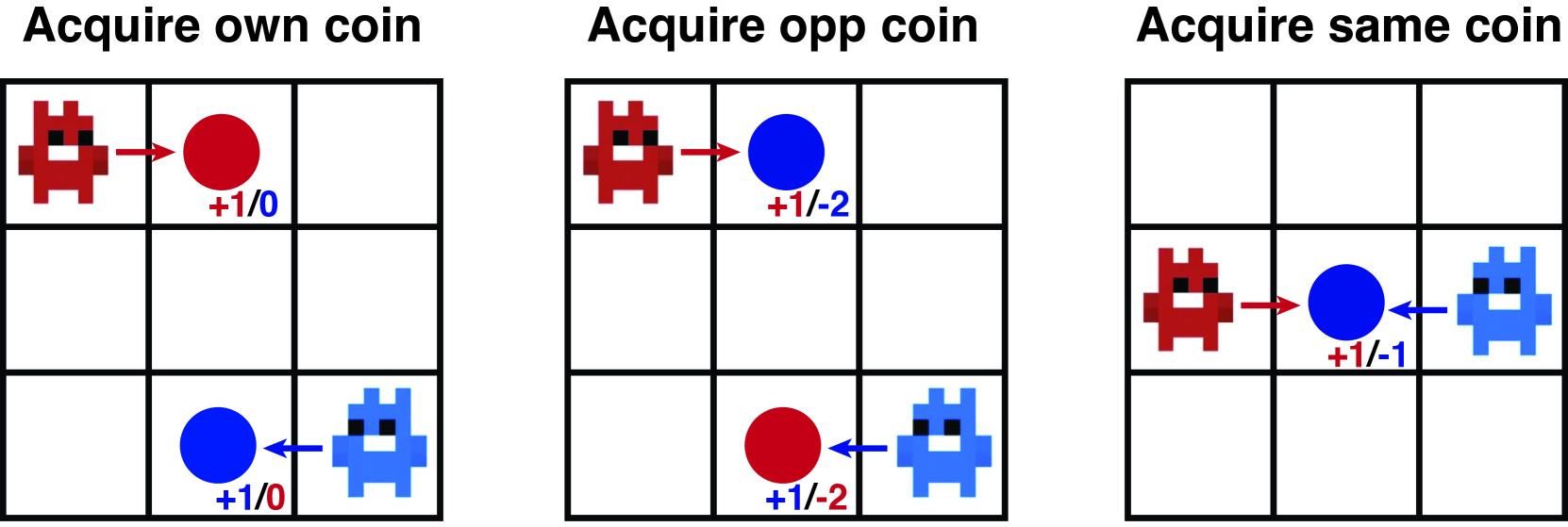
In many situations, communication between agents is a critical component of cooperative multi-agent systems, however, it can be difficult to learn or evolve. In this paper, we investigate a simple way in which the emergence of communication may be facilitated. Namely, we explore the effects of when agents can mimic preexisting, externally generated useful signals. The key idea here is that these signals incentivise listeners to develop positive responses, that can then also be invoked by speakers mimicking those signals. This investigation starts with formalising this problem, and demonstrating that this form of mimicry changes optimisation dynamics and may provide the opportunity to escape non-communicative local optima. We then explore the problem empirically with a simulation in which spatially situated agents must communicate to collect resources. Our results show that both evolutionary optimisation and reinforcement learning may benefit from this intervention.
Create account to get full access
Overview
- The paper explores the role of mimicry in the emergence of cooperative communication between agents.
- It investigates how mimicry can facilitate the development of shared communication strategies and cooperation in multi-agent systems.
- The research aims to provide insights into the evolution of communication and cooperation in natural and artificial systems.
Plain English Explanation
Mimicry, or the act of copying the behaviors of others, is a common phenomenon in both human and animal interactions. The paper suggests that this ability to mimic others may play a crucial role in the development of cooperative communication between agents.
[In this context, an "agent" could refer to a human, animal, or even an artificial intelligence system like a chatbot or robot.] By observing and imitating the communication patterns of others, agents may be able to establish a shared understanding and build cooperative relationships. This could be particularly important in multi-agent systems, where multiple entities need to coordinate their actions and exchange information effectively.
The research explores how mimicry can help agents converge on common communication strategies, which in turn can foster cooperation and achieve better outcomes for the group. The findings could have implications for fields like [link to "https://aimodels.fyi/papers/arxiv/learning-multi-agent-communication-from-graph-modeling"](multi-agent systems), [link to "https://aimodels.fyi/papers/arxiv/enhancing-cooperation-through-selective-interaction-long-term"](cooperation in multi-agent systems), [link to "https://aimodels.fyi/papers/arxiv/verco-learning-coordinated-verbal-communication-multi-agent"](coordinated communication in multi-agent systems), and [link to "https://aimodels.fyi/papers/arxiv/power-communication-power-regularization-communication-autonomy-cooperative"](the balance between communication and autonomy in cooperative systems).
Technical Explanation
The paper proposes a model that investigates the role of mimicry in the emergence of cooperative communication between agents. The researchers design a multi-agent simulation environment where agents can observe and imitate each other's communication patterns.
[link to "https://aimodels.fyi/papers/arxiv/learning-multi-agent-communication-from-graph-modeling"]The agents are equipped with neural networks that allow them to learn how to communicate and cooperate over time. The researchers analyze how the agents' ability to mimic each other affects the development of shared communication strategies and the overall level of cooperation within the system.
The results suggest that mimicry can indeed facilitate the emergence of cooperative communication. Agents that are able to observe and imitate each other's communication patterns are more likely to converge on a common communication strategy, which in turn enables them to coordinate their actions and achieve better collective outcomes.
[link to "https://aimodels.fyi/papers/arxiv/enhancing-cooperation-through-selective-interaction-long-term"]The paper also explores how the frequency and duration of interactions between agents can impact the effectiveness of mimicry-based communication. Agents that engage in selective and long-term interactions are found to be more successful in establishing cooperative communication compared to those with more random or short-lived interactions.
[link to "https://aimodels.fyi/papers/arxiv/verco-learning-coordinated-verbal-communication-multi-agent"]Furthermore, the researchers investigate the interplay between verbal and non-verbal communication, and how these different modalities can be combined to enhance cooperation. They find that agents that can learn to coordinate both verbal and non-verbal cues are able to establish more robust and effective communication strategies.
[link to "https://aimodels.fyi/papers/arxiv/power-communication-power-regularization-communication-autonomy-cooperative"]Finally, the paper discusses the balance between communication and autonomy in cooperative systems, and how the degree of communication control can affect the overall performance of the system.
Critical Analysis
The paper provides a valuable contribution to the understanding of how mimicry can facilitate the emergence of cooperative communication in multi-agent systems. The simulation-based approach allows the researchers to isolate and study the specific mechanisms underlying this phenomenon, which is difficult to observe in real-world settings.
However, the paper does acknowledge several limitations of the study. The simulated environment may not fully capture the complexity of real-world communication and cooperation, and the results may not translate directly to more complex or heterogeneous systems. Additionally, the paper suggests that further research is needed to explore the long-term implications of mimicry-based communication and its potential impact on the evolution of cooperation over time.
[link to "https://aimodels.fyi/papers/arxiv/human-agent-cooperation-games-under-incomplete-information"]Another potential area for further investigation is the interplay between human and artificial agents in cooperative communication tasks. Understanding how mimicry-based communication strategies might translate to human-agent interactions could provide valuable insights for the design of more effective and natural communication interfaces.
Conclusion
The paper offers compelling evidence that mimicry can play a crucial role in the emergence of cooperative communication between agents. By enabling agents to converge on shared communication strategies, mimicry can facilitate the development of effective coordination and cooperation, which has important implications for a wide range of multi-agent systems.
The findings of this research could contribute to advancements in fields such as [link to "https://aimodels.fyi/papers/arxiv/learning-multi-agent-communication-from-graph-modeling"](multi-agent systems), [link to "https://aimodels.fyi/papers/arxiv/enhancing-cooperation-through-selective-interaction-long-term"](cooperative multi-agent systems), and [link to "https://aimodels.fyi/papers/arxiv/verco-learning-coordinated-verbal-communication-multi-agent"](coordinated communication in multi-agent systems), ultimately leading to the design of more effective and adaptive communication and cooperation strategies in both natural and artificial systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
Learning Multi-Agent Communication from Graph Modeling Perspective
Shengchao Hu, Li Shen, Ya Zhang, Dacheng Tao
0
0
In numerous artificial intelligence applications, the collaborative efforts of multiple intelligent agents are imperative for the successful attainment of target objectives. To enhance coordination among these agents, a distributed communication framework is often employed. However, information sharing among all agents proves to be resource-intensive, while the adoption of a manually pre-defined communication architecture imposes limitations on inter-agent communication, thereby constraining the potential for collaborative efforts. In this study, we introduce a novel approach wherein we conceptualize the communication architecture among agents as a learnable graph. We formulate this problem as the task of determining the communication graph while enabling the architecture parameters to update normally, thus necessitating a bi-level optimization process. Utilizing continuous relaxation of the graph representation and incorporating attention units, our proposed approach, CommFormer, efficiently optimizes the communication graph and concurrently refines architectural parameters through gradient descent in an end-to-end manner. Extensive experiments on a variety of cooperative tasks substantiate the robustness of our model across diverse cooperative scenarios, where agents are able to develop more coordinated and sophisticated strategies regardless of changes in the number of agents.
5/15/2024
Reciprocal Reward Influence Encourages Cooperation From Self-Interested Agents
John L. Zhou, Weizhe Hong, Jonathan C. Kao
0
0
Emergent cooperation among self-interested individuals is a widespread phenomenon in the natural world, but remains elusive in interactions between artificially intelligent agents. Instead, naive reinforcement learning algorithms typically converge to Pareto-dominated outcomes in even the simplest of social dilemmas. An emerging class of opponent-shaping methods have demonstrated the ability to reach prosocial outcomes by influencing the learning of other agents. However, they rely on higher-order derivatives through the predicted learning step of other agents or learning meta-game dynamics, which in turn rely on stringent assumptions over opponent learning rules or exponential sample complexity, respectively. To provide a learning rule-agnostic and sample-efficient alternative, we introduce Reciprocators, reinforcement learning agents which are intrinsically motivated to reciprocate the influence of an opponent's actions on their returns. This approach effectively seeks to modify other agents' $Q$-values by increasing their return following beneficial actions (with respect to the Reciprocator) and decreasing it after detrimental actions, guiding them towards mutually beneficial actions without attempting to directly shape policy updates. We show that Reciprocators can be used to promote cooperation in a variety of temporally extended social dilemmas during simultaneous learning.
6/5/2024
Enhancing Cooperation through Selective Interaction and Long-term Experiences in Multi-Agent Reinforcement Learning
Tianyu Ren, Xiao-Jun Zeng
0
0
The significance of network structures in promoting group cooperation within social dilemmas has been widely recognized. Prior studies attribute this facilitation to the assortment of strategies driven by spatial interactions. Although reinforcement learning has been employed to investigate the impact of dynamic interaction on the evolution of cooperation, there remains a lack of understanding about how agents develop neighbour selection behaviours and the formation of strategic assortment within an explicit interaction structure. To address this, our study introduces a computational framework based on multi-agent reinforcement learning in the spatial Prisoner's Dilemma game. This framework allows agents to select dilemma strategies and interacting neighbours based on their long-term experiences, differing from existing research that relies on preset social norms or external incentives. By modelling each agent using two distinct Q-networks, we disentangle the coevolutionary dynamics between cooperation and interaction. The results indicate that long-term experience enables agents to develop the ability to identify non-cooperative neighbours and exhibit a preference for interaction with cooperative ones. This emergent self-organizing behaviour leads to the clustering of agents with similar strategies, thereby increasing network reciprocity and enhancing group cooperation.
5/7/2024

Verco: Learning Coordinated Verbal Communication for Multi-agent Reinforcement Learning
Dapeng Li, Hang Dong, Lu Wang, Bo Qiao, Si Qin, Qingwei Lin, Dongmei Zhang, Qi Zhang, Zhiwei Xu, Bin Zhang, Guoliang Fan
0
0
In recent years, multi-agent reinforcement learning algorithms have made significant advancements in diverse gaming environments, leading to increased interest in the broader application of such techniques. To address the prevalent challenge of partial observability, communication-based algorithms have improved cooperative performance through the sharing of numerical embedding between agents. However, the understanding of the formation of collaborative mechanisms is still very limited, making designing a human-understandable communication mechanism a valuable problem to address. In this paper, we propose a novel multi-agent reinforcement learning algorithm that embeds large language models into agents, endowing them with the ability to generate human-understandable verbal communication. The entire framework has a message module and an action module. The message module is responsible for generating and sending verbal messages to other agents, effectively enhancing information sharing among agents. To further enhance the message module, we employ a teacher model to generate message labels from the global view and update the student model through Supervised Fine-Tuning (SFT). The action module receives messages from other agents and selects actions based on current local observations and received messages. Experiments conducted on the Overcooked game demonstrate our method significantly enhances the learning efficiency and performance of existing methods, while also providing an interpretable tool for humans to understand the process of multi-agent cooperation.
4/30/2024