Mind's Eye: Image Recognition by EEG via Multimodal Similarity-Keeping Contrastive Learning
2406.16910
0
0
Abstract
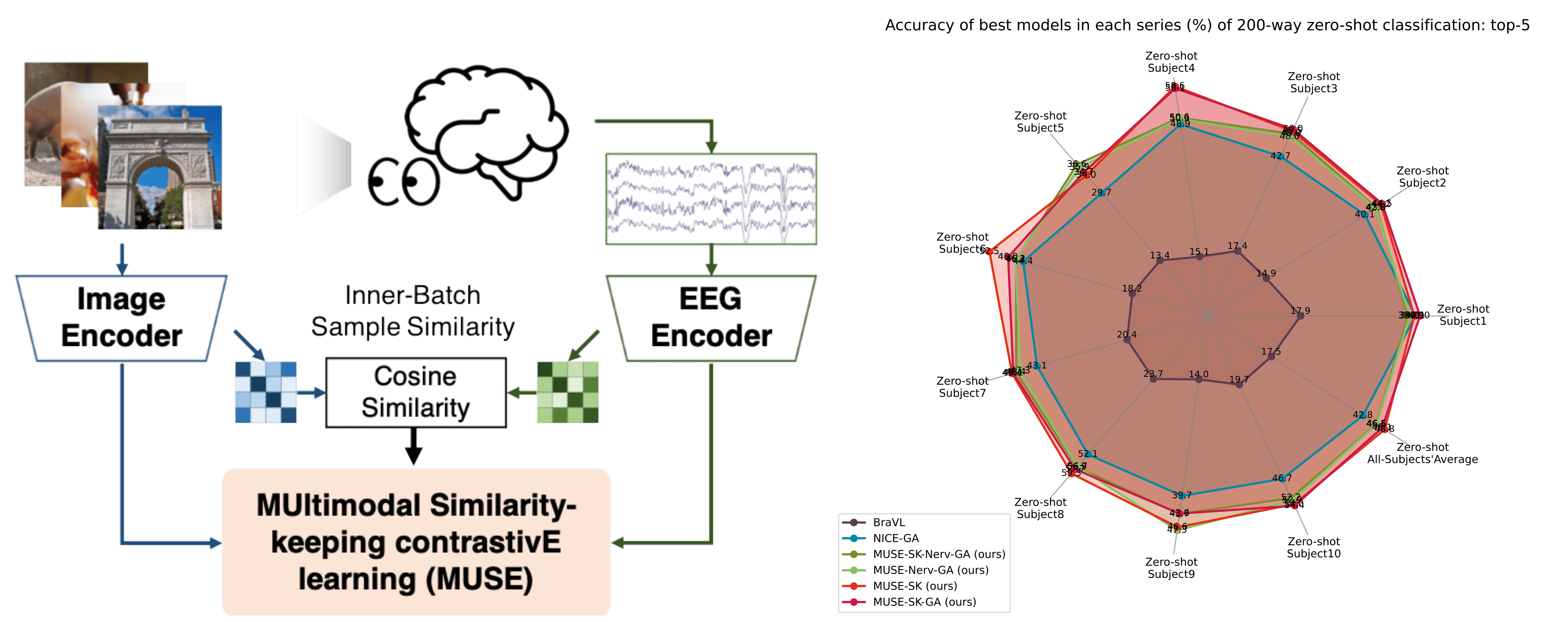
Decoding images from non-invasive electroencephalographic (EEG) signals has been a grand challenge in understanding how the human brain process visual information in real-world scenarios. To cope with the issues of signal-to-noise ratio and nonstationarity, this paper introduces a MUltimodal Similarity-keeping contrastivE learning (MUSE) framework for zero-shot EEG-based image classification. We develop a series of multivariate time-series encoders tailored for EEG signals and assess the efficacy of regularized contrastive EEG-Image pretraining using an extensive visual EEG dataset. Our method achieves state-of-the-art performance, with a top-1 accuracy of 19.3% and a top-5 accuracy of 48.8% in 200-way zero-shot image classification. Furthermore, we visualize neural patterns via model interpretation, shedding light on the visual processing dynamics in the human brain. The code repository for this work is available at: https://github.com/ChiShengChen/MUSE_EEG.
Create account to get full access
Overview
• This paper presents a novel approach to image recognition using electroencephalography (EEG) data and multimodal contrastive learning.
• The researchers developed a system that can accurately identify the images a person is viewing based on their brain activity, captured through EEG sensors.
• The key innovation is the use of multimodal contrastive learning, which allows the model to learn shared representations between visual and neural data, enabling effective image recognition from EEG signals.
Plain English Explanation
The paper describes a system that can figure out what image a person is looking at just by looking at their brain activity. The researchers used a technique called "multimodal contrastive learning" to train their model. This allows the model to learn the connections between what the person is seeing (the image) and what's happening in their brain (the EEG data).
By learning these connections, the model can then take a person's brain activity and use it to identify the image they're looking at. This could be really useful for things like brain-computer interfaces or assistive technology for people with disabilities. Instead of having to use a mouse or keyboard, they could potentially control a computer just by thinking about what they want to do.
The key advantage of this approach is that it can work with just the brain activity data, without needing any other information about the person or the image. This makes it more flexible and potentially more accessible than other image recognition systems that require more data or specialized equipment.
Technical Explanation
The paper proposes a novel multimodal contrastive learning framework for decoding images from EEG signals. The core idea is to learn a shared embedding space between visual and neural data, where semantically similar images and their corresponding EEG patterns are closer together.
The authors develop a two-stream neural network architecture, with one stream processing the visual data and the other processing the EEG data. These streams are trained using a contrastive loss function that encourages the model to pull together instances with the same class label (i.e., the same image) while pushing apart instances with different class labels.
Importantly, the contrastive loss is applied not just within a single modality (e.g., image-image or EEG-EEG), but also across modalities (image-EEG). This allows the model to learn a multimodal embedding space where visual and neural representations of the same object are closely aligned.
The authors evaluate their approach on several EEG-based image recognition benchmarks, including [decoding-natural-images-from-eeg-object-recognition], [visual-decoding-reconstruction-via-eeg-embeddings-guided], and [eeg-imagenet-electroencephalogram-dataset-benchmarks-image-visual]. They demonstrate state-of-the-art performance, outperforming previous methods that do not leverage the power of multimodal contrastive learning.
Critical Analysis
The paper presents a well-designed and thorough study, with rigorous experiments and a solid technical foundation. The use of multimodal contrastive learning is a clever and effective way to bridge the gap between visual and neural data, allowing for more accurate image recognition from EEG signals.
However, the authors acknowledge several limitations of their approach. For example, the system's performance may be influenced by factors like the number and placement of EEG electrodes, as well as the specific task and dataset used. Additionally, the paper does not address potential privacy concerns around the use of brain data for image recognition.
Further research could explore ways to make the system more robust and scalable, such as by incorporating techniques from [multi-modal-mood-reader-pre-trained-model] or [supervised-information-enhanced-multi-granularity-contrastive-learning]. Investigating the interpretability of the learned multimodal representations could also be a fruitful avenue for future work.
Conclusion
This paper introduces a novel approach to image recognition using EEG data and multimodal contrastive learning. By learning a shared embedding space between visual and neural representations, the model can effectively decode images from brain activity alone, with state-of-the-art performance on relevant benchmarks.
The work has significant implications for brain-computer interfaces, assistive technology, and our understanding of the neural mechanisms underlying visual perception. As the field of neural decoding continues to advance, research like this will play a crucial role in unlocking the full potential of this technology for the benefit of society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌿
Decoding Natural Images from EEG for Object Recognition
Yonghao Song, Bingchuan Liu, Xiang Li, Nanlin Shi, Yijun Wang, Xiaorong Gao
0
0
Electroencephalography (EEG) signals, known for convenient non-invasive acquisition but low signal-to-noise ratio, have recently gained substantial attention due to the potential to decode natural images. This paper presents a self-supervised framework to demonstrate the feasibility of learning image representations from EEG signals, particularly for object recognition. The framework utilizes image and EEG encoders to extract features from paired image stimuli and EEG responses. Contrastive learning aligns these two modalities by constraining their similarity. With the framework, we attain significantly above-chance results on a comprehensive EEG-image dataset, achieving a top-1 accuracy of 15.6% and a top-5 accuracy of 42.8% in challenging 200-way zero-shot tasks. Moreover, we perform extensive experiments to explore the biological plausibility by resolving the temporal, spatial, spectral, and semantic aspects of EEG signals. Besides, we introduce attention modules to capture spatial correlations, providing implicit evidence of the brain activity perceived from EEG data. These findings yield valuable insights for neural decoding and brain-computer interfaces in real-world scenarios. The code will be released on https://github.com/eeyhsong/NICE-EEG.
4/5/2024
Visual Decoding and Reconstruction via EEG Embeddings with Guided Diffusion
Dongyang Li, Chen Wei, Shiying Li, Jiachen Zou, Quanying Liu
0
0
How to decode human vision through neural signals has attracted a long-standing interest in neuroscience and machine learning. Modern contrastive learning and generative models improved the performance of fMRI-based visual decoding and reconstruction. However, the high cost and low temporal resolution of fMRI limit their applications in brain-computer interfaces (BCIs), prompting a high need for EEG-based visual reconstruction. In this study, we present an EEG-based visual reconstruction framework. It consists of a plug-and-play EEG encoder called the Adaptive Thinking Mapper (ATM), which is aligned with image embeddings, and a two-stage EEG guidance image generator that first transforms EEG features into image priors and then reconstructs the visual stimuli with a pre-trained image generator. Our approach allows EEG embeddings to achieve superior performance in image classification and retrieval tasks. Our two-stage image generation strategy vividly reconstructs images seen by humans. Furthermore, we analyzed the impact of signals from different time windows and brain regions on decoding and reconstruction. The versatility of our framework is demonstrated in the magnetoencephalogram (MEG) data modality. We report that EEG-based visual decoding achieves SOTA performance, highlighting the portability, low cost, and high temporal resolution of EEG, enabling a wide range of BCI applications. The code of ATM is available at https://github.com/dongyangli-del/EEG_Image_decode.
4/8/2024

EEG-ImageNet: An Electroencephalogram Dataset and Benchmarks with Image Visual Stimuli of Multi-Granularity Labels
Shuqi Zhu, Ziyi Ye, Qingyao Ai, Yiqun Liu
0
0
Identifying and reconstructing what we see from brain activity gives us a special insight into investigating how the biological visual system represents the world. While recent efforts have achieved high-performance image classification and high-quality image reconstruction from brain signals collected by Functional Magnetic Resonance Imaging (fMRI) or magnetoencephalogram (MEG), the expensiveness and bulkiness of these devices make relevant applications difficult to generalize to practical applications. On the other hand, Electroencephalography (EEG), despite its advantages of ease of use, cost-efficiency, high temporal resolution, and non-invasive nature, has not been fully explored in relevant studies due to the lack of comprehensive datasets. To address this gap, we introduce EEG-ImageNet, a novel EEG dataset comprising recordings from 16 subjects exposed to 4000 images selected from the ImageNet dataset. EEG-ImageNet consists of 5 times EEG-image pairs larger than existing similar EEG benchmarks. EEG-ImageNet is collected with image stimuli of multi-granularity labels, i.e., 40 images with coarse-grained labels and 40 with fine-grained labels. Based on it, we establish benchmarks for object classification and image reconstruction. Experiments with several commonly used models show that the best models can achieve object classification with accuracy around 60% and image reconstruction with two-way identification around 64%. These results demonstrate the dataset's potential to advance EEG-based visual brain-computer interfaces, understand the visual perception of biological systems, and provide potential applications in improving machine visual models.
6/12/2024

Multi-modal Mood Reader: Pre-trained Model Empowers Cross-Subject Emotion Recognition
Yihang Dong, Xuhang Chen, Yanyan Shen, Michael Kwok-Po Ng, Tao Qian, Shuqiang Wang
0
0
Emotion recognition based on Electroencephalography (EEG) has gained significant attention and diversified development in fields such as neural signal processing and affective computing. However, the unique brain anatomy of individuals leads to non-negligible natural differences in EEG signals across subjects, posing challenges for cross-subject emotion recognition. While recent studies have attempted to address these issues, they still face limitations in practical effectiveness and model framework unity. Current methods often struggle to capture the complex spatial-temporal dynamics of EEG signals and fail to effectively integrate multimodal information, resulting in suboptimal performance and limited generalizability across subjects. To overcome these limitations, we develop a Pre-trained model based Multimodal Mood Reader for cross-subject emotion recognition that utilizes masked brain signal modeling and interlinked spatial-temporal attention mechanism. The model learns universal latent representations of EEG signals through pre-training on large scale dataset, and employs Interlinked spatial-temporal attention mechanism to process Differential Entropy(DE) features extracted from EEG data. Subsequently, a multi-level fusion layer is proposed to integrate the discriminative features, maximizing the advantages of features across different dimensions and modalities. Extensive experiments on public datasets demonstrate Mood Reader's superior performance in cross-subject emotion recognition tasks, outperforming state-of-the-art methods. Additionally, the model is dissected from attention perspective, providing qualitative analysis of emotion-related brain areas, offering valuable insights for affective research in neural signal processing.
5/31/2024