Mitigating Large Language Model Hallucination with Faithful Finetuning
2406.11267
0
0

Abstract
Large language models (LLMs) have demonstrated remarkable performance on various natural language processing tasks. However, they are prone to generating fluent yet untruthful responses, known as hallucinations. Hallucinations can lead to the spread of misinformation and cause harm in critical applications. Mitigating hallucinations is challenging as they arise from factors such as noisy data, model overconfidence, lack of knowledge, and the generation process itself. Recent efforts have attempted to address this issue through representation editing and decoding algorithms, reducing hallucinations without major structural changes or retraining. However, these approaches either implicitly edit LLMs' behavior in latent space or suppress the tendency to output unfaithful results during decoding instead of explicitly modeling on hallucination. In this work, we introduce Faithful Finetuning (F2), a novel method that explicitly models the process of faithful question answering through carefully designed loss functions during fine-tuning. We conduct extensive experiments on popular datasets and demonstrate that F2 achieves significant improvements over vanilla models and baselines.
Create account to get full access
Overview
- This paper explores techniques to mitigate hallucination in large language models (LLMs), which is the tendency of LLMs to generate plausible-sounding but factually incorrect information.
- The authors propose a "faithful finetuning" approach that aims to make LLMs more truthful and reliable by fine-tuning them on a combination of original and adversarial training data.
- The paper presents experimental results showing that faithful finetuning can improve the factual accuracy and truthfulness of LLM outputs compared to standard fine-tuning approaches.
Plain English Explanation
Large language models (LLMs) like GPT-3 are powerful AI systems that can generate human-like text on a wide range of topics. However, one major downside of these models is their tendency to "hallucinate" - to produce plausible-sounding text that is factually incorrect or nonsensical. This can be a significant problem when LLMs are used for tasks like question answering or content generation, where accuracy and truthfulness are crucial.
The researchers in this paper propose a new approach called "faithful finetuning" to address this issue. The key idea is to fine-tune the LLM not just on the original training data, but also on a mix of that data and "adversarial" examples - text snippets that are designed to trigger hallucinations in the model. By exposing the model to these adversarial examples during fine-tuning, the researchers hope to make it more robust and less prone to generating hallucinated outputs.
Through a series of experiments, the researchers show that this faithful finetuning approach can indeed improve the factual accuracy and truthfulness of the LLM's outputs, compared to standard fine-tuning techniques. This suggests that it may be a promising way to make LLMs more reliable and trustworthy, which could have important implications for their use in real-world applications.
Technical Explanation
The paper begins by discussing the problem of hallucination in large language models (LLMs) - the tendency of these models to generate plausible-sounding but factually incorrect text. The authors note that this is a significant challenge that has received increasing attention in the field of natural language processing.
To address this issue, the authors propose a new "faithful finetuning" approach. The key idea is to fine-tune the LLM not just on the original training data, but also on a mix of that data and "adversarial" examples - text snippets that are designed to trigger hallucinations in the model. By exposing the model to these adversarial examples during fine-tuning, the researchers hope to make it more robust and less prone to generating hallucinated outputs.
The paper presents a series of experiments evaluating the faithful finetuning approach on both language understanding and generation tasks. The results show that models fine-tuned with the faithful approach outperform those trained with standard fine-tuning in terms of factual accuracy and truthfulness of the generated outputs.
The authors also investigate the mechanisms underlying the faithful finetuning approach, exploring how it affects the model's internal representations and attention patterns. They find that the approach leads to more grounded and faithful representations, which in turn translate to more truthful and reliable model outputs.
Critical Analysis
The researchers in this paper have made a valuable contribution to the ongoing efforts to address the hallucination problem in large language models. Their faithful finetuning approach represents a promising step towards making these models more truthful and reliable.
That said, the paper does acknowledge some limitations and areas for further research. For example, the authors note that the faithful finetuning approach may be more effective for certain types of tasks or domains than others, and that more work is needed to understand the optimal way to generate and incorporate adversarial examples into the fine-tuning process.
Additionally, while the experiments presented in the paper demonstrate the effectiveness of faithful finetuning, it would be interesting to see how the approach compares to other recently proposed techniques for mitigating hallucination, such as those described in the papers Unfamiliar Fine-tuning Examples Control How Language Models Generalize, TruthX: Alleviating Hallucinations in Language Models via Editability, and Detecting and Mitigating Hallucination in Large Vision-Language Models.
Additionally, the authors could have engaged more deeply with the broader question of whether fine-tuning is the best approach for addressing hallucination, or whether other techniques like the ones discussed in Does Fine-tuning Large Language Models with New Knowledge Encourage Learning or Just Memorization? might be more effective.
Overall, this paper represents an important step forward in the quest to make large language models more truthful and reliable. The faithful finetuning approach is a compelling idea that deserves further exploration and refinement, and the researchers have made a valuable contribution to the ongoing efforts to address the hallucination problem in LLMs.
Conclusion
This paper presents a new "faithful finetuning" approach to mitigate hallucination in large language models (LLMs). The key idea is to fine-tune the LLM not just on the original training data, but also on a mix of that data and "adversarial" examples designed to trigger hallucinations in the model. Through a series of experiments, the researchers show that this approach can significantly improve the factual accuracy and truthfulness of the LLM's outputs compared to standard fine-tuning techniques.
The faithful finetuning approach represents a promising step towards making LLMs more reliable and trustworthy, which could have important implications for their use in real-world applications. While the paper acknowledges some limitations and areas for further research, it makes a valuable contribution to the ongoing efforts to address the hallucination problem in large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Unfamiliar Finetuning Examples Control How Language Models Hallucinate
Katie Kang, Eric Wallace, Claire Tomlin, Aviral Kumar, Sergey Levine
0
0
Large language models are known to hallucinate when faced with unfamiliar queries, but the underlying mechanism that govern how models hallucinate are not yet fully understood. In this work, we find that unfamiliar examples in the models' finetuning data -- those that introduce concepts beyond the base model's scope of knowledge -- are crucial in shaping these errors. In particular, we find that an LLM's hallucinated predictions tend to mirror the responses associated with its unfamiliar finetuning examples. This suggests that by modifying how unfamiliar finetuning examples are supervised, we can influence a model's responses to unfamiliar queries (e.g., say ``I don't know''). We empirically validate this observation in a series of controlled experiments involving SFT, RL, and reward model finetuning on TriviaQA and MMLU. Our work further investigates RL finetuning strategies for improving the factuality of long-form model generations. We find that, while hallucinations from the reward model can significantly undermine the effectiveness of RL factuality finetuning, strategically controlling how reward models hallucinate can minimize these negative effects. Leveraging our previous observations on controlling hallucinations, we propose an approach for learning more reliable reward models, and show that they improve the efficacy of RL factuality finetuning in long-form biography and book/movie plot generation tasks.
5/30/2024

TruthX: Alleviating Hallucinations by Editing Large Language Models in Truthful Space
Shaolei Zhang, Tian Yu, Yang Feng
0
0
Large Language Models (LLMs) sometimes suffer from producing hallucinations, especially LLMs may generate untruthful responses despite knowing the correct knowledge. Activating the truthfulness within LLM is the key to fully unlocking LLM's knowledge potential. In this paper, we propose TruthX, an inference-time intervention method to activate the truthfulness of LLM by identifying and editing the features within LLM's internal representations that govern the truthfulness. TruthX employs an auto-encoder to map LLM's representations into semantic and truthful latent spaces respectively, and applies contrastive learning to identify a truthful editing direction within the truthful space. During inference, by editing LLM's internal representations in truthful space, TruthX effectively enhances the truthfulness of LLM. Experiments show that TruthX improves the truthfulness of 13 advanced LLMs by an average of 20% on TruthfulQA benchmark. Further analyses suggest that TruthX can control LLM to produce truthful or hallucinatory responses via editing only one vector in LLM's internal representations.
6/6/2024
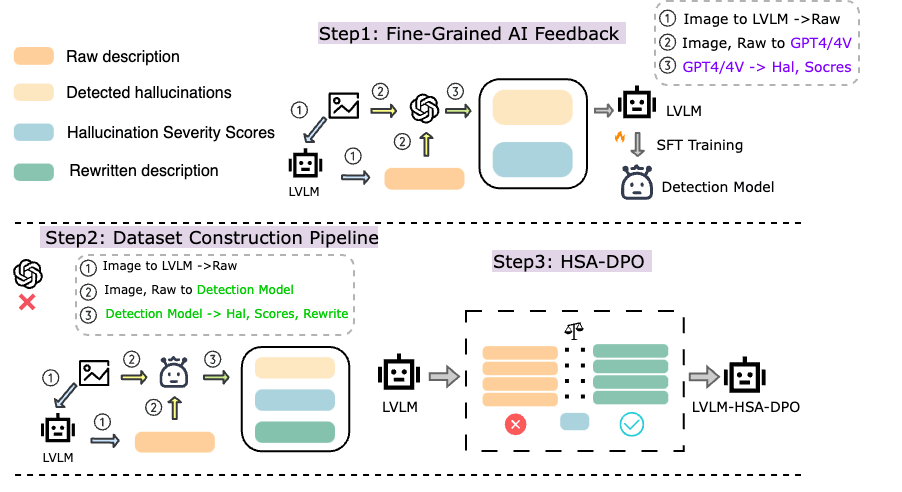
Detecting and Mitigating Hallucination in Large Vision Language Models via Fine-Grained AI Feedback
Wenyi Xiao, Ziwei Huang, Leilei Gan, Wanggui He, Haoyuan Li, Zhelun Yu, Hao Jiang, Fei Wu, Linchao Zhu
0
0
The rapidly developing Large Vision Language Models (LVLMs) have shown notable capabilities on a range of multi-modal tasks, but still face the hallucination phenomena where the generated texts do not align with the given contexts, significantly restricting the usages of LVLMs. Most previous work detects and mitigates hallucination at the coarse-grained level or requires expensive annotation (e.g., labeling by proprietary models or human experts). To address these issues, we propose detecting and mitigating hallucinations in LVLMs via fine-grained AI feedback. The basic idea is that we generate a small-size sentence-level hallucination annotation dataset by proprietary models, whereby we train a hallucination detection model which can perform sentence-level hallucination detection, covering primary hallucination types (i.e., object, attribute, and relationship). Then, we propose a detect-then-rewrite pipeline to automatically construct preference dataset for training hallucination mitigating model. Furthermore, we propose differentiating the severity of hallucinations, and introducing a Hallucination Severity-Aware Direct Preference Optimization (HSA-DPO) for mitigating hallucination in LVLMs by incorporating the severity of hallucinations into preference learning. Extensive experiments demonstrate the effectiveness of our method.
4/23/2024
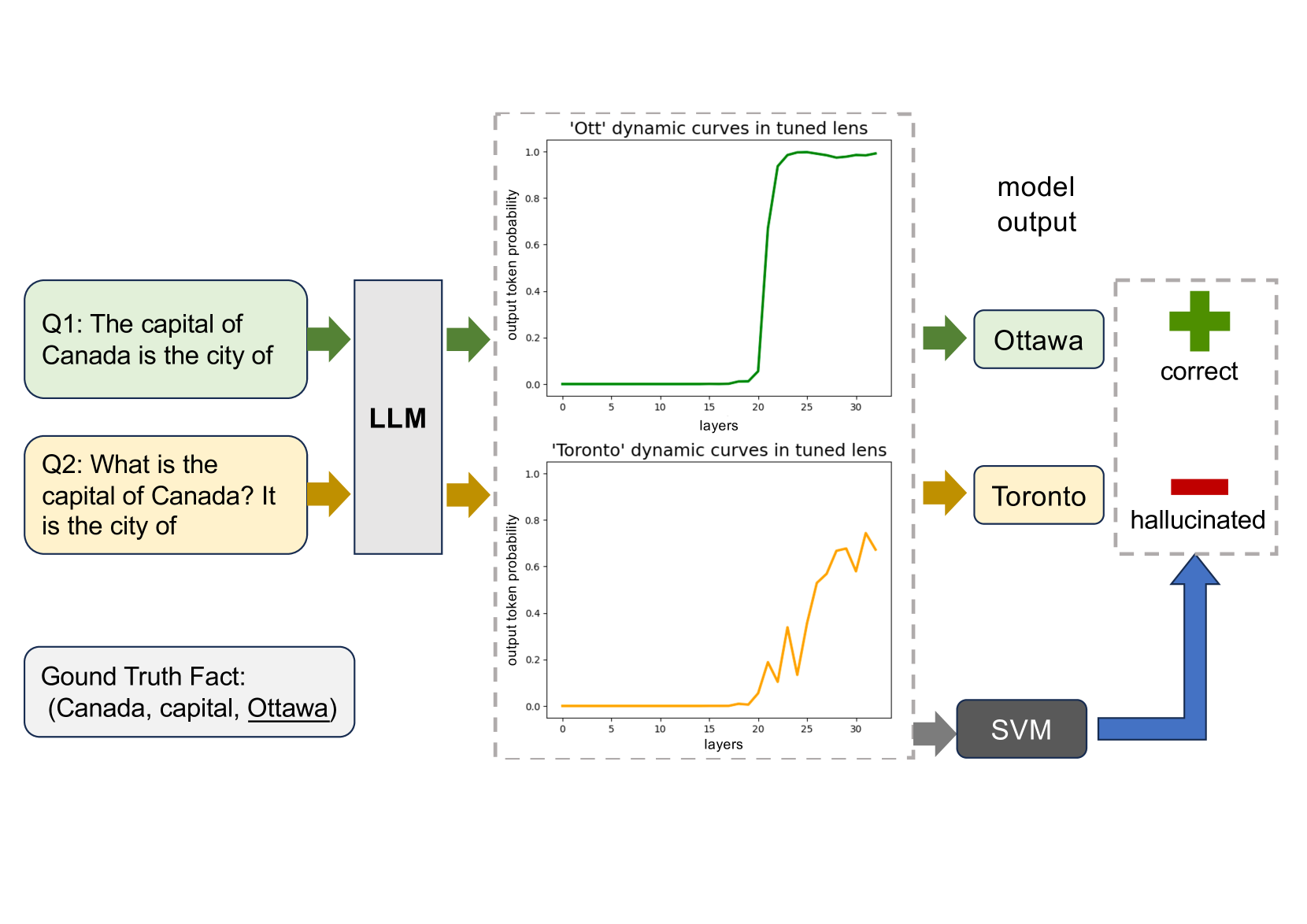
On Large Language Models' Hallucination with Regard to Known Facts
Che Jiang, Biqing Qi, Xiangyu Hong, Dayuan Fu, Yang Cheng, Fandong Meng, Mo Yu, Bowen Zhou, Jie Zhou
0
0
Large language models are successful in answering factoid questions but are also prone to hallucination.We investigate the phenomenon of LLMs possessing correct answer knowledge yet still hallucinating from the perspective of inference dynamics, an area not previously covered in studies on hallucinations.We are able to conduct this analysis via two key ideas.First, we identify the factual questions that query the same triplet knowledge but result in different answers. The difference between the model behaviors on the correct and incorrect outputs hence suggests the patterns when hallucinations happen. Second, to measure the pattern, we utilize mappings from the residual streams to vocabulary space. We reveal the different dynamics of the output token probabilities along the depths of layers between the correct and hallucinated cases. In hallucinated cases, the output token's information rarely demonstrates abrupt increases and consistent superiority in the later stages of the model. Leveraging the dynamic curve as a feature, we build a classifier capable of accurately detecting hallucinatory predictions with an 88% success rate. Our study shed light on understanding the reasons for LLMs' hallucinations on their known facts, and more importantly, on accurately predicting when they are hallucinating.
4/1/2024