Detecting and Mitigating Hallucination in Large Vision Language Models via Fine-Grained AI Feedback
2404.14233
0
0
Abstract
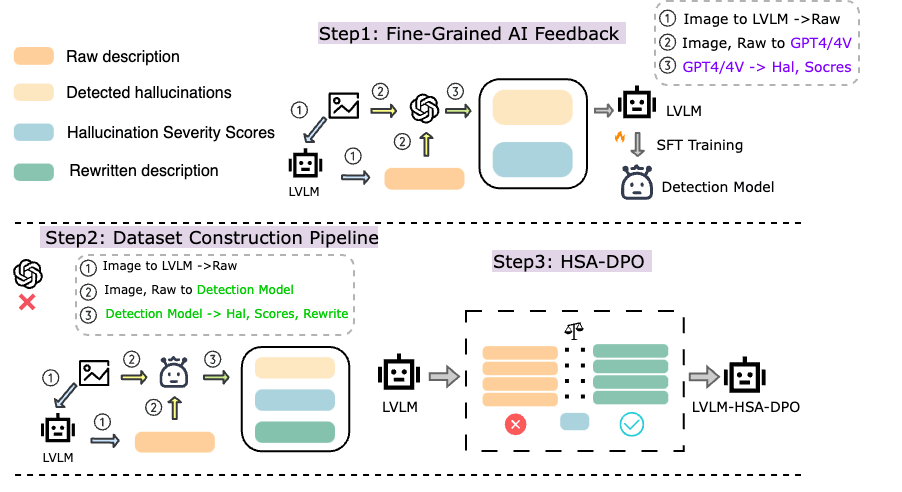
The rapidly developing Large Vision Language Models (LVLMs) have shown notable capabilities on a range of multi-modal tasks, but still face the hallucination phenomena where the generated texts do not align with the given contexts, significantly restricting the usages of LVLMs. Most previous work detects and mitigates hallucination at the coarse-grained level or requires expensive annotation (e.g., labeling by proprietary models or human experts). To address these issues, we propose detecting and mitigating hallucinations in LVLMs via fine-grained AI feedback. The basic idea is that we generate a small-size sentence-level hallucination annotation dataset by proprietary models, whereby we train a hallucination detection model which can perform sentence-level hallucination detection, covering primary hallucination types (i.e., object, attribute, and relationship). Then, we propose a detect-then-rewrite pipeline to automatically construct preference dataset for training hallucination mitigating model. Furthermore, we propose differentiating the severity of hallucinations, and introducing a Hallucination Severity-Aware Direct Preference Optimization (HSA-DPO) for mitigating hallucination in LVLMs by incorporating the severity of hallucinations into preference learning. Extensive experiments demonstrate the effectiveness of our method.
Create account to get full access
Overview
- This paper explores methods to detect and mitigate hallucination in large vision language models.
- The researchers propose using fine-grained AI feedback to align these models and reduce hallucination.
- Experiments demonstrate the effectiveness of their approach in improving the reliability and safety of these powerful language models.
Plain English Explanation
Large vision language models are AI systems that can generate human-like text based on visual inputs. However, these models can sometimes "hallucinate" - producing responses that seem plausible but are actually factually incorrect or nonsensical. This paper explores ways to address this issue.
The key idea is to use fine-grained feedback from AI systems to "align" the language models and make them less prone to hallucination. This feedback provides the models with more granular information about when their outputs are accurate or inaccurate, allowing the models to better distinguish truth from fiction. The researchers show this approach can enhance the reliability and safety of these powerful AI systems.
By incorporating this fine-grained feedback, the models can learn to be more discerning and only generate outputs they are highly confident are factual and truthful. This helps ensure these large language models are giving users information they can truly trust, rather than potentially misleading or made-up content.
Technical Explanation
The paper proposes a framework called Fine-Grained AI Feedback (FGAIF) to detect and mitigate hallucination in large vision language models. FGAIF uses a separate AI model to provide granular feedback on the accuracy of the language model's outputs, down to the token level.
This fine-grained feedback is then used to fine-tune the language model via a direct preference optimization approach. This encourages the model to favor outputs that are more factually grounded and reduces its tendency to hallucinate.
Experiments on benchmark datasets show FGAIF significantly improves the language model's reliability, as measured by metrics like factual consistency. The paper also demonstrates FGAIF's effectiveness in mitigating hallucination for text summarization tasks.
Critical Analysis
The paper provides a compelling approach to address the important challenge of hallucination in large vision language models. By incorporating fine-grained feedback, the models can learn to distinguish truth from fiction more effectively.
However, the paper does not explore the potential downstream effects of this approach. For example, it's unclear how the fine-tuning process may impact the models' broader language understanding capabilities or their ability to handle more open-ended tasks.
Additionally, the paper focuses on benchmark datasets, but real-world applications may surface new types of hallucination that require further research. Maintaining the safety and reliability of these models in diverse, real-world settings remains an important area for future work.
Conclusion
This paper presents a promising approach to detect and mitigate hallucination in large vision language models using fine-grained AI feedback. By aligning the models with more granular accuracy information, the researchers demonstrate significant improvements in factual consistency and reliability.
While further research is needed to fully understand the broader implications of this approach, the work represents an important step towards enhancing the safety and trustworthiness of these powerful AI systems. As language models continue to advance, developing techniques to ensure their outputs are grounded in truth will be crucial for their responsible deployment in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

A Survey on Hallucination in Large Vision-Language Models
Hanchao Liu, Wenyuan Xue, Yifei Chen, Dapeng Chen, Xiutian Zhao, Ke Wang, Liping Hou, Rongjun Li, Wei Peng
0
0
Recent development of Large Vision-Language Models (LVLMs) has attracted growing attention within the AI landscape for its practical implementation potential. However, ``hallucination'', or more specifically, the misalignment between factual visual content and corresponding textual generation, poses a significant challenge of utilizing LVLMs. In this comprehensive survey, we dissect LVLM-related hallucinations in an attempt to establish an overview and facilitate future mitigation. Our scrutiny starts with a clarification of the concept of hallucinations in LVLMs, presenting a variety of hallucination symptoms and highlighting the unique challenges inherent in LVLM hallucinations. Subsequently, we outline the benchmarks and methodologies tailored specifically for evaluating hallucinations unique to LVLMs. Additionally, we delve into an investigation of the root causes of these hallucinations, encompassing insights from the training data and model components. We also critically review existing methods for mitigating hallucinations. The open questions and future directions pertaining to hallucinations within LVLMs are discussed to conclude this survey.
5/7/2024

Mitigating Dialogue Hallucination for Large Vision Language Models via Adversarial Instruction Tuning
Dongmin Park, Zhaofang Qian, Guangxing Han, Ser-Nam Lim
0
0
Mitigating hallucinations of Large Vision Language Models,(LVLMs) is crucial to enhance their reliability for general-purpose assistants. This paper shows that such hallucinations of LVLMs can be significantly exacerbated by preceding user-system dialogues. To precisely measure this, we first present an evaluation benchmark by extending popular multi-modal benchmark datasets with prepended hallucinatory dialogues powered by our novel Adversarial Question Generator (AQG), which can automatically generate image-related yet adversarial dialogues by adopting adversarial attacks on LVLMs. On our benchmark, the zero-shot performance of state-of-the-art LVLMs drops significantly for both the VQA and Captioning tasks. Next, we further reveal this hallucination is mainly due to the prediction bias toward preceding dialogues rather than visual content. To reduce this bias, we propose Adversarial Instruction Tuning (AIT) that robustly fine-tunes LVLMs against hallucinatory dialogues. Extensive experiments show our proposed approach successfully reduces dialogue hallucination while maintaining performance.
5/28/2024

FGAIF: Aligning Large Vision-Language Models with Fine-grained AI Feedback
Liqiang Jing, Xinya Du
0
0
Large Vision-Language Models (LVLMs) have demonstrated proficiency in tackling a variety of visual-language tasks. However, current LVLMs suffer from misalignment between text and image modalities which causes three kinds of hallucination problems, i.e., object existence, object attribute, and object relationship. To tackle this issue, existing methods mainly utilize Reinforcement Learning (RL) to align modalities in LVLMs. However, they still suffer from three main limitations: (1) General feedback can not indicate the hallucination type contained in the response; (2) Sparse rewards only give the sequence-level reward for the whole response; and (3)Annotation cost is time-consuming and labor-intensive. To handle these limitations, we propose an innovative method to align modalities in LVLMs through Fine-Grained Artificial Intelligence Feedback (FGAIF), which mainly consists of three steps: AI-based Feedback Collection, Fine-grained Reward Model Training, and Reinforcement Learning with Fine-grained Reward. Specifically, We first utilize AI tools to predict the types of hallucination for each segment in the response and obtain a collection of fine-grained feedback. Then, based on the collected reward data, three specialized reward models are trained to produce dense rewards. Finally, a novel fine-grained feedback module is integrated into the Proximal Policy Optimization (PPO) algorithm. Extensive experiments are conducted on hallucination and general benchmarks, demonstrating the superior performance of our proposed method. Notably, compared with previous models trained with the RL-based aligning method, our proposed method is effective even with fewer parameters.
4/9/2024
🏋️
Prescribing the Right Remedy: Mitigating Hallucinations in Large Vision-Language Models via Targeted Instruction Tuning
Rui Hu, Yahan Tu, Jitao Sang
0
0
Despite achieving outstanding performance on various cross-modal tasks, current large vision-language models (LVLMs) still suffer from hallucination issues, manifesting as inconsistencies between their generated responses and the corresponding images. Prior research has implicated that the low quality of instruction data, particularly the skewed balance between positive and negative samples, is a significant contributor to model hallucinations. Recently, researchers have proposed high-quality instruction datasets, such as LRV-Instruction, to mitigate model hallucination. Nonetheless, our investigation reveals that hallucinatory concepts from different LVLMs exhibit specificity, i.e. the distribution of hallucinatory concepts varies significantly across models. Existing datasets did not consider the hallucination specificity of different models in the design processes, thereby diminishing their efficacy in mitigating model hallucination. In this paper, we propose a targeted instruction data generation framework named DFTG that tailored to the hallucination specificity of different models. Concretely, DFTG consists of two stages: hallucination diagnosis, which extracts the necessary information from the model's responses and images for hallucination diagnosis; and targeted data generation, which generates targeted instruction data based on diagnostic results. The experimental results on hallucination benchmarks demonstrate that the targeted instruction data generated by our method are more effective in mitigating hallucinations compared to previous datasets.
4/17/2024