Mitigating spectral bias for the multiscale operator learning

0
🤷
Sign in to get full access
Overview
- Neural operators are a powerful tool for learning the mapping between infinite-dimensional parameters and solutions of partial differential equations (PDEs).
- This work focuses on multiscale PDEs with important applications like reservoir modeling and turbulence prediction.
- Existing neural operators struggle with the spectral bias towards low-frequency components in multiscale PDEs.
- The authors propose a Hierarchical Attention Neural Operator (HANO) to address this challenge.
Plain English Explanation
Partial differential equations (PDEs) are mathematical models used to describe complex systems like the flow of fluids or the spread of heat. These equations can have solutions that vary on different scales - from large, slow-moving patterns to small, fast-changing details.
Neural operators are a new type of machine learning model that can learn the relationship between the inputs and outputs of these PDE models, without needing to know the detailed equations. This is useful for applications like predicting the behavior of fluids in an oil reservoir or the turbulence in the atmosphere.
However, the authors found that existing neural operators struggle with PDEs that have this multiscale nature. The models tend to focus too much on the large-scale, low-frequency patterns and miss the important small-scale details.
To fix this, the researchers developed a new neural operator called the Hierarchical Attention Neural Operator (HANO). HANO uses a hierarchical structure to capture features at different scales, and an attention mechanism to dynamically focus on the relevant scales for each part of the problem.
The authors also incorporated a specialized loss function to help the model learn the high-frequency components better. Through experiments on representative multiscale problems, they showed that HANO outperforms other state-of-the-art methods.
Technical Explanation
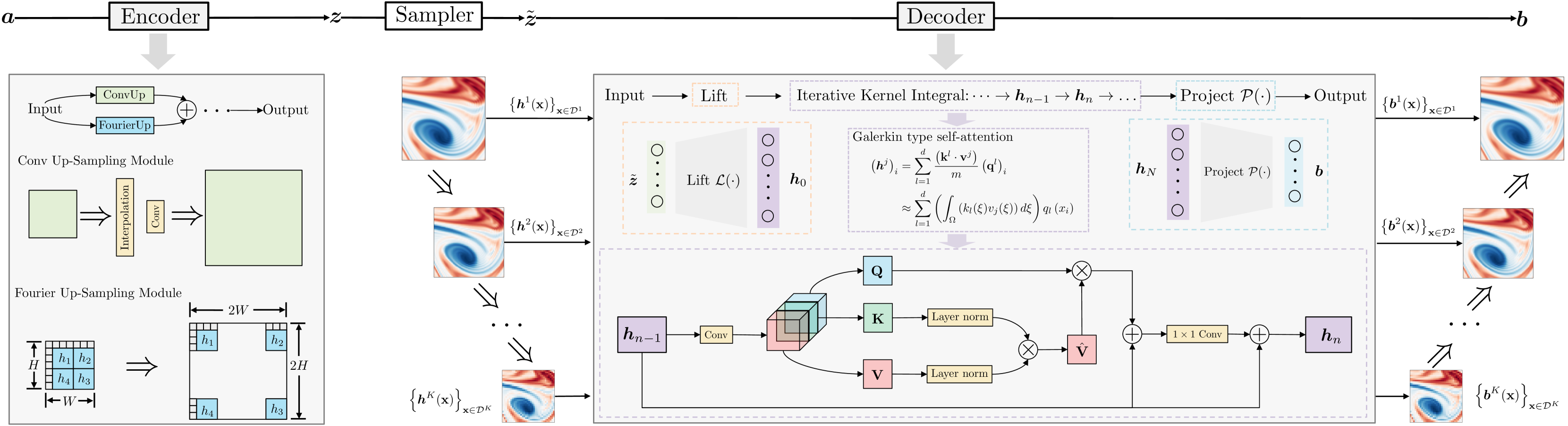
The authors identify that the spectral bias towards low-frequency components presents a significant challenge for existing neural operators when applied to multiscale PDEs. To address this, they propose the Hierarchical Attention Neural Operator (HANO), which is inspired by the hierarchical matrix approach.
HANO features a scale-adaptive interaction range and self-attentions over a hierarchy of levels, enabling nested feature computation with controllable linear cost and encoding/decoding of multiscale solution space. The authors also incorporate an empirical $H^1$ loss function to enhance the learning of high-frequency components.
Numerical experiments on representative multiscale problems demonstrate that HANO outperforms state-of-the-art methods, including the Fourier Neural Operator.
Critical Analysis
The authors acknowledge the limitations of HANO, noting that it may struggle with highly anisotropic problems or those with discontinuous solutions. Additionally, the computational cost of the hierarchical structure could be a concern for very large-scale problems.
Further research may be needed to explore alternative architectures that can better handle these challenging cases, or to develop efficient implementation strategies to reduce the computational burden.
It would also be interesting to see how HANO performs on a wider range of multiscale PDE problems, including those from different application domains beyond the examples presented in the paper.
Conclusion
The Hierarchical Attention Neural Operator (HANO) represents an important step forward in addressing the challenges of learning the solutions to multiscale PDEs using neural networks. By explicitly modeling the multiscale nature of the problem and adaptively focusing on relevant scales, HANO demonstrates improved performance over existing state-of-the-art methods.
This research highlights the potential of neural operators to unlock new capabilities in fields like fluid dynamics, climate modeling, and materials science, where multiscale phenomena play a crucial role. As the field of neural PDE solvers continues to evolve, the insights and techniques presented in this work will likely inspire further advancements and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤷
0
Mitigating spectral bias for the multiscale operator learning
Xinliang Liu, Bo Xu, Shuhao Cao, Lei Zhang
Neural operators have emerged as a powerful tool for learning the mapping between infinite-dimensional parameter and solution spaces of partial differential equations (PDEs). In this work, we focus on multiscale PDEs that have important applications such as reservoir modeling and turbulence prediction. We demonstrate that for such PDEs, the spectral bias towards low-frequency components presents a significant challenge for existing neural operators. To address this challenge, we propose a hierarchical attention neural operator (HANO) inspired by the hierarchical matrix approach. HANO features a scale-adaptive interaction range and self-attentions over a hierarchy of levels, enabling nested feature computation with controllable linear cost and encoding/decoding of multiscale solution space. We also incorporate an empirical $H^1$ loss function to enhance the learning of high-frequency components. Our numerical experiments demonstrate that HANO outperforms state-of-the-art (SOTA) methods for representative multiscale problems.
Read more6/11/2024
0
Hierarchical Neural Operator Transformer with Learnable Frequency-aware Loss Prior for Arbitrary-scale Super-resolution
Xihaier Luo, Xiaoning Qian, Byung-Jun Yoon
In this work, we present an arbitrary-scale super-resolution (SR) method to enhance the resolution of scientific data, which often involves complex challenges such as continuity, multi-scale physics, and the intricacies of high-frequency signals. Grounded in operator learning, the proposed method is resolution-invariant. The core of our model is a hierarchical neural operator that leverages a Galerkin-type self-attention mechanism, enabling efficient learning of mappings between function spaces. Sinc filters are used to facilitate the information transfer across different levels in the hierarchy, thereby ensuring representation equivalence in the proposed neural operator. Additionally, we introduce a learnable prior structure that is derived from the spectral resizing of the input data. This loss prior is model-agnostic and is designed to dynamically adjust the weighting of pixel contributions, thereby balancing gradients effectively across the model. We conduct extensive experiments on diverse datasets from different domains and demonstrate consistent improvements compared to strong baselines, which consist of various state-of-the-art SR methods.
Read more5/21/2024

0
Spectrum-Informed Multistage Neural Networks: Multiscale Function Approximators of Machine Precision
Jakin Ng, Yongji Wang, Ching-Yao Lai
Deep learning frameworks have become powerful tools for approaching scientific problems such as turbulent flow, which has wide-ranging applications. In practice, however, existing scientific machine learning approaches have difficulty fitting complex, multi-scale dynamical systems to very high precision, as required in scientific contexts. We propose using the novel multistage neural network approach with a spectrum-informed initialization to learn the residue from the previous stage, utilizing the spectral biases associated with neural networks to capture high frequency features in the residue, and successfully tackle the spectral bias of neural networks. This approach allows the neural network to fit target functions to double floating-point machine precision $O(10^{-16})$.
Read more7/25/2024
👀
0
Improved Operator Learning by Orthogonal Attention
Zipeng Xiao, Zhongkai Hao, Bokai Lin, Zhijie Deng, Hang Su
Neural operators, as an efficient surrogate model for learning the solutions of PDEs, have received extensive attention in the field of scientific machine learning. Among them, attention-based neural operators have become one of the mainstreams in related research. However, existing approaches overfit the limited training data due to the considerable number of parameters in the attention mechanism. To address this, we develop an orthogonal attention based on the eigendecomposition of the kernel integral operator and the neural approximation of eigenfunctions. The orthogonalization naturally poses a proper regularization effect on the resulting neural operator, which aids in resisting overfitting and boosting generalization. Experiments on six standard neural operator benchmark datasets comprising both regular and irregular geometries show that our method can outperform competing baselines with decent margins.
Read more7/8/2024