InPer: Whole-Process Domain Generalization via Causal Intervention and Perturbation

0

Sign in to get full access
Overview
- This paper proposes a novel method called InPer for whole-process domain generalization.
- InPer uses causal intervention and perturbation to learn models that can perform well across diverse domains.
- The authors demonstrate the effectiveness of InPer on various benchmark tasks, showing that it outperforms state-of-the-art domain generalization methods.
Plain English Explanation
The paper presents a new approach called InPer that aims to help machine learning models perform well across a wide range of datasets or "domains," even if they were trained on limited data from just a few domains. This is an important problem because in the real world, models often need to be deployed in settings that are quite different from the data they were trained on.
The key ideas behind InPer are causal intervention and perturbation. Causal intervention involves explicitly modeling the underlying causal relationships in the data, which can help the model be more robust to changes across domains. Perturbation means intentionally applying small changes or "noise" to the input data during training, which also encourages the model to learn more general and transferable representations.
By combining these two techniques, InPer is able to create machine learning models that can generalize much better to new, unseen domains compared to previous approaches. The authors show through experiments on a variety of tasks that InPer significantly outperforms other state-of-the-art domain generalization methods.
Technical Explanation
The core of the InPer method is a multi-stage training process that incorporates both causal intervention and perturbation. First, the model is trained on the base dataset using standard supervised learning. Then, the model undergoes a "causal intervention" stage, where the training data is systematically perturbed in ways that are designed to uncover the underlying causal relationships in the data.
Specifically, InPer employs a causal graph to model the data-generating process, and then performs interventions on specific nodes in this graph to create new, perturbed training examples. This forces the model to learn features that are more invariant to changes in the underlying causal factors.
Next, the model undergoes a "perturbation" stage, where random noise is injected into the input during training. This additional regularization further encourages the model to learn robust representations that can generalize to new domains.
Through extensive experiments on benchmark domain generalization tasks like image classification and natural language processing, the authors demonstrate that InPer significantly outperforms previous state-of-the-art methods. They attribute this success to InPer's ability to uncover the underlying causal structure of the data and learn features that are both discriminative and transferable across domains.
Critical Analysis
The InPer method proposed in this paper represents an interesting and promising approach to the challenge of domain generalization. By explicitly incorporating causal reasoning and perturbation into the training process, the authors have developed a technique that can learn models that are more robust and adaptable to new environments.
One potential limitation of the work is that the causal graph structure used in the intervention stage needs to be provided or learned somehow. In real-world applications, determining the correct causal relationships in complex data can be quite challenging. The authors acknowledge this and suggest exploring ways to learn the causal graph in a more automated fashion.
Additionally, while the experimental results on benchmark tasks are quite strong, it would be valuable to see how InPer performs on more large-scale, real-world domain generalization problems. The ability to scale the method to handle high-dimensional, messy data typical of many practical applications remains an open question.
Overall, this paper makes a valuable contribution to the field of domain generalization by introducing a principled approach that leverages causal reasoning and perturbation. Further research exploring the limits and extensions of this technique could lead to significant advancements in building machine learning models that are truly robust and adaptable.
Conclusion
The InPer method proposed in this paper represents an important step forward in the challenge of whole-process domain generalization. By combining causal intervention and perturbation, the authors have developed a training approach that can learn models capable of performing well across a wide range of domains, even when trained on limited data from just a few specific environments.
The strong empirical results demonstrate the effectiveness of InPer, and the underlying principles of causal reasoning and robust representation learning could inspire further innovations in domain generalization and transfer learning more broadly. As machine learning systems are increasingly deployed in real-world settings, techniques like InPer will become increasingly crucial for building models that can adapt and generalize reliably.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
InPer: Whole-Process Domain Generalization via Causal Intervention and Perturbation
Luyao Tang, Yuxuan Yuan, Chaoqi Chen, Xinghao Ding, Yue Huang
Despite the considerable advancements achieved by deep neural networks, their performance tends to degenerate when the test environment diverges from the training ones. Domain generalization (DG) solves this issue by learning representations independent of domain-related information, thus facilitating extrapolation to unseen environments. Existing approaches typically focus on formulating tailored training objectives to extract shared features from the source data. However, the disjointed training and testing procedures may compromise robustness, particularly in the face of unforeseen variations during deployment. In this paper, we propose a novel and holistic framework based on causality, named InPer, designed to enhance model generalization by incorporating causal intervention during training and causal perturbation during testing. Specifically, during the training phase, we employ entropy-based causal intervention (EnIn) to refine the selection of causal variables. To identify samples with anti-interference causal variables from the target domain, we propose a novel metric, homeostatic score, through causal perturbation (HoPer) to construct a prototype classifier in test time. Experimental results across multiple cross-domain tasks confirm the efficacy of InPer.
Read more8/23/2024
🌀
0
A Novel Cross-Perturbation for Single Domain Generalization
Dongjia Zhao, Lei Qi, Xiao Shi, Yinghuan Shi, Xin Geng
Single domain generalization aims to enhance the ability of the model to generalize to unknown domains when trained on a single source domain. However, the limited diversity in the training data hampers the learning of domain-invariant features, resulting in compromised generalization performance. To address this, data perturbation (augmentation) has emerged as a crucial method to increase data diversity. Nevertheless, existing perturbation methods often focus on either image-level or feature-level perturbations independently, neglecting their synergistic effects. To overcome these limitations, we propose CPerb, a simple yet effective cross-perturbation method. Specifically, CPerb utilizes both horizontal and vertical operations. Horizontally, it applies image-level and feature-level perturbations to enhance the diversity of the training data, mitigating the issue of limited diversity in single-source domains. Vertically, it introduces multi-route perturbation to learn domain-invariant features from different perspectives of samples with the same semantic category, thereby enhancing the generalization capability of the model. Additionally, we propose MixPatch, a novel feature-level perturbation method that exploits local image style information to further diversify the training data. Extensive experiments on various benchmark datasets validate the effectiveness of our method.
Read more6/10/2024

0
Causality-inspired Latent Feature Augmentation for Single Domain Generalization
Jian Xu, Chaojie Ji, Yankai Cao, Ye Li, Ruxin Wang
Single domain generalization (Single-DG) intends to develop a generalizable model with only one single training domain to perform well on other unknown target domains. Under the domain-hungry configuration, how to expand the coverage of source domain and find intrinsic causal features across different distributions is the key to enhancing the models' generalization ability. Existing methods mainly depend on the meticulous design of finite image-level transformation techniques and learning invariant features across domains based on statistical correlation between samples and labels in source domain. This makes it difficult to capture stable semantics between source and target domains, which hinders the improvement of the model's generalization performance. In this paper, we propose a novel causality-inspired latent feature augmentation method for Single-DG by learning the meta-knowledge of feature-level transformation based on causal learning and interventions. Instead of strongly relying on the finite image-level transformation, with the learned meta-knowledge, we can generate diverse implicit feature-level transformations in latent space based on the consistency of causal features and diversity of non-causal features, which can better compensate for the domain-hungry defect and reduce the strong reliance on initial finite image-level transformations and capture more stable domain-invariant causal features for generalization. Extensive experiments on several open-access benchmarks demonstrate the outstanding performance of our model over other state-of-the-art single domain generalization and also multi-source domain generalization methods.
Read more6/11/2024
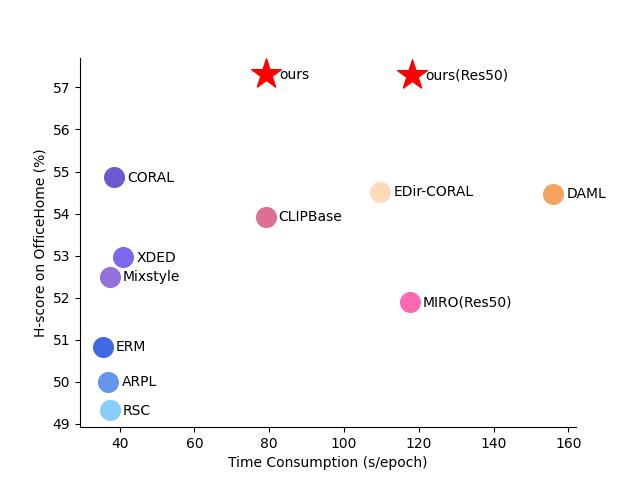
0
PracticalDG: Perturbation Distillation on Vision-Language Models for Hybrid Domain Generalization
Zining Chen, Weiqiu Wang, Zhicheng Zhao, Fei Su, Aidong Men, Hongying Meng
Domain Generalization (DG) aims to resolve distribution shifts between source and target domains, and current DG methods are default to the setting that data from source and target domains share identical categories. Nevertheless, there exists unseen classes from target domains in practical scenarios. To address this issue, Open Set Domain Generalization (OSDG) has emerged and several methods have been exclusively proposed. However, most existing methods adopt complex architectures with slight improvement compared with DG methods. Recently, vision-language models (VLMs) have been introduced in DG following the fine-tuning paradigm, but consume huge training overhead with large vision models. Therefore, in this paper, we innovate to transfer knowledge from VLMs to lightweight vision models and improve the robustness by introducing Perturbation Distillation (PD) from three perspectives, including Score, Class and Instance (SCI), named SCI-PD. Moreover, previous methods are oriented by the benchmarks with identical and fixed splits, ignoring the divergence between source domains. These methods are revealed to suffer from sharp performance decay with our proposed new benchmark Hybrid Domain Generalization (HDG) and a novel metric $H^{2}$-CV, which construct various splits to comprehensively assess the robustness of algorithms. Extensive experiments demonstrate that our method outperforms state-of-the-art algorithms on multiple datasets, especially improving the robustness when confronting data scarcity.
Read more4/16/2024