Mixture of Experts Using Tensor Products
2405.16671
0
0

Abstract
In multi-task learning, the conventional approach involves training a model on multiple tasks simultaneously. However, the training signals from different tasks can interfere with one another, potentially leading to textit{negative transfer}. To mitigate this, we investigate if modular language models can facilitate positive transfer and systematic generalization. Specifically, we propose a novel modular language model (texttt{TensorPoly}), that balances parameter efficiency with nuanced routing methods. For textit{modules}, we reparameterize Low-Rank Adaptation (texttt{LoRA}) by employing an entangled tensor through the use of tensor product operations and name the resulting approach texttt{TLoRA}. For textit{routing function}, we tailor two innovative routing functions according to the granularity: texttt{TensorPoly-I} which directs to each rank within the entangled tensor while texttt{TensorPoly-II} offers a finer-grained routing approach targeting each order of the entangled tensor. The experimental results from the multi-task T0-benchmark demonstrate that: 1) all modular LMs surpass the corresponding dense approaches, highlighting the potential of modular language models to mitigate negative inference in multi-task learning and deliver superior outcomes. 2) texttt{TensorPoly-I} achieves higher parameter efficiency in adaptation and outperforms other modular LMs, which shows the potential of our approach in multi-task transfer learning.
Create account to get full access
Overview
- This paper proposes a novel Mixture of Experts (MoE) architecture that leverages tensor products to enhance the performance of large language models (LLMs) on multiple tasks.
- The authors introduce Meteora, a modular and scalable MoE system that can be easily integrated into existing LLMs.
- The paper also discusses related work on language modeling using tensor trains and towards modular LLMs.
Plain English Explanation
In this paper, the researchers present a new approach to improving the performance of large language models (LLMs) on multiple tasks. They have developed a system called Meteora that uses a Mixture of Experts (MoE) architecture, which means the model is made up of several specialized "experts" that each focus on a particular task or skill.
To make the MoE system more effective, the researchers use tensor products, which are a way of combining different mathematical objects in a structured way. This allows the experts to learn from each other and share knowledge, without the whole system becoming too complex or unwieldy.
The key idea is that by having a modular system with specialized experts, the model can be more adaptable and perform better on a wider range of tasks, compared to a single, one-size-fits-all LLM. The researchers show that Meteora can outperform traditional LLMs on various benchmarks, while also being more scalable and easier to customize for different applications.
This work builds on previous research on language modeling using tensor trains and towards modular LLMs, which have explored similar ideas of using more flexible and modular architectures to improve the capabilities of large language models.
Technical Explanation
The paper introduces a Mixture of Experts (MoE) architecture called Meteora that leverages tensor products to enhance the performance of large language models (LLMs) on multiple tasks.
The key components of the Meteora system are:
- Experts: The model is composed of several specialized "expert" modules, each of which is trained to perform a particular task or skill.
- Gating Network: A separate module, called the gating network, is responsible for dynamically routing the input to the most appropriate expert(s) based on the task.
- Tensor Products: The experts and gating network use tensor products to effectively combine and share knowledge, without the model becoming overly complex.
The researchers show that Meteora outperforms traditional LLMs on various benchmarks, including improved content understanding through effective use of multi-task and MixLora, a technique for enhancing LLMs through fine-tuning. They also demonstrate that Meteora is more scalable and easier to customize for different applications.
Critical Analysis
The paper presents a compelling approach to improving the performance of large language models by using a modular and scalable Mixture of Experts architecture. The key strengths of the research include:
- The use of tensor products to effectively combine and share knowledge between the expert modules, which helps to overcome the complexity and rigidity of traditional LLMs.
- The experimental results showing that Meteora outperforms state-of-the-art LLM techniques on various benchmarks, suggesting the approach has merit.
- The potential for Meteora to be more easily customized and scaled to different applications, which could make it a valuable tool for real-world use cases.
However, the paper also raises some potential concerns and areas for further research:
- The authors do not provide a detailed analysis of the computational and memory requirements of the Meteora system, which could be an important consideration for practical deployments.
- The paper does not explore the interpretability or explainability of the Meteora model, which could be an important factor for certain applications where the decision-making process needs to be transparent.
- The researchers do not investigate the robustness of the Meteora system to adversarial attacks or other forms of distributional shift, which could be a crucial consideration for real-world deployment.
Overall, the paper presents a promising approach to enhancing the capabilities of large language models, but additional research would be needed to fully understand the strengths, limitations, and practical implications of the Meteora system.
Conclusion
This paper introduces a novel Mixture of Experts (MoE) architecture called Meteora that leverages tensor products to improve the performance of large language models (LLMs) on multiple tasks. The key idea is to use a modular system with specialized "expert" modules, combined in a structured way using tensor products, to create a more adaptable and effective model compared to traditional LLMs.
The researchers demonstrate that Meteora outperforms state-of-the-art LLM techniques on various benchmarks, while also being more scalable and easier to customize for different applications. This work builds on previous research on language modeling using tensor trains and towards modular LLMs, and could have important implications for the future development of large language models and their use in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
MeteoRA: Multiple-tasks Embedded LoRA for Large Language Models
Jingwei Xu, Junyu Lai, Yunpeng Huang
0
0
The pretrain+fine-tune paradigm is foundational in deploying large language models (LLMs) across a diverse range of downstream applications. Among these, Low-Rank Adaptation (LoRA) stands out for its parameter-efficient fine-tuning (PEFT), producing numerous off-the-shelf task-specific LoRA adapters. However, this approach requires explicit task intention selection, posing challenges for automatic task sensing and switching during inference with multiple existing LoRA adapters embedded in a single LLM. In this work, we introduce MeteoRA (Multiple-Tasks embedded LoRA), a scalable multi-knowledge LoRA fusion framework designed for LLMs. MeteoRA integrates various LoRA adapters in a Mixture-of-Experts (MoE) style into the base LLM, enabling the model to automatically select the most pertinent adapter based on the task input. This advancement significantly enhances the LLM's capability to handle composite tasks that require different adapters to solve various components of the problem. Our evaluations, featuring the LlaMA2-13B and LlaMA3-8B base models equipped with off-the-shelf 28 LoRA adapters through MeteoRA, demonstrate equivalent performance with the individual adapters. Furthermore, both base models equipped with MeteoRA achieve superior performance in sequentially solving composite tasks with ten problems in only a single inference process, highlighting the ability of timely intention switching in MeteoRA embedded LLMs.
5/27/2024
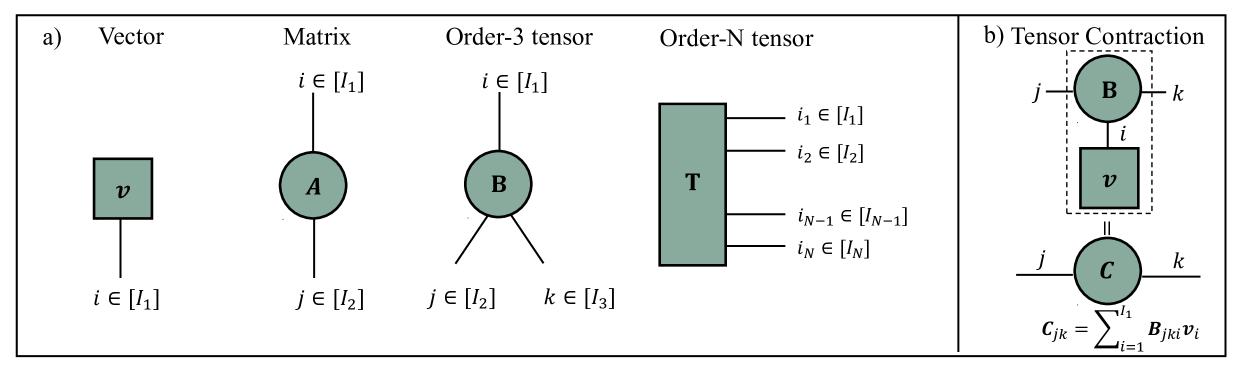
Language Modeling Using Tensor Trains
Zhan Su, Yuqin Zhou, Fengran Mo, Jakob Grue Simonsen
0
0
We propose a novel tensor network language model based on the simplest tensor network (i.e., tensor trains), called `Tensor Train Language Model' (TTLM). TTLM represents sentences in an exponential space constructed by the tensor product of words, but computing the probabilities of sentences in a low-dimensional fashion. We demonstrate that the architectures of Second-order RNNs, Recurrent Arithmetic Circuits (RACs), and Multiplicative Integration RNNs are, essentially, special cases of TTLM. Experimental evaluations on real language modeling tasks show that the proposed variants of TTLM (i.e., TTLM-Large and TTLM-Tiny) outperform the vanilla Recurrent Neural Networks (RNNs) with low-scale of hidden units. (The code is available at https://github.com/shuishen112/tensortrainlm.)
5/9/2024
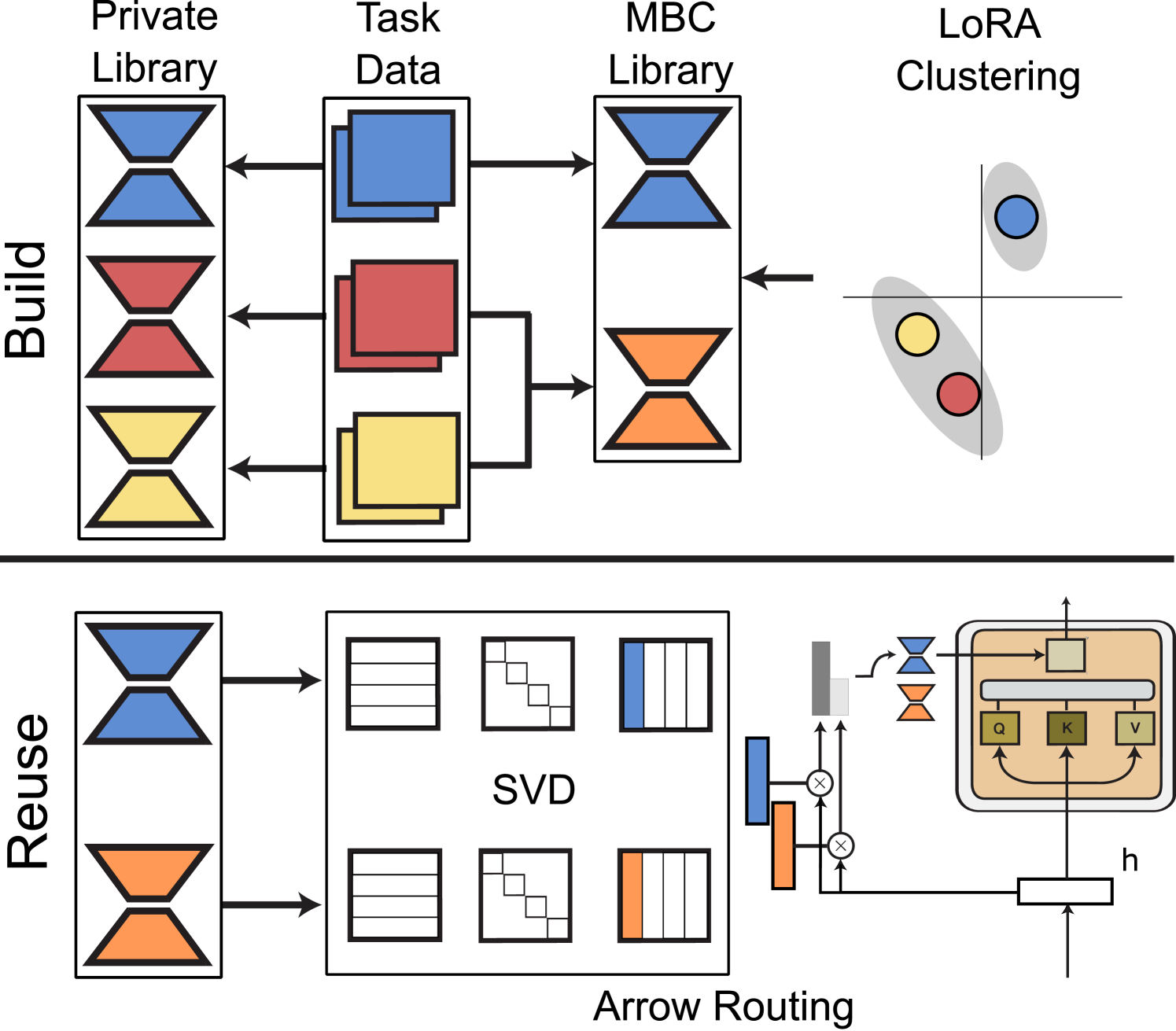
Towards Modular LLMs by Building and Reusing a Library of LoRAs
Oleksiy Ostapenko, Zhan Su, Edoardo Maria Ponti, Laurent Charlin, Nicolas Le Roux, Matheus Pereira, Lucas Caccia, Alessandro Sordoni
0
0
The growing number of parameter-efficient adaptations of a base large language model (LLM) calls for studying whether we can reuse such trained adapters to improve performance for new tasks. We study how to best build a library of adapters given multi-task data and devise techniques for both zero-shot and supervised task generalization through routing in such library. We benchmark existing approaches to build this library and introduce model-based clustering, MBC, a method that groups tasks based on the similarity of their adapter parameters, indirectly optimizing for transfer across the multi-task dataset. To re-use the library, we present a novel zero-shot routing mechanism, Arrow, which enables dynamic selection of the most relevant adapters for new inputs without the need for retraining. We experiment with several LLMs, such as Phi-2 and Mistral, on a wide array of held-out tasks, verifying that MBC-based adapters and Arrow routing lead to superior generalization to new tasks. We make steps towards creating modular, adaptable LLMs that can match or outperform traditional joint training.
5/21/2024
🤔
Improved Content Understanding With Effective Use of Multi-task Contrastive Learning
Akanksha Bindal, Sudarshan Ramanujam, Dave Golland, TJ Hazen, Tina Jiang, Fengyu Zhang, Peng Yan
0
0
In enhancing LinkedIn core content recommendation models, a significant challenge lies in improving their semantic understanding capabilities. This paper addresses the problem by leveraging multi-task learning, a method that has shown promise in various domains. We fine-tune a pre-trained, transformer-based LLM using multi-task contrastive learning with data from a diverse set of semantic labeling tasks. We observe positive transfer, leading to superior performance across all tasks when compared to training independently on each. Our model outperforms the baseline on zero shot learning and offers improved multilingual support, highlighting its potential for broader application. The specialized content embeddings produced by our model outperform generalized embeddings offered by OpenAI on Linkedin dataset and tasks. This work provides a robust foundation for vertical teams across LinkedIn to customize and fine-tune the LLM to their specific applications. Our work offers insights and best practices for the field to build on.
5/22/2024