Language Modeling Using Tensor Trains
2405.04590
2
0
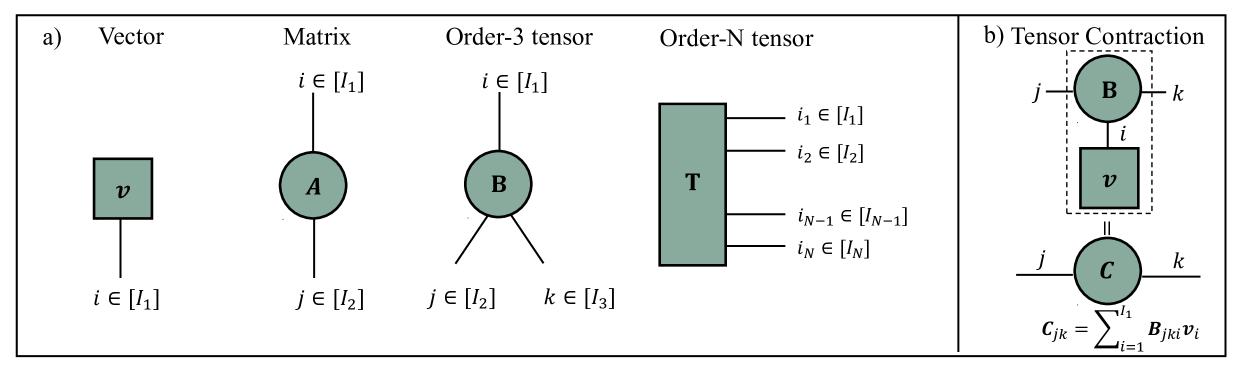
Abstract
We propose a novel tensor network language model based on the simplest tensor network (i.e., tensor trains), called `Tensor Train Language Model' (TTLM). TTLM represents sentences in an exponential space constructed by the tensor product of words, but computing the probabilities of sentences in a low-dimensional fashion. We demonstrate that the architectures of Second-order RNNs, Recurrent Arithmetic Circuits (RACs), and Multiplicative Integration RNNs are, essentially, special cases of TTLM. Experimental evaluations on real language modeling tasks show that the proposed variants of TTLM (i.e., TTLM-Large and TTLM-Tiny) outperform the vanilla Recurrent Neural Networks (RNNs) with low-scale of hidden units. (The code is available at https://github.com/shuishen112/tensortrainlm.)
Create account to get full access
Overview
- This paper explores the use of tensor train decomposition for language modeling, a technique that can represent complex high-dimensional data more efficiently than traditional neural networks.
- The authors develop a tensor train language model that leverages the representational capacity of tensor trains to capture long-range dependencies in natural language.
- They evaluate their model on various language modeling benchmarks and find it outperforms standard neural language models while using fewer parameters.
Plain English Explanation
The paper introduces a novel approach to language modeling using a mathematical concept called tensor trains. Language modeling is the task of predicting the next word in a sequence of text, which is a fundamental problem in natural language processing.
Tensor trains are a way of representing and computing with high-dimensional data more efficiently than traditional neural networks. The key insight is that many real-world datasets, including language, have an underlying low-dimensional structure that can be exploited.
By formulating the language modeling problem using tensor trains, the authors are able to build a model that can capture long-range dependencies in natural language - that is, it can understand the relationship between words that are far apart in a sentence. This is an important capability, as language often relies on context that spans multiple words or even sentences.
The authors show that their tensor train language model outperforms standard neural language models on common benchmark tasks, while using significantly fewer parameters. This suggests that the tensor train approach is a promising direction for building more compact and capable language models.
Technical Explanation
The paper proposes a tensor train language model that leverages the representational capacity of tensor trains to capture long-range dependencies in natural language.
Tensor trains are a way of representing high-dimensional data using a sequence of low-dimensional tensors. This allows the model to learn complex functions while using far fewer parameters than a traditional neural network. The authors develop a tensor train-based architecture for language modeling and show that it achieves state-of-the-art performance on a range of benchmarks.
Key elements of the tensor train language model include:
- Tensor train encoding: The model encodes the input sequence of words into a tensor train representation, which can compactly capture complex relationships between words.
- Tensor train decoder: The decoder uses the tensor train representation to predict the next word in the sequence, based on the context provided by the preceding words.
- Efficient training and inference: The tensor train structure allows for efficient computations during both training and evaluation, enabling the model to scale to large vocabularies and long sequences.
The authors evaluate their tensor train language model on a variety of language modeling benchmarks, including Penn Treebank and WikiText-2. They find that it outperforms standard neural language models, such as LSTMs and Transformers, while using significantly fewer parameters.
Critical Analysis
The paper presents a compelling approach to language modeling using tensor trains, but there are a few caveats to consider:
- Scalability: While the tensor train structure allows for efficient computations, scaling the model to very large vocabularies or long-range dependencies may still be challenging. The authors mention this as an area for future research.
- Interpretability: As with many neural network-based models, the inner workings of the tensor train language model may be difficult to interpret. This can be a limitation when trying to understand the model's reasoning or explain its predictions.
- Task generalization: The paper focuses on the language modeling task, but it's unclear how well the tensor train approach would generalize to other natural language processing tasks, such as question answering or text generation. Further research would be needed to assess the broader applicability of the technique.
Overall, the tensor train language model presented in this paper is a promising direction for improving the efficiency and performance of neural language models. However, as with any new approach, additional research and validation will be necessary to fully understand its capabilities and limitations.
Conclusion
This paper introduces a novel approach to language modeling using tensor train decomposition, a technique that can represent complex high-dimensional data more efficiently than traditional neural networks. The authors develop a tensor train language model that leverages this representational capacity to capture long-range dependencies in natural language, and they demonstrate its superior performance on various benchmarks compared to standard neural language models.
The tensor train language model represents an exciting advancement in the field of natural language processing, as it suggests that more compact and capable language models can be built by exploiting the underlying low-dimensional structure of language. While further research is needed to address scalability and interpretability challenges, this work opens up new avenues for improving the efficiency and performance of language models, with potentially far-reaching implications for a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
On the Representational Capacity of Recurrent Neural Language Models
Franz Nowak, Anej Svete, Li Du, Ryan Cotterell
0
0
This work investigates the computational expressivity of language models (LMs) based on recurrent neural networks (RNNs). Siegelmann and Sontag (1992) famously showed that RNNs with rational weights and hidden states and unbounded computation time are Turing complete. However, LMs define weightings over strings in addition to just (unweighted) language membership and the analysis of the computational power of RNN LMs (RLMs) should reflect this. We extend the Turing completeness result to the probabilistic case, showing how a rationally weighted RLM with unbounded computation time can simulate any deterministic probabilistic Turing machine (PTM) with rationally weighted transitions. Since, in practice, RLMs work in real-time, processing a symbol at every time step, we treat the above result as an upper bound on the expressivity of RLMs. We also provide a lower bound by showing that under the restriction to real-time computation, such models can simulate deterministic real-time rational PTMs.
5/31/2024
💬
Advancing Regular Language Reasoning in Linear Recurrent Neural Networks
Ting-Han Fan, Ta-Chung Chi, Alexander I. Rudnicky
0
0
In recent studies, linear recurrent neural networks (LRNNs) have achieved Transformer-level performance in natural language and long-range modeling, while offering rapid parallel training and constant inference cost. With the resurgence of interest in LRNNs, we study whether they can learn the hidden rules in training sequences, such as the grammatical structures of regular language. We theoretically analyze some existing LRNNs and discover their limitations in modeling regular language. Motivated by this analysis, we propose a new LRNN equipped with a block-diagonal and input-dependent transition matrix. Experiments suggest that the proposed model is the only LRNN capable of performing length extrapolation on regular language tasks such as Sum, Even Pair, and Modular Arithmetic. The code is released at url{https://github.com/tinghanf/RegluarLRNN}.
4/10/2024

Mixture of Experts Using Tensor Products
Zhan Su, Fengran Mo, Prayag Tiwari, Benyou Wang, Jian-Yun Nie, Jakob Grue Simonsen
0
0
In multi-task learning, the conventional approach involves training a model on multiple tasks simultaneously. However, the training signals from different tasks can interfere with one another, potentially leading to textit{negative transfer}. To mitigate this, we investigate if modular language models can facilitate positive transfer and systematic generalization. Specifically, we propose a novel modular language model (texttt{TensorPoly}), that balances parameter efficiency with nuanced routing methods. For textit{modules}, we reparameterize Low-Rank Adaptation (texttt{LoRA}) by employing an entangled tensor through the use of tensor product operations and name the resulting approach texttt{TLoRA}. For textit{routing function}, we tailor two innovative routing functions according to the granularity: texttt{TensorPoly-I} which directs to each rank within the entangled tensor while texttt{TensorPoly-II} offers a finer-grained routing approach targeting each order of the entangled tensor. The experimental results from the multi-task T0-benchmark demonstrate that: 1) all modular LMs surpass the corresponding dense approaches, highlighting the potential of modular language models to mitigate negative inference in multi-task learning and deliver superior outcomes. 2) texttt{TensorPoly-I} achieves higher parameter efficiency in adaptation and outperforms other modular LMs, which shows the potential of our approach in multi-task transfer learning.
5/28/2024
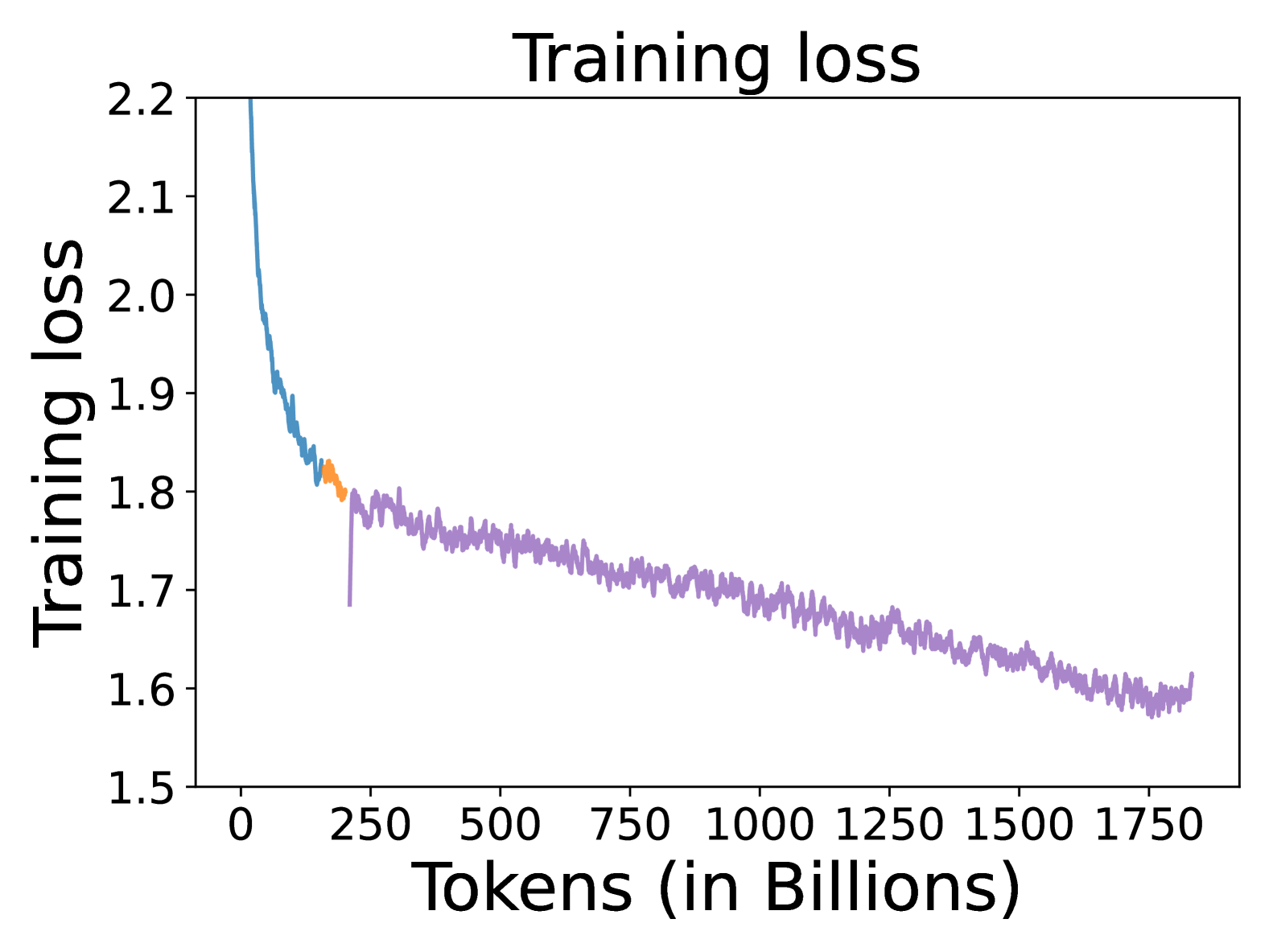
HLAT: High-quality Large Language Model Pre-trained on AWS Trainium
Haozheng Fan, Hao Zhou, Guangtai Huang, Parameswaran Raman, Xinwei Fu, Gaurav Gupta, Dhananjay Ram, Yida Wang, Jun Huan
0
0
Getting large language models (LLMs) to perform well on the downstream tasks requires pre-training over trillions of tokens. This typically demands a large number of powerful computational devices in addition to a stable distributed training framework to accelerate the training. The growing number of applications leveraging AI/ML had led to a scarcity of the expensive conventional accelerators (such as GPUs), which begs the need for the alternative specialized-accelerators that are scalable and cost-efficient. AWS Trainium is the second-generation machine learning accelerator that has been purposely built for training large deep learning models. Its corresponding instance, Amazon EC2 trn1, is an alternative to GPU instances for LLM training. However, training LLMs with billions of parameters on trn1 is challenging due to its relatively nascent software ecosystem. In this paper, we showcase HLAT: a 7 billion parameter decoder-only LLM pre-trained using trn1 instances over 1.8 trillion tokens. The performance of HLAT is benchmarked against popular open source baseline models including LLaMA and OpenLLaMA, which have been trained on NVIDIA GPUs and Google TPUs, respectively. On various evaluation tasks, we show that HLAT achieves model quality on par with the baselines. We also share the best practice of using the Neuron Distributed Training Library (NDTL), a customized distributed training library for AWS Trainium to achieve efficient training. Our work demonstrates that AWS Trainium powered by the NDTL is able to successfully pre-train state-of-the-art LLM models with high performance and cost-effectiveness.
4/17/2024