MM-KWS: Multi-modal Prompts for Multilingual User-defined Keyword Spotting
2406.07310
0
0

Abstract
In this paper, we propose MM-KWS, a novel approach to user-defined keyword spotting leveraging multi-modal enrollments of text and speech templates. Unlike previous methods that focus solely on either text or speech features, MM-KWS extracts phoneme, text, and speech embeddings from both modalities. These embeddings are then compared with the query speech embedding to detect the target keywords. To ensure the applicability of MM-KWS across diverse languages, we utilize a feature extractor incorporating several multilingual pre-trained models. Subsequently, we validate its effectiveness on Mandarin and English tasks. In addition, we have integrated advanced data augmentation tools for hard case mining to enhance MM-KWS in distinguishing confusable words. Experimental results on the LibriPhrase and WenetPhrase datasets demonstrate that MM-KWS outperforms prior methods significantly.
Create account to get full access
Overview
- This paper presents a novel approach called MM-KWS for multilingual user-defined keyword spotting using multimodal prompts.
- The key idea is to leverage language-agnostic visual and acoustic features to enable keyword spotting in multiple languages without the need for per-language models.
- This allows users to define their own keywords and have the system detect them across different languages, opening up new possibilities for multilingual voice interfaces.
Plain English Explanation
The paper introduces a system called MM-KWS that can detect user-defined keywords in multiple languages, even if the user doesn't speak those languages. Typically, keyword spotting systems require separate models for each language, which is expensive and time-consuming to develop.
The MM-KWS approach gets around this by using visual and acoustic features that are independent of the language. So instead of building separate models for each language, the system can learn a single model that works across all the languages. This allows users to define their own keywords and have the system find them, even in languages the user doesn't understand.
This is a powerful capability that could enable new kinds of multilingual voice interfaces. For example, a user could teach the system to detect their own name or a specific product name, and then the system could respond to those keywords in whatever language the speaker is using. This flexibility opens up a lot of possibilities for building more natural and intuitive voice-based user experiences.
Technical Explanation
The core of the MM-KWS approach is the use of multimodal prompts that combine visual and acoustic features. The visual features are extracted from images of the keyword, while the acoustic features come from audio recordings of the keyword being spoken.
These multimodal prompts are then used to train a single, language-universal speech attribute model that can detect the keyword across different languages. The authors show that this approach outperforms traditional keyword spotting techniques that require separate models for each language.
The paper also introduces a multitask training approach that leverages additional data sources to further improve the keyword spotting performance. This includes using sparse binarization techniques to make the model more efficient and scalable.
Critical Analysis
The MM-KWS approach presents an innovative solution to the challenge of building multilingual keyword spotting systems. By using language-agnostic multimodal prompts, the system can avoid the need for per-language models, which is a significant practical advantage.
However, the paper does not provide much discussion of the limitations or potential drawbacks of this approach. For example, it's not clear how the system would handle cases where the visual and acoustic features of a keyword vary significantly across languages or dialects. Additionally, the reliance on multimodal data could make the system more complex and harder to deploy in real-world scenarios where high-quality visual and audio data may not be available.
Further research would be needed to better understand the robustness and scalability of the MM-KWS approach, particularly when applied to a wider range of languages and use cases. Exploring the trade-offs between the multimodal approach and more traditional keyword spotting techniques would also be valuable.
Conclusion
The MM-KWS system presented in this paper represents a promising step towards more flexible and user-friendly multilingual voice interfaces. By leveraging language-agnostic multimodal features, the system can enable users to define their own keywords and have them detected across multiple languages, without the need for complex per-language models.
This approach opens up new possibilities for building more natural and intuitive voice-based user experiences, where users can interact with systems in their preferred language and have their specific needs and preferences recognized. As the field of voice interface technology continues to evolve, innovations like MM-KWS will be crucial for making these systems more accessible and inclusive for users around the world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Text-aware Speech Separation for Multi-talker Keyword Spotting
Haoyu Li, Baochen Yang, Yu Xi, Linfeng Yu, Tian Tan, Hao Li, Kai Yu
0
0
For noisy environments, ensuring the robustness of keyword spotting (KWS) systems is essential. While much research has focused on noisy KWS, less attention has been paid to multi-talker mixed speech scenarios. Unlike the usual cocktail party problem where multi-talker speech is separated using speaker clues, the key challenge here is to extract the target speech for KWS based on text clues. To address it, this paper proposes a novel Text-aware Permutation Determinization Training method for multi-talker KWS with a clue-based Speech Separation front-end (TPDT-SS). Our research highlights the critical role of SS front-ends and shows that incorporating keyword-specific clues into these models can greatly enhance the effectiveness. TPDT-SS shows remarkable success in addressing permutation problems in mixed keyword speech, thereby greatly boosting the performance of the backend. Additionally, fine-tuning our system on unseen mixed speech results in further performance improvement.
6/19/2024
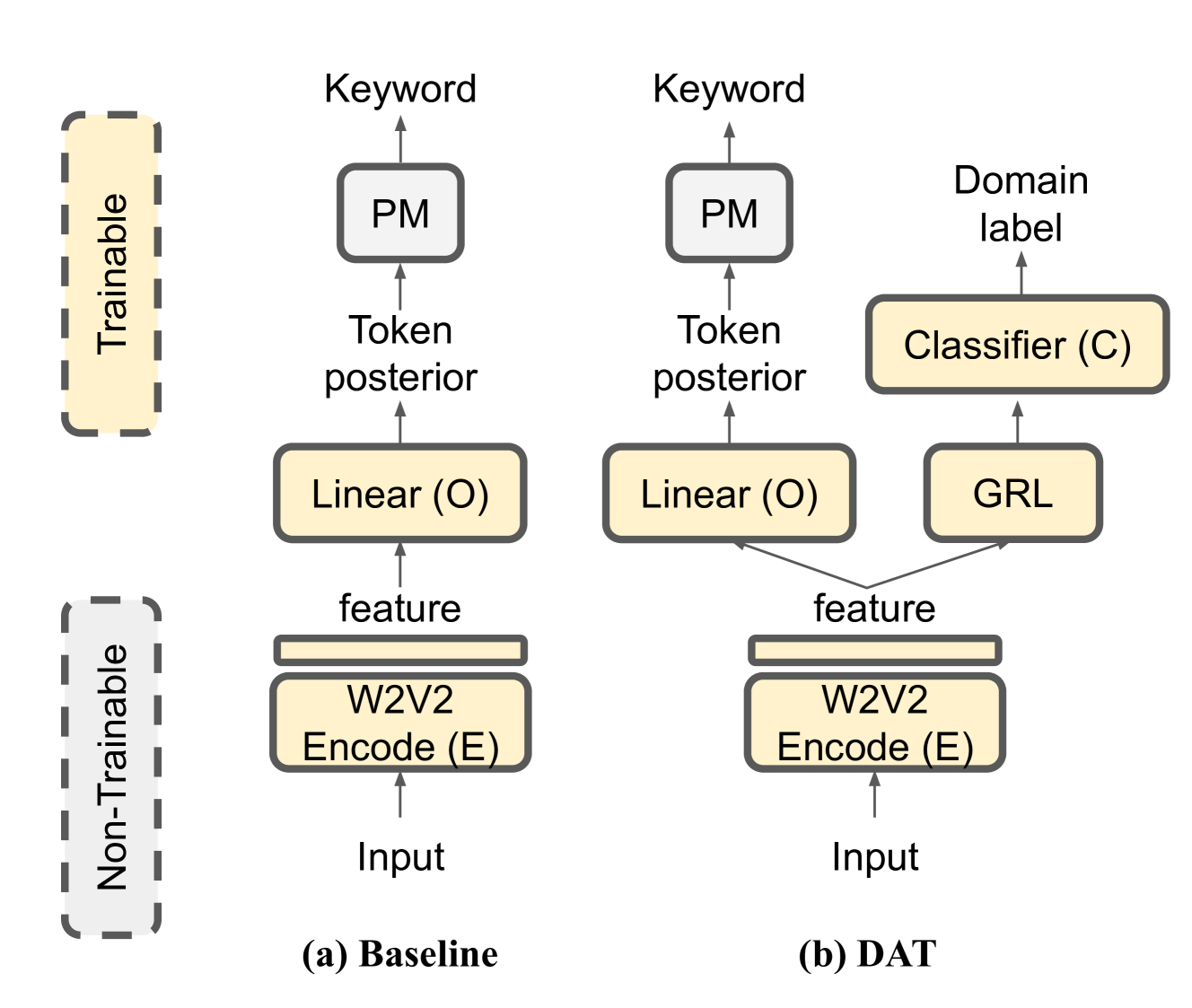
Language-Universal Speech Attributes Modeling for Zero-Shot Multilingual Spoken Keyword Recognition
Hao Yen, Pin-Jui Ku, Sabato Marco Siniscalchi, Chin-Hui Lee
0
0
We propose a novel language-universal approach to end-to-end automatic spoken keyword recognition (SKR) leveraging upon (i) a self-supervised pre-trained model, and (ii) a set of universal speech attributes (manner and place of articulation). Specifically, Wav2Vec2.0 is used to generate robust speech representations, followed by a linear output layer to produce attribute sequences. A non-trainable pronunciation model then maps sequences of attributes into spoken keywords in a multilingual setting. Experiments on the Multilingual Spoken Words Corpus show comparable performances to character- and phoneme-based SKR in seen languages. The inclusion of domain adversarial training (DAT) improves the proposed framework, outperforming both character- and phoneme-based SKR approaches with 13.73% and 17.22% relative word error rate (WER) reduction in seen languages, and achieves 32.14% and 19.92% WER reduction for unseen languages in zero-shot settings.
6/5/2024
🏋️
A Multitask Training Approach to Enhance Whisper with Contextual Biasing and Open-Vocabulary Keyword Spotting
Yuang Li, Min Zhang, Chang Su, Yinglu Li, Xiaosong Qiao, Mengxin Ren, Miaomiao Ma, Daimeng Wei, Shimin Tao, Hao Yang
0
0
The recognition of rare named entities, such as personal names and terminologies, is challenging for automatic speech recognition (ASR) systems, especially when they are not frequently observed in the training data. In this paper, we introduce keyword spotting enhanced Whisper (KWS-Whisper), a novel ASR system that leverages the Whisper model and performs open-vocabulary keyword spotting (OV-KWS) on the hidden states of the Whisper encoder to recognize user-defined named entities. These entities serve as prompts for the Whisper decoder. To optimize the model, we propose a multitask training approach that learns OV-KWS and contextual-ASR tasks. We evaluate our approach on Chinese Aishell hot word subsets and two internal code-switching test sets and show that it significantly improves the entity recall compared to the original Whisper model. Moreover, we demonstrate that the OV-KWS can be a plug-and-play module to enhance the ASR error correction methods and frozen Whisper models.
6/7/2024
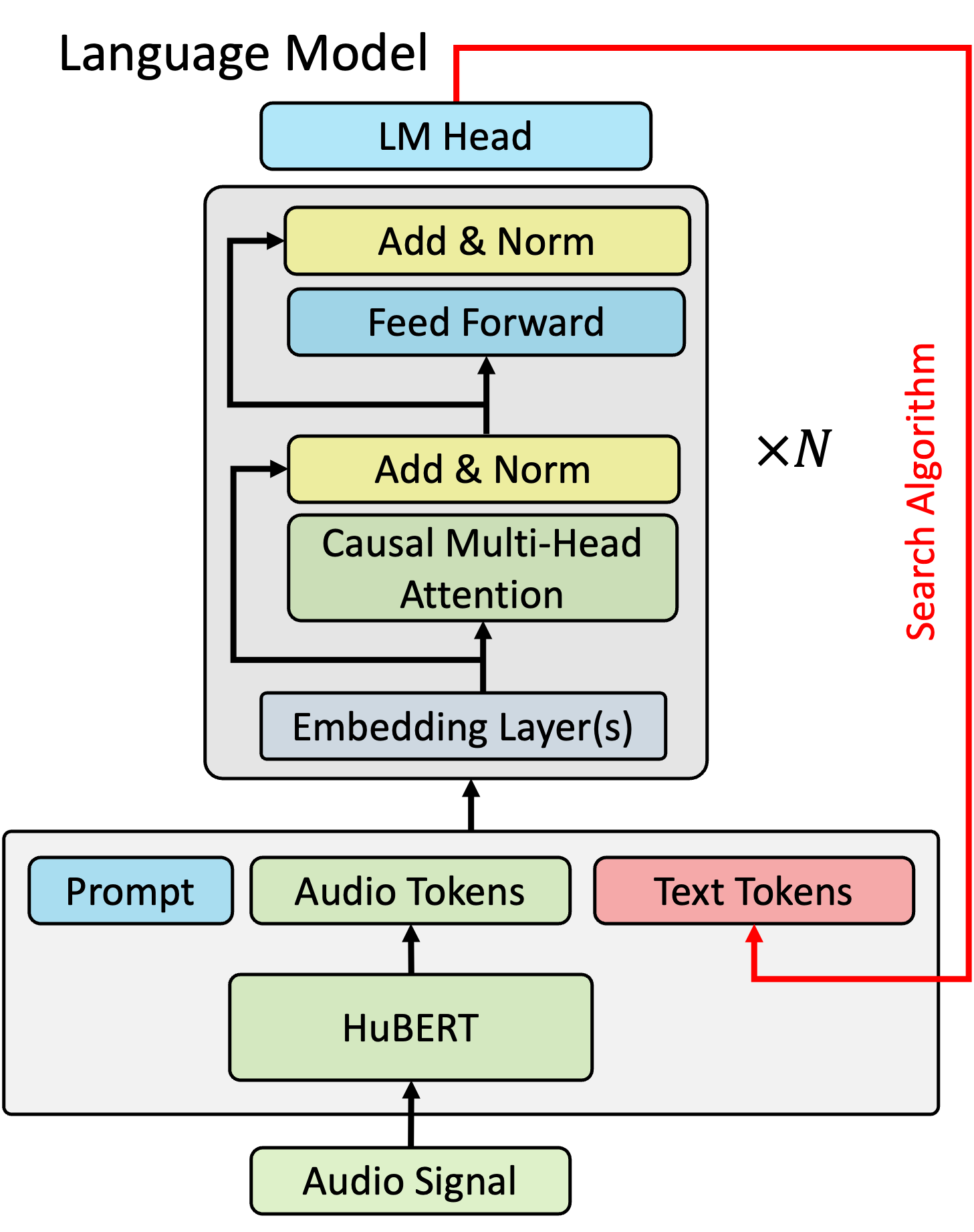
Multi-Modal Retrieval For Large Language Model Based Speech Recognition
Jari Kolehmainen, Aditya Gourav, Prashanth Gurunath Shivakumar, Yile Gu, Ankur Gandhe, Ariya Rastrow, Grant Strimel, Ivan Bulyko
0
0
Retrieval is a widely adopted approach for improving language models leveraging external information. As the field moves towards multi-modal large language models, it is important to extend the pure text based methods to incorporate other modalities in retrieval as well for applications across the wide spectrum of machine learning tasks and data types. In this work, we propose multi-modal retrieval with two approaches: kNN-LM and cross-attention techniques. We demonstrate the effectiveness of our retrieval approaches empirically by applying them to automatic speech recognition tasks with access to external information. Under this setting, we show that speech-based multi-modal retrieval outperforms text based retrieval, and yields up to 50 % improvement in word error rate over the multi-modal language model baseline. Furthermore, we achieve state-of-the-art recognition results on the Spoken-Squad question answering dataset.
6/17/2024