Open vocabulary keyword spotting through transfer learning from speech synthesis
2404.03914
0
0

Abstract
Identifying keywords in an open-vocabulary context is crucial for personalizing interactions with smart devices. Previous approaches to open vocabulary keyword spotting dependon a shared embedding space created by audio and text encoders. However, these approaches suffer from heterogeneous modality representations (i.e., audio-text mismatch). To address this issue, our proposed framework leverages knowledge acquired from a pre-trained text-to-speech (TTS) system. This knowledge transfer allows for the incorporation of awareness of audio projections into the text representations derived from the text encoder. The performance of the proposed approach is compared with various baseline methods across four different datasets. The robustness of our proposed model is evaluated by assessing its performance across different word lengths and in an Out-of-Vocabulary (OOV) scenario. Additionally, the effectiveness of transfer learning from the TTS system is investigated by analyzing its different intermediate representations. The experimental results indicate that, in the challenging LibriPhrase Hard dataset, the proposed approach outperformed the cross-modality correspondence detector (CMCD) method by a significant improvement of 8.22% in area under the curve (AUC) and 12.56% in equal error rate (EER).
Create account to get full access
Overview
- This paper presents a novel approach for open vocabulary keyword spotting using transfer learning from speech synthesis models.
- The proposed method leverages the text encoding capabilities of pre-trained speech synthesis models to enable keyword spotting for arbitrary words, without the need for expensive data collection and model retraining.
- The authors demonstrate the effectiveness of their approach on several benchmark datasets, showing significant improvements over existing keyword spotting techniques.
Plain English Explanation
In this paper, the researchers developed a new way to detect keywords in speech, even if those keywords are not part of the model's original training data. Typically, keyword spotting systems need to be retrained with lots of data every time you want to detect new keywords.
The key insight of this work is to [link to https://aimodels.fyi/papers/arxiv/transfer-learning-from-whisper-microscopic-intelligibility-prediction] transfer the text encoding capabilities from pre-trained speech synthesis models, which can generate speech for any word. By leveraging these pre-trained models, the researchers were able to build a keyword spotting system that can detect arbitrary keywords without requiring additional data or retraining.
This approach is significant because it makes keyword spotting much more flexible and scalable. Instead of having to collect and label data for every new keyword you want to detect, you can simply use the pre-trained models to spot those keywords. The researchers showed that their method outperformed existing keyword spotting techniques on several benchmark datasets.
Technical Explanation
The proposed method consists of two main components: [link to https://arxiv.org/html/2404.03914v1#S2.SS1] a text encoder and a keyword spotter. The text encoder is a pre-trained speech synthesis model that can encode arbitrary text into a compact representation. The keyword spotter is a neural network that takes the encoded text and the audio signal as input, and outputs the presence or absence of the keyword.
To train the keyword spotter, the authors leverage transfer learning. They first pre-train the text encoder on a large speech synthesis dataset, which allows the encoder to learn rich text representations. They then freeze the text encoder and train the keyword spotter on a smaller keyword spotting dataset, using the pre-trained text encoder to provide the text representations.
The authors evaluate their method on several benchmark datasets, including Google Speech Commands and Fluent Speech Commands. They show that their approach significantly outperforms existing keyword spotting methods, particularly for [link to https://aimodels.fyi/papers/arxiv/zero-shot-multi-lingual-speaker-verification-clinical] open vocabulary keywords that were not part of the training data.
Critical Analysis
The authors acknowledge that their method relies on the availability of pre-trained speech synthesis models, which may not always be easy to obtain. Additionally, the performance of the keyword spotter is still dependent on the quality of the text representations learned by the pre-trained encoder, which could be a potential limitation.
Another area for further research could be [link to https://aimodels.fyi/papers/arxiv/multi-stage-multi-modal-pre-training-automatic] exploring ways to jointly optimize the text encoder and keyword spotter, rather than using a pre-trained and frozen encoder. This could potentially lead to even better performance by allowing the encoder to be fine-tuned for the specific keyword spotting task.
Overall, the paper presents a promising approach that leverages transfer learning to enable flexible and scalable keyword spotting. The results are compelling, and the method could have significant impact in applications where the ability to detect arbitrary keywords is important.
Conclusion
This paper introduces a novel approach for open vocabulary keyword spotting that leverages transfer learning from pre-trained speech synthesis models. By using the text encoding capabilities of these models, the researchers were able to build a keyword spotter that can detect arbitrary keywords without the need for expensive data collection and model retraining.
The results demonstrate the effectiveness of this approach, with significant improvements over existing keyword spotting techniques. This work is an important step towards more flexible and scalable keyword spotting systems, which could have wide-ranging applications in areas like [link to https://aimodels.fyi/papers/arxiv/transforming-llms-into-cross-modal-cross-lingual] voice assistants, speech-based interfaces, and audio analytics.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
A Multitask Training Approach to Enhance Whisper with Contextual Biasing and Open-Vocabulary Keyword Spotting
Yuang Li, Min Zhang, Chang Su, Yinglu Li, Xiaosong Qiao, Mengxin Ren, Miaomiao Ma, Daimeng Wei, Shimin Tao, Hao Yang
0
0
The recognition of rare named entities, such as personal names and terminologies, is challenging for automatic speech recognition (ASR) systems, especially when they are not frequently observed in the training data. In this paper, we introduce keyword spotting enhanced Whisper (KWS-Whisper), a novel ASR system that leverages the Whisper model and performs open-vocabulary keyword spotting (OV-KWS) on the hidden states of the Whisper encoder to recognize user-defined named entities. These entities serve as prompts for the Whisper decoder. To optimize the model, we propose a multitask training approach that learns OV-KWS and contextual-ASR tasks. We evaluate our approach on Chinese Aishell hot word subsets and two internal code-switching test sets and show that it significantly improves the entity recall compared to the original Whisper model. Moreover, we demonstrate that the OV-KWS can be a plug-and-play module to enhance the ASR error correction methods and frozen Whisper models.
6/7/2024
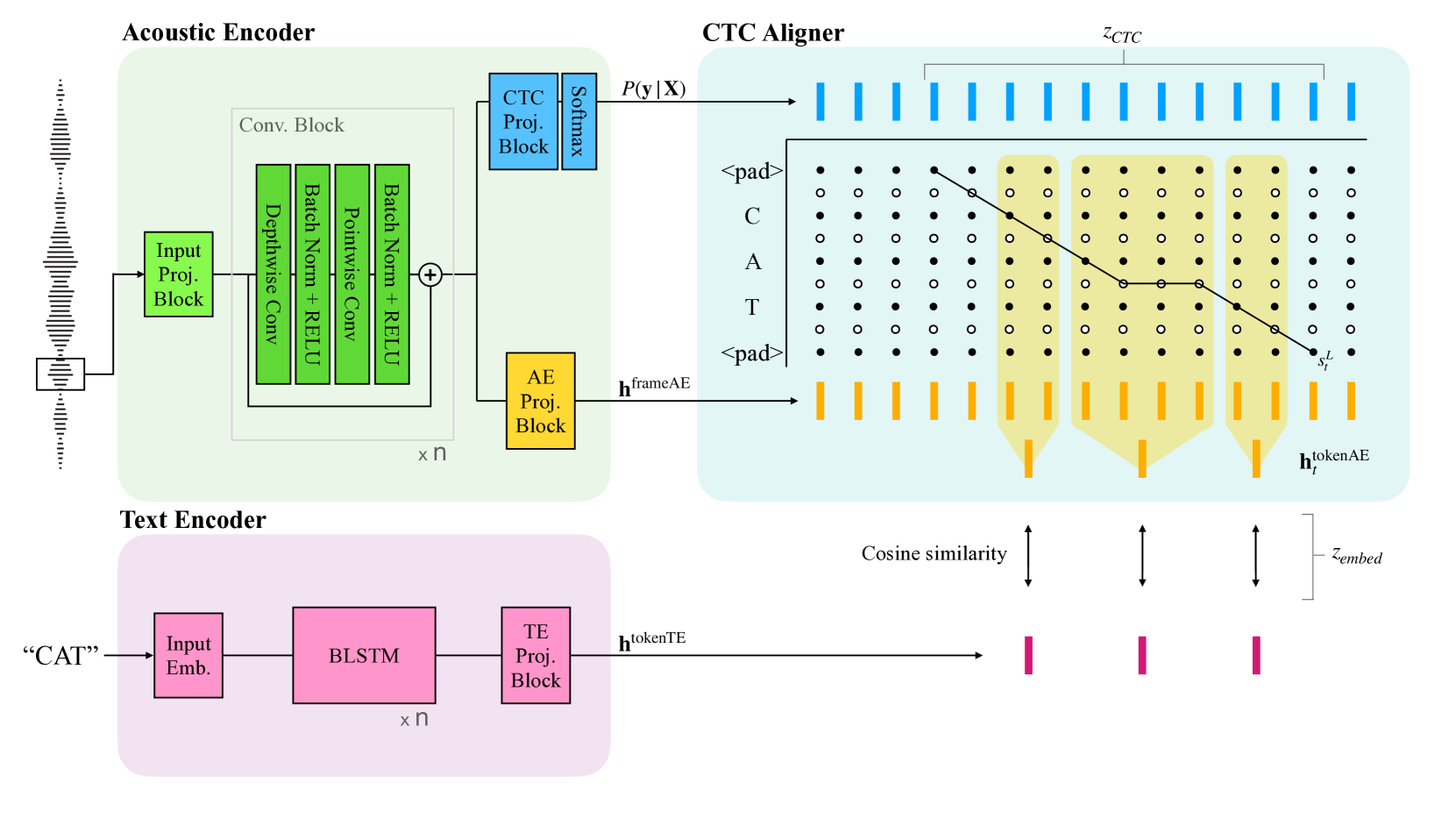
CTC-aligned Audio-Text Embedding for Streaming Open-vocabulary Keyword Spotting
Sichen Jin, Youngmoon Jung, Seungjin Lee, Jaeyoung Roh, Changwoo Han, Hoonyoung Cho
0
0
This paper introduces a novel approach for streaming openvocabulary keyword spotting (KWS) with text-based keyword enrollment. For every input frame, the proposed method finds the optimal alignment ending at the frame using connectionist temporal classification (CTC) and aggregates the frame-level acoustic embedding (AE) to obtain higher-level (i.e., character, word, or phrase) AE that aligns with the text embedding (TE) of the target keyword text. After that, we calculate the similarity of the aggregated AE and the TE. To the best of our knowledge, this is the first attempt to dynamically align the audio and the keyword text on-the-fly to attain the joint audio-text embedding for KWS. Despite operating in a streaming fashion, our approach achieves competitive performance on the LibriPhrase dataset compared to the non-streaming methods with a mere 155K model parameters and a decoding algorithm with time complexity O(U), where U is the length of the target keyword at inference time.
6/13/2024
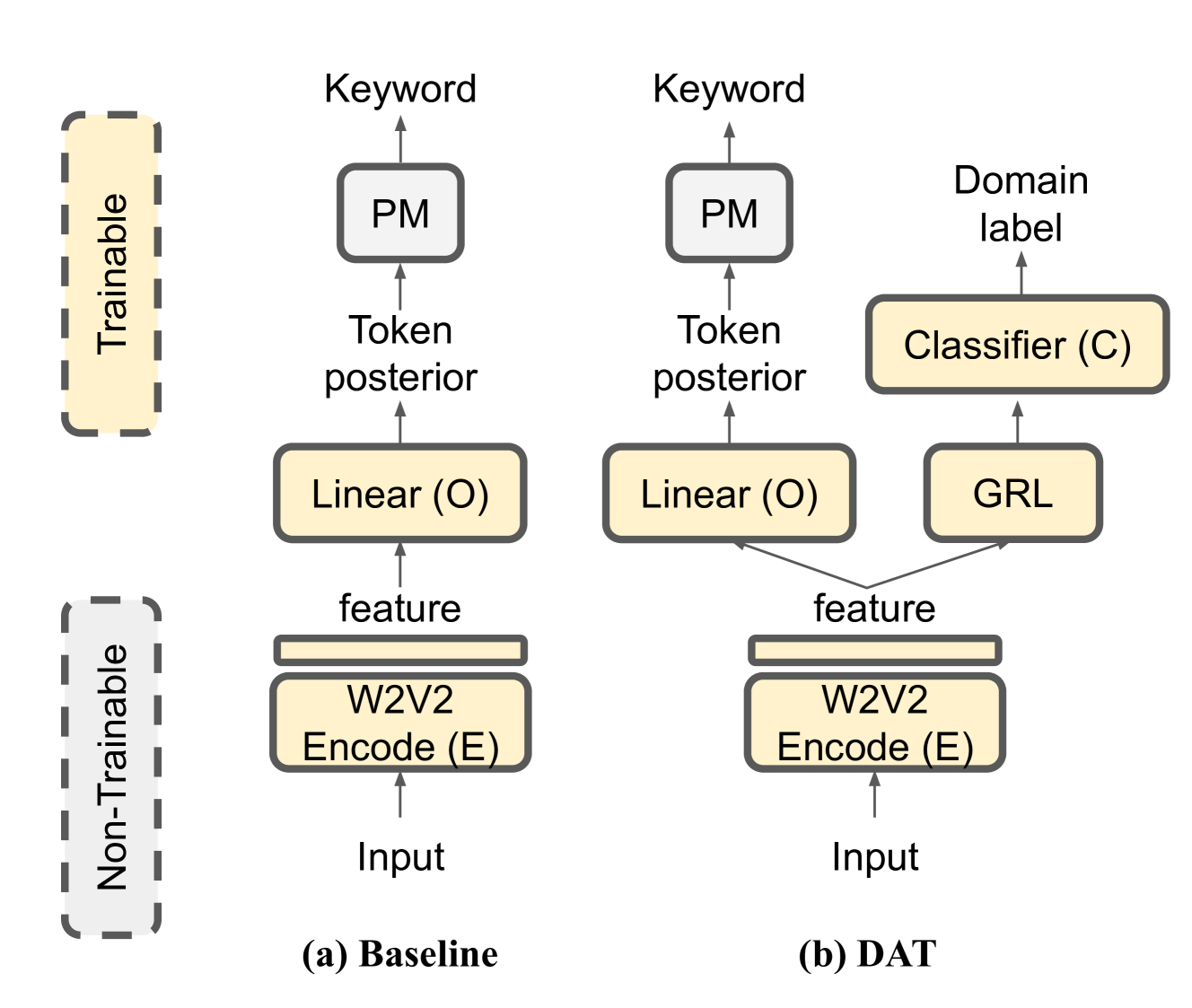
Language-Universal Speech Attributes Modeling for Zero-Shot Multilingual Spoken Keyword Recognition
Hao Yen, Pin-Jui Ku, Sabato Marco Siniscalchi, Chin-Hui Lee
0
0
We propose a novel language-universal approach to end-to-end automatic spoken keyword recognition (SKR) leveraging upon (i) a self-supervised pre-trained model, and (ii) a set of universal speech attributes (manner and place of articulation). Specifically, Wav2Vec2.0 is used to generate robust speech representations, followed by a linear output layer to produce attribute sequences. A non-trainable pronunciation model then maps sequences of attributes into spoken keywords in a multilingual setting. Experiments on the Multilingual Spoken Words Corpus show comparable performances to character- and phoneme-based SKR in seen languages. The inclusion of domain adversarial training (DAT) improves the proposed framework, outperforming both character- and phoneme-based SKR approaches with 13.73% and 17.22% relative word error rate (WER) reduction in seen languages, and achieves 32.14% and 19.92% WER reduction for unseen languages in zero-shot settings.
6/5/2024

MM-KWS: Multi-modal Prompts for Multilingual User-defined Keyword Spotting
Zhiqi Ai, Zhiyong Chen, Shugong Xu
0
0
In this paper, we propose MM-KWS, a novel approach to user-defined keyword spotting leveraging multi-modal enrollments of text and speech templates. Unlike previous methods that focus solely on either text or speech features, MM-KWS extracts phoneme, text, and speech embeddings from both modalities. These embeddings are then compared with the query speech embedding to detect the target keywords. To ensure the applicability of MM-KWS across diverse languages, we utilize a feature extractor incorporating several multilingual pre-trained models. Subsequently, we validate its effectiveness on Mandarin and English tasks. In addition, we have integrated advanced data augmentation tools for hard case mining to enhance MM-KWS in distinguishing confusable words. Experimental results on the LibriPhrase and WenetPhrase datasets demonstrate that MM-KWS outperforms prior methods significantly.
6/12/2024