MMTE: Corpus and Metrics for Evaluating Machine Translation Quality of Metaphorical Language
2406.13698
0
0

Abstract
Machine Translation (MT) has developed rapidly since the release of Large Language Models and current MT evaluation is performed through comparison with reference human translations or by predicting quality scores from human-labeled data. However, these mainstream evaluation methods mainly focus on fluency and factual reliability, whilst paying little attention to figurative quality. In this paper, we investigate the figurative quality of MT and propose a set of human evaluation metrics focused on the translation of figurative language. We additionally present a multilingual parallel metaphor corpus generated by post-editing. Our evaluation protocol is designed to estimate four aspects of MT: Metaphorical Equivalence, Emotion, Authenticity, and Quality. In doing so, we observe that translations of figurative expressions display different traits from literal ones.
Create account to get full access
Overview
- This paper introduces the MMTE corpus, a dataset for evaluating the quality of machine translations of metaphorical language.
- The authors also propose new evaluation metrics specifically designed to assess how well machine translation models handle metaphors.
- The goal is to address the challenge of accurately evaluating machine translation of non-literal language, which is important for real-world applications.
Plain English Explanation
The paper focuses on the challenge of evaluating how well machine translation (MT) models handle metaphorical language. Metaphors are expressions where the literal meaning is different from the intended meaning, such as "time is money." Accurately translating metaphors between languages is difficult for MT systems, as the meaning goes beyond just the individual words.
To address this, the researchers created the MMTE corpus, a new dataset of sentences containing metaphors, along with reference translations. This provides a way to specifically test how MT models perform on metaphorical language, rather than just overall translation quality.
Additionally, the authors propose new evaluation metrics designed to measure how well an MT system handles metaphors. These metrics go beyond just looking at literal word-for-word translation accuracy, and instead focus on capturing the transfer of the metaphorical meaning.
The goal is to provide more targeted and meaningful ways to assess MT quality, especially for real-world applications where handling non-literal language is important, such as in business, literature, or social media. By developing specialized datasets and metrics, the researchers aim to drive progress in this challenging area of machine translation.
Technical Explanation
The paper introduces the MMTE (Metaphor Machine Translation Evaluation) corpus, a new dataset for evaluating machine translation of metaphorical language. The corpus contains over 10,000 metaphorical sentences in English, along with high-quality human translations into 7 other languages (Chinese, French, German, Italian, Japanese, Portuguese, and Spanish).
To create the corpus, the authors leveraged existing metaphor datasets and had linguists manually annotate and translate the sentences. This resulted in a diverse set of metaphors covering a range of topics and linguistic structures.
In addition to the corpus, the paper proposes several new evaluation metrics for assessing MT performance on metaphorical language:
- Textual Similarity as Key Metric for Machine Translation: Measures the semantic similarity between the translated metaphor and a reference translation, going beyond just lexical overlap.
- Exploring Correlation between Human and Machine Evaluation of Simultaneous Interpretation: Compares the MT output to human judgments of translation quality for metaphors.
- Can Automatic Metrics Assess High-Quality Translations: Evaluates how well automatic metrics correlate with human assessments of metaphor translation.
- METAL: Towards Multilingual Meta-Evaluation: Extends the metrics to handle multiple target languages.
The authors demonstrate the usefulness of the MMTE corpus and their proposed metrics through experiments evaluating several state-of-the-art MT models. The results show that these models struggle to accurately translate metaphorical language, highlighting the need for more specialized evaluation techniques and model fine-tuning.
Critical Analysis
The MMTE corpus and evaluation metrics represent an important step forward in assessing machine translation quality, particularly for handling non-literal language. Metaphors are a ubiquitous part of human communication, so the ability to accurately translate them is crucial for real-world MT applications.
However, the authors acknowledge several limitations of their work. The MMTE corpus, while sizable, may not capture the full diversity of metaphors used in natural language. Additionally, the manual annotation and translation process introduces the potential for human bias or error.
The proposed metrics also have room for improvement. While they aim to go beyond simple lexical matching, they may still struggle to fully capture the nuanced semantic and pragmatic aspects of metaphor translation. Further research is needed to develop even more sophisticated evaluation techniques.
It would also be valuable to see the MMTE corpus and metrics applied to a wider range of MT models, including multilingual and multimodal systems. Evaluating how well these models handle metaphors could uncover additional insights and areas for improvement.
Overall, this work makes an important contribution to the field of machine translation, highlighting the need for specialized evaluation techniques and datasets to drive progress in this challenging area. By continuing to refine these tools, researchers can work towards developing MT systems that can accurately translate the full richness of human language, including its metaphorical aspects.
Conclusion
The MMTE corpus and associated evaluation metrics introduced in this paper represent a significant advance in assessing the quality of machine translation for metaphorical language. By providing a targeted dataset and specialized metrics, the authors have laid the groundwork for more meaningful evaluation of how well MT models handle non-literal expressions.
This is an important step forward, as the ability to accurately translate metaphors is crucial for the real-world deployment of machine translation systems. The researchers have demonstrated that current state-of-the-art MT models still struggle with this task, highlighting the need for further advancements.
Overall, this work contributes valuable tools and insights that can help drive progress in machine translation, ultimately leading to systems that can more effectively bridge the gap between human and machine language understanding. As the field continues to evolve, the MMTE corpus and evaluation metrics can serve as a benchmark for evaluating and improving the metaphor translation capabilities of future MT models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
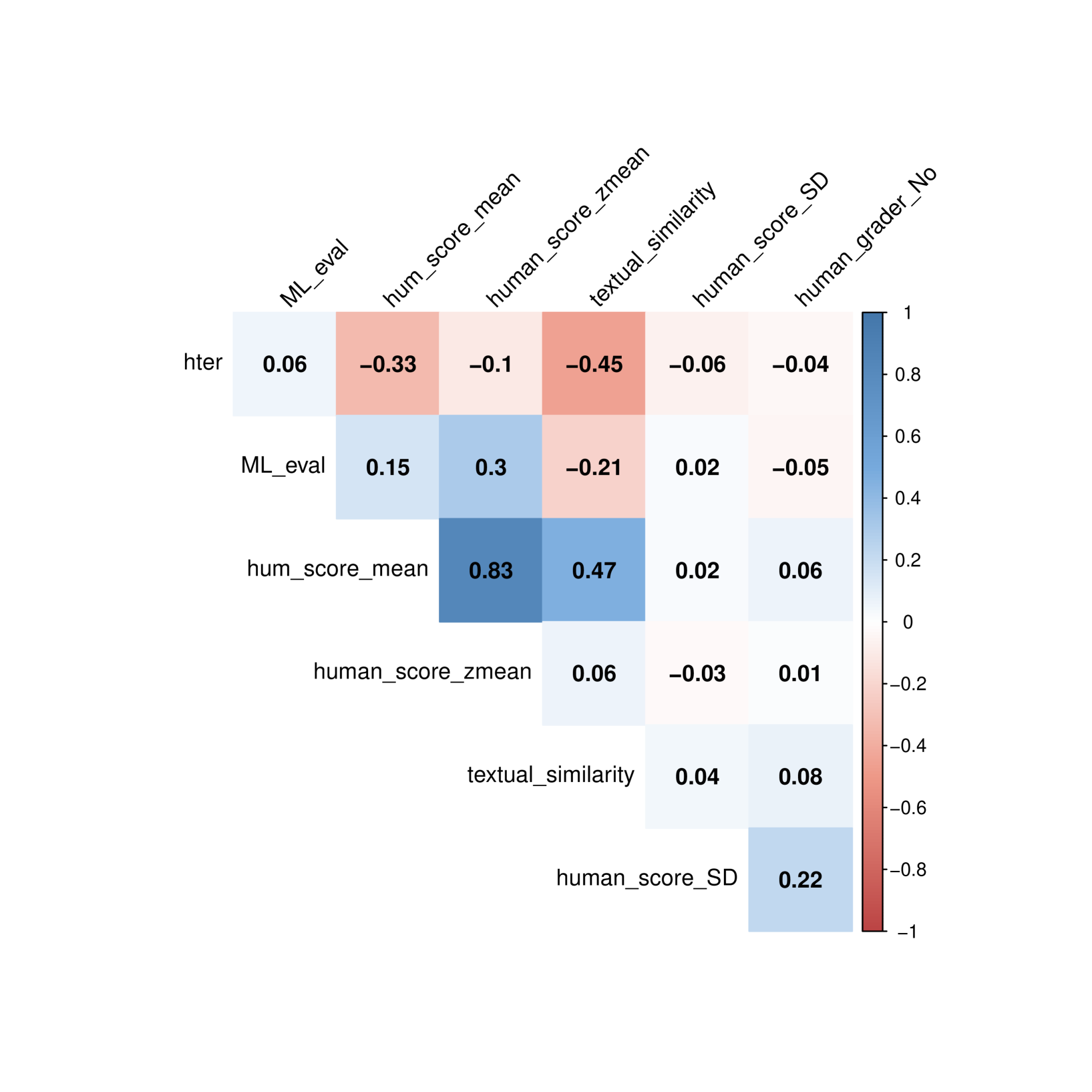
Textual Similarity as a Key Metric in Machine Translation Quality Estimation
Kun Sun, Rong Wang
0
0
Machine Translation (MT) Quality Estimation (QE) assesses translation reliability without reference texts. This study introduces textual similarity as a new metric for QE, using sentence transformers and cosine similarity to measure semantic closeness. Analyzing data from the MLQE-PE dataset, we found that textual similarity exhibits stronger correlations with human scores than traditional metrics (hter, model evaluation, sentence probability etc.). Employing GAMMs as a statistical tool, we demonstrated that textual similarity consistently outperforms other metrics across multiple language pairs in predicting human scores. We also found that hter actually failed to predict human scores in QE. Our findings highlight the effectiveness of textual similarity as a robust QE metric, recommending its integration with other metrics into QE frameworks and MT system training for improved accuracy and usability.
7/2/2024

Exploring the Correlation between Human and Machine Evaluation of Simultaneous Speech Translation
Xiaoman Wang, Claudio Fantinuoli
0
0
Assessing the performance of interpreting services is a complex task, given the nuanced nature of spoken language translation, the strategies that interpreters apply, and the diverse expectations of users. The complexity of this task become even more pronounced when automated evaluation methods are applied. This is particularly true because interpreted texts exhibit less linearity between the source and target languages due to the strategies employed by the interpreter. This study aims to assess the reliability of automatic metrics in evaluating simultaneous interpretations by analyzing their correlation with human evaluations. We focus on a particular feature of interpretation quality, namely translation accuracy or faithfulness. As a benchmark we use human assessments performed by language experts, and evaluate how well sentence embeddings and Large Language Models correlate with them. We quantify semantic similarity between the source and translated texts without relying on a reference translation. The results suggest GPT models, particularly GPT-3.5 with direct prompting, demonstrate the strongest correlation with human judgment in terms of semantic similarity between source and target texts, even when evaluating short textual segments. Additionally, the study reveals that the size of the context window has a notable impact on this correlation.
6/17/2024

Can Automatic Metrics Assess High-Quality Translations?
Sweta Agrawal, Ant'onio Farinhas, Ricardo Rei, Andr'e F. T. Martins
0
0
Automatic metrics for evaluating translation quality are typically validated by measuring how well they correlate with human assessments. However, correlation methods tend to capture only the ability of metrics to differentiate between good and bad source-translation pairs, overlooking their reliability in distinguishing alternative translations for the same source. In this paper, we confirm that this is indeed the case by showing that current metrics are insensitive to nuanced differences in translation quality. This effect is most pronounced when the quality is high and the variance among alternatives is low. Given this finding, we shift towards detecting high-quality correct translations, an important problem in practical decision-making scenarios where a binary check of correctness is prioritized over a nuanced evaluation of quality. Using the MQM framework as the gold standard, we systematically stress-test the ability of current metrics to identify translations with no errors as marked by humans. Our findings reveal that current metrics often over or underestimate translation quality, indicating significant room for improvement in automatic evaluation methods.
5/29/2024

New!Evaluating Automatic Metrics with Incremental Machine Translation Systems
Guojun Wu, Shay B. Cohen, Rico Sennrich
0
0
We introduce a dataset comprising commercial machine translations, gathered weekly over six years across 12 translation directions. Since human A/B testing is commonly used, we assume commercial systems improve over time, which enables us to evaluate machine translation (MT) metrics based on their preference for more recent translations. Our study confirms several previous findings in MT metrics research and demonstrates the dataset's value as a testbed for metric evaluation. We release our code at https://github.com/gjwubyron/Evo
7/4/2024