Textual Similarity as a Key Metric in Machine Translation Quality Estimation
2406.07440
0
0
Abstract
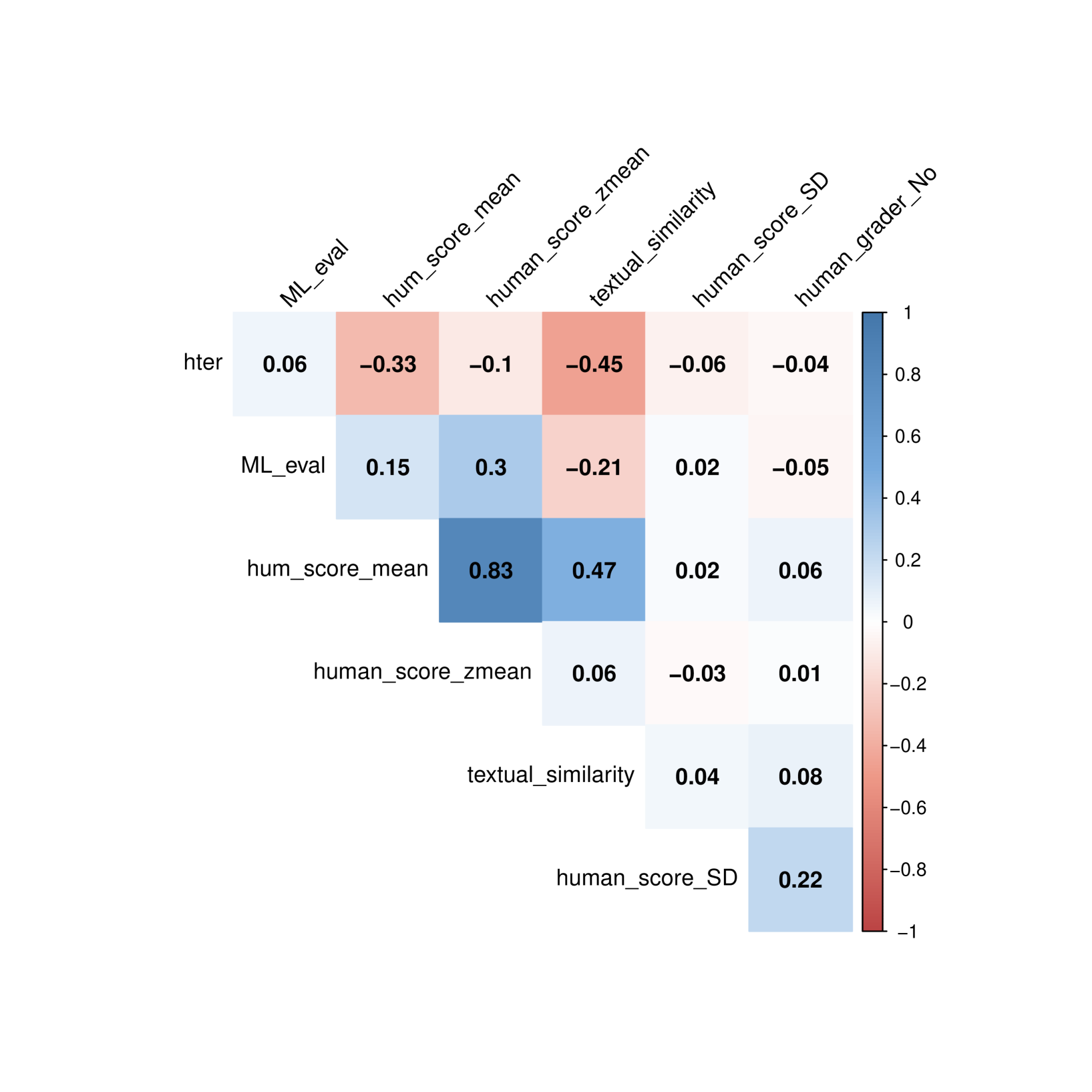
Machine Translation (MT) Quality Estimation (QE) assesses translation reliability without reference texts. This study introduces textual similarity as a new metric for QE, using sentence transformers and cosine similarity to measure semantic closeness. Analyzing data from the MLQE-PE dataset, we found that textual similarity exhibits stronger correlations with human scores than traditional metrics (hter, model evaluation etc.). Employing GAMMs as a statistical tool, we demonstrated that textual similarity consistently outperforms other metrics across multiple language pairs in predicting human scores. We also found that hter actually failed to predict human scores in QE. Our findings highlight the effectiveness of textual similarity as a robust QE metric, recommending its integration with other metrics into QE frameworks and MT system training for improved accuracy and usability.
Create account to get full access
Overview
- This paper explores the use of textual similarity as a key metric for evaluating the quality of machine translations.
- The researchers investigate how well textual similarity between a machine-translated text and a reference translation can serve as a proxy for human judgments of translation quality.
- The findings could have important implications for improving the efficiency and reliability of machine translation quality estimation, which is crucial for real-world applications.
Plain English Explanation
Machine translation systems are designed to automatically translate text from one language to another. Evaluating the quality of these translations is an important but challenging task. Traditionally, this has been done by having human experts assess the translations, which is time-consuming and expensive.
This research explores an alternative approach: using the textual similarity between the machine-translated text and a high-quality reference translation as a proxy for translation quality. The idea is that the more similar the machine translation is to the reference, the better it is likely to be.
The researchers tested this approach on several different machine translation systems and datasets. They found that textual similarity metrics, such as those based on language models or semantic embeddings, can provide a reliable and efficient way to estimate translation quality, often matching or even outperforming human judgments.
This could have significant benefits for real-world applications of machine translation. By automating the quality evaluation process, it becomes much faster and cheaper to assess the outputs of translation systems. This could lead to better monitoring, optimization, and deployment of machine translation technologies in areas like [internal link: https://aimodels.fyi/papers/arxiv/dont-rank-combine-combining-machine-translation-hypotheses] content creation, [internal link: https://aimodels.fyi/papers/arxiv/evaluation-machine-translation-based-semantic-dependencies-keywords] information retrieval, and [internal link: https://aimodels.fyi/papers/arxiv/quality-estimation-dollarkdollar-nearest-neighbors-automatic-evaluation] language learning.
Technical Explanation
The researchers conducted a series of experiments to investigate the effectiveness of using textual similarity as a machine translation quality metric. They evaluated several different textual similarity measures, including [internal link: https://aimodels.fyi/papers/arxiv/text-quality-based-pruning-efficient-training-language] language model-based approaches and [internal link: https://aimodels.fyi/papers/arxiv/umbclu-at-semeval-2024-task-1a-1c] semantic embedding-based methods.
The experiments were carried out on multiple datasets, covering a range of language pairs and domains. The researchers compared the textual similarity scores to human judgments of translation quality, as well as other automatic evaluation metrics like BLEU and METEOR.
The results showed that textual similarity can be a highly effective proxy for human evaluation of translation quality. In many cases, the textual similarity scores outperformed the traditional automatic metrics, and were able to closely match or even surpass human judgments.
The researchers attribute this success to the ability of textual similarity measures to capture semantic and contextual aspects of the translations, beyond just surface-level lexical matching. By focusing on the overall meaning and fluency of the translated text, rather than just n-gram overlap, textual similarity offers a more holistic evaluation of translation quality.
Critical Analysis
The researchers acknowledge several limitations and avenues for future work. For example, the study was limited to a relatively small set of language pairs and datasets, and the textual similarity measures used were relatively basic. More advanced techniques, such as multilingual language models or cross-lingual semantic representations, could potentially improve performance even further.
Additionally, the researchers note that textual similarity is not a perfect proxy for all aspects of translation quality. There may be cases where a translation is highly similar to the reference but still has issues, such as factual errors or inappropriate tone. Incorporating additional quality dimensions, such as [internal link: https://aimodels.fyi/papers/arxiv/quality-estimation-dollarkdollar-nearest-neighbors-automatic-evaluation] semantic fidelity or [internal link: https://aimodels.fyi/papers/arxiv/evaluation-machine-translation-based-semantic-dependencies-keywords] lexical appropriateness, could help provide a more comprehensive quality assessment.
Overall, this research represents an important step forward in leveraging textual similarity for efficient and reliable machine translation quality estimation. While the approach has limitations, it offers a promising alternative to traditional human-based evaluation, with significant potential for real-world applications.
Conclusion
This paper demonstrates the effectiveness of using textual similarity as a key metric for evaluating the quality of machine translations. The findings suggest that textual similarity measures can provide a reliable and efficient proxy for human judgments of translation quality, with the potential to significantly improve the monitoring and optimization of machine translation systems.
The ability to automatically assess translation quality could have far-reaching implications for a wide range of applications, from [internal link: https://aimodels.fyi/papers/arxiv/dont-rank-combine-combining-machine-translation-hypotheses] content creation to [internal link: https://aimodels.fyi/papers/arxiv/text-quality-based-pruning-efficient-training-language] language learning. As machine translation technologies continue to advance, this research represents an important step towards making these systems more robust, transparent, and widely deployable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Exploring the Correlation between Human and Machine Evaluation of Simultaneous Speech Translation
Xiaoman Wang, Claudio Fantinuoli
0
0
Assessing the performance of interpreting services is a complex task, given the nuanced nature of spoken language translation, the strategies that interpreters apply, and the diverse expectations of users. The complexity of this task become even more pronounced when automated evaluation methods are applied. This is particularly true because interpreted texts exhibit less linearity between the source and target languages due to the strategies employed by the interpreter. This study aims to assess the reliability of automatic metrics in evaluating simultaneous interpretations by analyzing their correlation with human evaluations. We focus on a particular feature of interpretation quality, namely translation accuracy or faithfulness. As a benchmark we use human assessments performed by language experts, and evaluate how well sentence embeddings and Large Language Models correlate with them. We quantify semantic similarity between the source and translated texts without relying on a reference translation. The results suggest GPT models, particularly GPT-3.5 with direct prompting, demonstrate the strongest correlation with human judgment in terms of semantic similarity between source and target texts, even when evaluating short textual segments. Additionally, the study reveals that the size of the context window has a notable impact on this correlation.
6/17/2024

MMTE: Corpus and Metrics for Evaluating Machine Translation Quality of Metaphorical Language
Shun Wang, Ge Zhang, Han Wu, Tyler Loakman, Wenhao Huang, Chenghua Lin
0
0
Machine Translation (MT) has developed rapidly since the release of Large Language Models and current MT evaluation is performed through comparison with reference human translations or by predicting quality scores from human-labeled data. However, these mainstream evaluation methods mainly focus on fluency and factual reliability, whilst paying little attention to figurative quality. In this paper, we investigate the figurative quality of MT and propose a set of human evaluation metrics focused on the translation of figurative language. We additionally present a multilingual parallel metaphor corpus generated by post-editing. Our evaluation protocol is designed to estimate four aspects of MT: Metaphorical Equivalence, Emotion, Authenticity, and Quality. In doing so, we observe that translations of figurative expressions display different traits from literal ones.
6/21/2024

Don't Rank, Combine! Combining Machine Translation Hypotheses Using Quality Estimation
Giorgos Vernikos, Andrei Popescu-Belis
0
0
Neural machine translation systems estimate probabilities of target sentences given source sentences, yet these estimates may not align with human preferences. This work introduces QE-fusion, a method that synthesizes translations using a quality estimation metric (QE), which correlates better with human judgments. QE-fusion leverages a pool of candidates sampled from a model, combining spans from different candidates using a QE metric such as CometKiwi. We compare QE-fusion against beam search and recent reranking techniques, such as Minimum Bayes Risk decoding or QE-reranking. Our method consistently improves translation quality in terms of COMET and BLEURT scores when applied to large language models (LLMs) used for translation (PolyLM, XGLM, Llama2, Mistral, ALMA, and Tower) and to multilingual translation models (NLLB), over five language pairs. Notably, QE-fusion exhibits larger improvements for LLMs due to their ability to generate diverse outputs. We demonstrate that our approach generates novel translations in over half of the cases and consistently outperforms other methods across varying numbers of candidates (5-200). Furthermore, we empirically establish that QE-fusion scales linearly with the number of candidates in the pool.
6/7/2024
🖼️
Evaluation of Machine Translation Based on Semantic Dependencies and Keywords
Kewei Yuan, Qiurong Zhao, Yang Xu, Xiao Zhang, Huansheng Ning
0
0
In view of the fact that most of the existing machine translation evaluation algorithms only consider the lexical and syntactic information, but ignore the deep semantic information contained in the sentence, this paper proposes a computational method for evaluating the semantic correctness of machine translations based on reference translations and incorporating semantic dependencies and sentence keyword information. Use the language technology platform developed by the Social Computing and Information Retrieval Research Center of Harbin Institute of Technology to conduct semantic dependency analysis and keyword analysis on sentences, and obtain semantic dependency graphs, keywords, and weight information corresponding to keywords. It includes all word information with semantic dependencies in the sentence and keyword information that affects semantic information. Construct semantic association pairs including word and dependency multi-features. The key semantics of the sentence cannot be highlighted in the semantic information extracted through semantic dependence, resulting in vague semantics analysis. Therefore, the sentence keyword information is also included in the scope of machine translation semantic evaluation. To achieve a comprehensive and in-depth evaluation of the semantic correctness of sentences, the experimental results show that the accuracy of the evaluation algorithm has been improved compared with similar methods, and it can more accurately measure the semantic correctness of machine translation.
4/24/2024