MMTryon: Multi-Modal Multi-Reference Control for High-Quality Fashion Generation

0
🛸
Sign in to get full access
Overview
- Introduces MMTryon, a multi-modal, multi-reference virtual try-on (VITON) framework
- Addresses two key issues in prior VITON methods: 1) Limited support for multiple try-on items and customized dressing styles, 2) Dependency on category-specific segmentation models
Plain English Explanation
The paper presents MMTryon, a new system that allows you to virtually try on multiple clothing items and customize the style, like zipped/unzipped or tucked in/out. Previous virtual try-on methods were often limited to single items and couldn't handle the variety of how clothes can be worn.
MMTryon uses a clever combination of information from reference images of the clothes and text instructions about the desired style. This allows it to generate high-quality try-on results without relying on specialized clothing segmentation models, which were a common source of errors in past systems.
By supporting multi-item try-on and style customization, while also removing the segmentation dependency, MMTryon represents an important advance in virtual clothing try-on technology. It opens up new possibilities for how people can experiment with different outfits and fashion choices online.
Technical Explanation
The key innovations of MMTryon include:
-
Multi-Modality and Multi-Reference Attention: MMTryon combines garment information from reference images and dressing-style information from text instructions using a novel attention mechanism.
-
Parsing-Free Garment Encoding: To remove the reliance on category-specific segmentation models, MMTryon uses a parsing-free garment encoder that can handle try-on without explicit segmentation.
-
Scalable Data Generation Pipeline: MMTryon leverages a novel data generation pipeline to convert existing VITON datasets into a format that allows the model to be trained without requiring any explicit segmentation.
Extensive experiments on high-resolution benchmarks and in-the-wild test sets demonstrate MMTryon's superior performance over state-of-the-art VITON methods, both qualitatively and quantitatively.
Critical Analysis
While MMTryon represents an impressive advancement in virtual try-on technology, the paper acknowledges some limitations and areas for future work:
- The current model is limited to generating try-on results for a single person in the input image. Extending it to handle multiple people or dynamic scenes could be an interesting direction.
- The text-based style control is relatively coarse-grained (e.g., zipped/unzipped, tucked in/out). Enabling finer-grained control over garment deformations and interactions could further enhance the customization capabilities.
- Incorporating physical simulation or other physics-based modeling techniques could help improve the realism of the try-on results, especially for complex garment interactions.
Addressing these challenges could lead to even more powerful and user-friendly virtual try-on systems in the future.
Conclusion
The MMTryon framework introduced in this paper represents a significant advancement in multi-modal, multi-reference virtual try-on technology. By addressing key limitations of prior methods, MMTryon enables high-quality compositional try-on results that can be customized to the user's preferences. This opens up new possibilities for how people can explore and experiment with fashion online, potentially transforming the way we shop for and interact with clothes in the digital world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
0
MMTryon: Multi-Modal Multi-Reference Control for High-Quality Fashion Generation
Xujie Zhang, Ente Lin, Xiu Li, Yuxuan Luo, Michael Kampffmeyer, Xin Dong, Xiaodan Liang
This paper introduces MMTryon, a multi-modal multi-reference VIrtual Try-ON (VITON) framework, which can generate high-quality compositional try-on results by taking a text instruction and multiple garment images as inputs. Our MMTryon addresses three problems overlooked in prior literature: 1) Support of multiple try-on items. Existing methods are commonly designed for single-item try-on tasks (e.g., upper/lower garments, dresses). 2)Specification of dressing style. Existing methods are unable to customize dressing styles based on instructions (e.g., zipped/unzipped, tuck-in/tuck-out, etc.) 3) Segmentation Dependency. They further heavily rely on category-specific segmentation models to identify the replacement regions, with segmentation errors directly leading to significant artifacts in the try-on results. To address the first two issues, our MMTryon introduces a novel multi-modality and multi-reference attention mechanism to combine the garment information from reference images and dressing-style information from text instructions. Besides, to remove the segmentation dependency, MMTryon uses a parsing-free garment encoder and leverages a novel scalable data generation pipeline to convert existing VITON datasets to a form that allows MMTryon to be trained without requiring any explicit segmentation. Extensive experiments on high-resolution benchmarks and in-the-wild test sets demonstrate MMTryon's superiority over existing SOTA methods both qualitatively and quantitatively. MMTryon's impressive performance on multi-item and style-controllable virtual try-on scenarios and its ability to try on any outfit in a large variety of scenarios from any source image, opens up a new avenue for future investigation in the fashion community.
Read more5/29/2024
🏅
0
MV-VTON: Multi-View Virtual Try-On with Diffusion Models
Haoyu Wang, Zhilu Zhang, Donglin Di, Shiliang Zhang, Wangmeng Zuo
The goal of image-based virtual try-on is to generate an image of the target person naturally wearing the given clothing. However, existing methods solely focus on the frontal try-on using the frontal clothing. When the views of the clothing and person are significantly inconsistent, particularly when the person's view is non-frontal, the results are unsatisfactory. To address this challenge, we introduce Multi-View Virtual Try-ON (MV-VTON), which aims to reconstruct the dressing results from multiple views using the given clothes. Given that single-view clothes provide insufficient information for MV-VTON, we instead employ two images, i.e., the frontal and back views of the clothing, to encompass the complete view as much as possible. Moreover, we adopt diffusion models that have demonstrated superior abilities to perform our MV-VTON. In particular, we propose a view-adaptive selection method where hard-selection and soft-selection are applied to the global and local clothing feature extraction, respectively. This ensures that the clothing features are roughly fit to the person's view. Subsequently, we suggest joint attention blocks to align and fuse clothing features with person features. Additionally, we collect a MV-VTON dataset MVG, in which each person has multiple photos with diverse views and poses. Experiments show that the proposed method not only achieves state-of-the-art results on MV-VTON task using our MVG dataset, but also has superiority on frontal-view virtual try-on task using VITON-HD and DressCode datasets. Codes and datasets are publicly released at https://github.com/hywang2002/MV-VTON .
Read more9/5/2024
0
M&M VTO: Multi-Garment Virtual Try-On and Editing
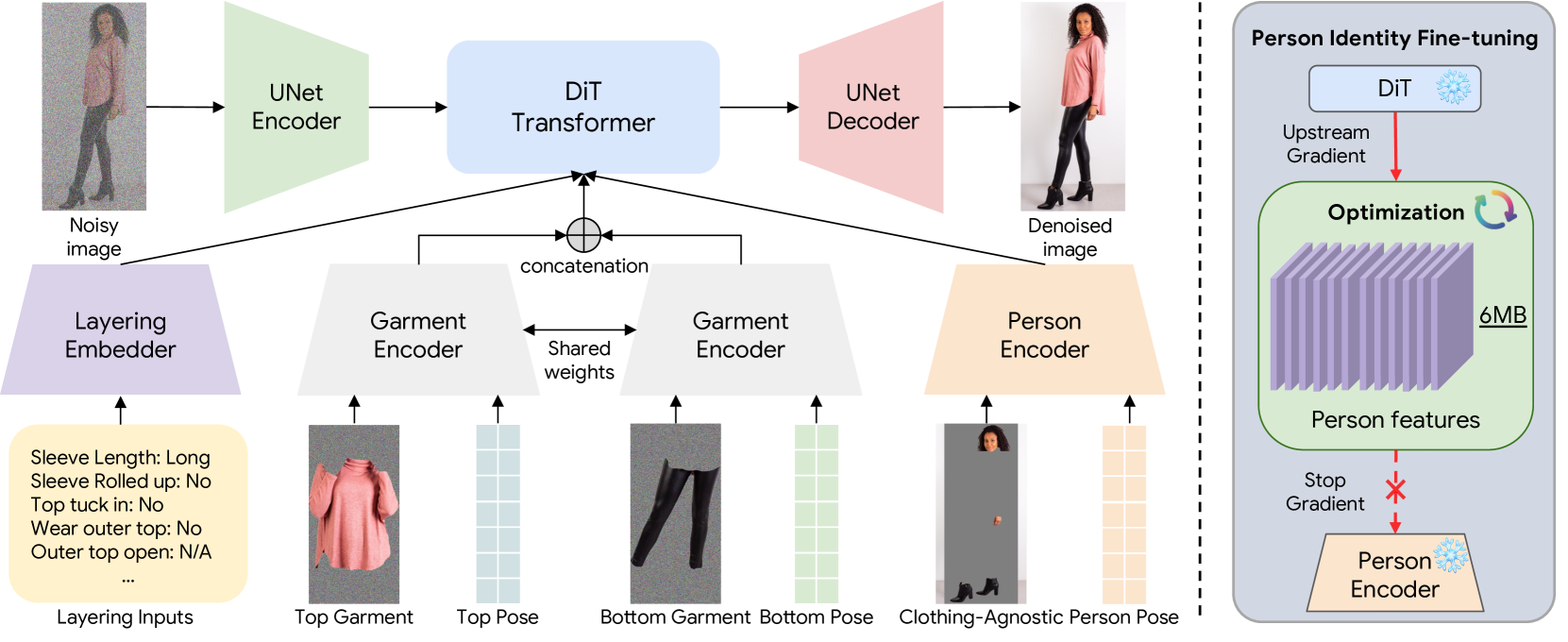
Luyang Zhu, Yingwei Li, Nan Liu, Hao Peng, Dawei Yang, Ira Kemelmacher-Shlizerman
We present M&M VTO, a mix and match virtual try-on method that takes as input multiple garment images, text description for garment layout and an image of a person. An example input includes: an image of a shirt, an image of a pair of pants, rolled sleeves, shirt tucked in, and an image of a person. The output is a visualization of how those garments (in the desired layout) would look like on the given person. Key contributions of our method are: 1) a single stage diffusion based model, with no super resolution cascading, that allows to mix and match multiple garments at 1024x512 resolution preserving and warping intricate garment details, 2) architecture design (VTO UNet Diffusion Transformer) to disentangle denoising from person specific features, allowing for a highly effective finetuning strategy for identity preservation (6MB model per individual vs 4GB achieved with, e.g., dreambooth finetuning); solving a common identity loss problem in current virtual try-on methods, 3) layout control for multiple garments via text inputs specifically finetuned over PaLI-3 for virtual try-on task. Experimental results indicate that M&M VTO achieves state-of-the-art performance both qualitatively and quantitatively, as well as opens up new opportunities for virtual try-on via language-guided and multi-garment try-on.
Read more6/10/2024
🔄
0
Smart Fitting Room: A One-stop Framework for Matching-aware Virtual Try-on
Mingzhe Yu, Yunshan Ma, Lei Wu, Kai Cheng, Xue Li, Lei Meng, Tat-Seng Chua
The development of virtual try-on has revolutionized online shopping by allowing customers to visualize themselves in various fashion items, thus extending the in-store try-on experience to the cyber space. Although virtual try-on has attracted considerable research initiatives, existing systems only focus on the quality of image generation, overlooking whether the fashion item is a good match to the given person and clothes. Recognizing this gap, we propose to design a one-stop Smart Fitting Room, with the novel formulation of matching-aware virtual try-on. Following this formulation, we design a Hybrid Matching-aware Virtual Try-On Framework (HMaVTON), which combines retrieval-based and generative methods to foster a more personalized virtual try-on experience. This framework integrates a hybrid mix-and-match module and an enhanced virtual try-on module. The former can recommend fashion items available on the platform to boost sales and generate clothes that meets the diverse tastes of consumers. The latter provides high-quality try-on effects, delivering a one-stop shopping service. To validate the effectiveness of our approach, we enlist the expertise of fashion designers for a professional evaluation, assessing the rationality and diversity of the clothes combinations and conducting an evaluation matrix analysis. Our method significantly enhances the practicality of virtual try-on. The code is available at https://github.com/Yzcreator/HMaVTON.
Read more4/23/2024