MobileUNETR: A Lightweight End-To-End Hybrid Vision Transformer For Efficient Medical Image Segmentation

0

Sign in to get full access
Overview
- MobileUNETR is a lightweight and efficient hybrid vision transformer for medical image segmentation.
- It combines the strengths of convolutional neural networks (CNNs) and transformers to achieve high performance while maintaining a small model size.
- The paper proposes a novel architectural design and training strategy to address the challenges of efficient medical image segmentation.
Plain English Explanation
MobileUNETR: A Lightweight End-To-End Hybrid Vision Transformer For Efficient Medical Image Segmentation is a research paper that introduces a new approach to medical image segmentation using a combination of convolutional neural networks (CNNs) and transformers.
Medical image segmentation is the process of dividing an image, such as an MRI or CT scan, into different regions or structures that correspond to specific organs or tissues. This is an important task in medical imaging, as it can help doctors and researchers better understand and diagnose various health conditions.
Traditional CNN-based models have been widely used for medical image segmentation, but they can be computationally intensive and have limited ability to capture long-range dependencies in the images. Transformers, on the other hand, are a newer type of neural network that is better at handling long-range dependencies, but they can be less efficient and have a larger model size.
The researchers behind MobileUNETR aimed to create a model that combines the strengths of both CNNs and transformers, while minimizing the weaknesses. They developed a lightweight, end-to-end hybrid architecture that leverages the local feature extraction capabilities of CNNs and the global context modeling of transformers.
The key innovation in MobileUNETR is the use of a novel architectural design and training strategy that allows the model to achieve high performance while maintaining a small model size. This makes it particularly well-suited for deployment on resource-constrained devices, such as those used in clinical settings.
Technical Explanation
MobileUNETR: A Lightweight End-To-End Hybrid Vision Transformer For Efficient Medical Image Segmentation proposes a novel hybrid architecture that combines the strengths of convolutional neural networks (CNNs) and transformers for efficient medical image segmentation.
The authors recognize the limitations of traditional CNN-based models, which can be computationally intensive and struggle to capture long-range dependencies in medical images. Transformers, on the other hand, excel at modeling these long-range dependencies but can be less efficient and have a larger model size.
To address these challenges, the researchers designed a lightweight, end-to-end hybrid architecture called MobileUNETR. The key components of this architecture include:
- CNN Encoder: A CNN-based encoder that efficiently extracts local features from the input image.
- Transformer Decoder: A transformer-based decoder that effectively models global context and long-range dependencies.
- Lightweight Design: The use of depthwise separable convolutions and other efficient building blocks to reduce the overall model size and computational complexity.
- Integrated Training Strategy: A novel training strategy that jointly optimizes the CNN encoder and transformer decoder, allowing them to learn complementary features.
The authors conducted extensive experiments on various medical image segmentation datasets, including cardiac, brain, and abdominal scans. They compared MobileUNETR to state-of-the-art CNN-based and transformer-based models, and demonstrated that their approach achieves superior performance while maintaining a significantly smaller model size.
Critical Analysis
The MobileUNETR: A Lightweight End-To-End Hybrid Vision Transformer For Efficient Medical Image Segmentation paper presents a well-designed and thoroughly evaluated hybrid architecture for efficient medical image segmentation. The authors have clearly identified the limitations of existing approaches and have proposed a novel solution that effectively combines the strengths of CNNs and transformers.
One potential limitation of the study is the reliance on a limited number of medical image segmentation datasets. While the researchers have demonstrated the efficacy of MobileUNETR on several common datasets, it would be valuable to test the model on a broader range of medical imaging modalities and disease contexts to further validate its generalizability.
Additionally, the paper does not provide a detailed analysis of the model's interpretability or the ability to understand the underlying decision-making process. As medical AI systems are expected to be transparent and explainable, future research could explore mechanisms to improve the interpretability of the MobileUNETR architecture.
Despite these minor limitations, the MobileUNETR: A Lightweight End-To-End Hybrid Vision Transformer For Efficient Medical Image Segmentation paper represents a significant contribution to the field of efficient medical image segmentation. The proposed approach demonstrates the potential of hybrid architectures to balance performance and model complexity, paving the way for more deployable and clinically-relevant AI systems in the healthcare domain.
Conclusion
MobileUNETR: A Lightweight End-To-End Hybrid Vision Transformer For Efficient Medical Image Segmentation introduces a novel hybrid architecture that combines the strengths of convolutional neural networks (CNNs) and transformers to address the challenges of efficient medical image segmentation. The researchers have developed a lightweight, end-to-end model that achieves superior performance while maintaining a small model size, making it well-suited for deployment on resource-constrained devices.
The key innovations of MobileUNETR include its unique architectural design and integrated training strategy, which allow the model to effectively capture both local and global features in medical images. The extensive experimental evaluation demonstrated the model's superiority over state-of-the-art CNN-based and transformer-based approaches, highlighting its potential to contribute to the advancement of medical AI systems.
While the paper presents a promising solution, future research could explore ways to further improve the model's interpretability and generalizability across a broader range of medical imaging modalities and disease contexts. Overall, the MobileUNETR: A Lightweight End-To-End Hybrid Vision Transformer For Efficient Medical Image Segmentation paper represents a significant step forward in the pursuit of efficient and effective medical image segmentation technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MobileUNETR: A Lightweight End-To-End Hybrid Vision Transformer For Efficient Medical Image Segmentation
Shehan Perera, Yunus Erzurumlu, Deepak Gulati, Alper Yilmaz
Skin cancer segmentation poses a significant challenge in medical image analysis. Numerous existing solutions, predominantly CNN-based, face issues related to a lack of global contextual understanding. Alternatively, some approaches resort to large-scale Transformer models to bridge the global contextual gaps, but at the expense of model size and computational complexity. Finally many Transformer based approaches rely primarily on CNN based decoders overlooking the benefits of Transformer based decoding models. Recognizing these limitations, we address the need efficient lightweight solutions by introducing MobileUNETR, which aims to overcome the performance constraints associated with both CNNs and Transformers while minimizing model size, presenting a promising stride towards efficient image segmentation. MobileUNETR has 3 main features. 1) MobileUNETR comprises of a lightweight hybrid CNN-Transformer encoder to help balance local and global contextual feature extraction in an efficient manner; 2) A novel hybrid decoder that simultaneously utilizes low-level and global features at different resolutions within the decoding stage for accurate mask generation; 3) surpassing large and complex architectures, MobileUNETR achieves superior performance with 3 million parameters and a computational complexity of 1.3 GFLOP resulting in 10x and 23x reduction in parameters and FLOPS, respectively. Extensive experiments have been conducted to validate the effectiveness of our proposed method on four publicly available skin lesion segmentation datasets, including ISIC 2016, ISIC 2017, ISIC 2018, and PH2 datasets. The code will be publicly available at: https://github.com/OSUPCVLab/MobileUNETR.git
Read more9/6/2024

0
LV-UNet: A Lightweight and Vanilla Model for Medical Image Segmentation
Juntao Jiang, Mengmeng Wang, Huizhong Tian, Lingbo Cheng, Yong Liu
Although the progress made by large models in computer vision, optimization challenges, the complexity of transformer models, computational limitations, and the requirements of practical applications call for simpler designs in model architecture for medical image segmentation, especially in mobile medical devices that require lightweight and deployable models with real-time performance. However, some of the current lightweight models exhibit poor robustness across different datasets, which hinders their broader adoption. This paper proposes a lightweight and vanilla model called LV-UNet, which effectively utilizes pre-trained MobileNetv3-Large models and introduces fusible modules. It can be trained using an improved deep training strategy and switched to deployment mode during inference, reducing both parameter count and computational load. Experiments are conducted on ISIC 2016, BUSI, CVC- ClinicDB, CVC-ColonDB, and Kvair-SEG datasets, achieving better performance compared to the state-of-the-art and classic models.
Read more9/2/2024
0
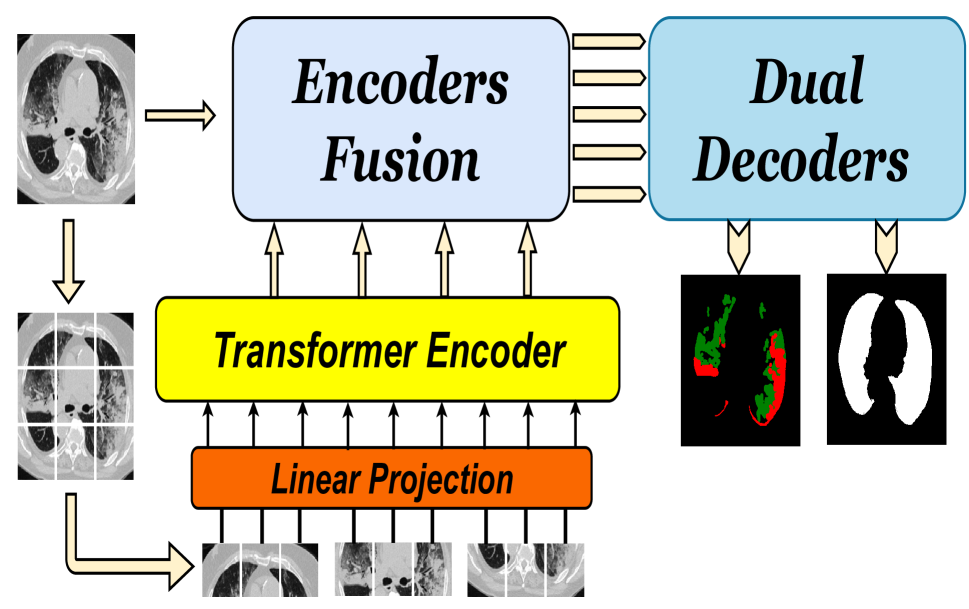
D-TrAttUnet: Toward Hybrid CNN-Transformer Architecture for Generic and Subtle Segmentation in Medical Images
Fares Bougourzi, Fadi Dornaika, Cosimo Distante, Abdelmalik Taleb-Ahmed
Over the past two decades, machine analysis of medical imaging has advanced rapidly, opening up significant potential for several important medical applications. As complicated diseases increase and the number of cases rises, the role of machine-based imaging analysis has become indispensable. It serves as both a tool and an assistant to medical experts, providing valuable insights and guidance. A particularly challenging task in this area is lesion segmentation, a task that is challenging even for experienced radiologists. The complexity of this task highlights the urgent need for robust machine learning approaches to support medical staff. In response, we present our novel solution: the D-TrAttUnet architecture. This framework is based on the observation that different diseases often target specific organs. Our architecture includes an encoder-decoder structure with a composite Transformer-CNN encoder and dual decoders. The encoder includes two paths: the Transformer path and the Encoders Fusion Module path. The Dual-Decoder configuration uses two identical decoders, each with attention gates. This allows the model to simultaneously segment lesions and organs and integrate their segmentation losses. To validate our approach, we performed evaluations on the Covid-19 and Bone Metastasis segmentation tasks. We also investigated the adaptability of the model by testing it without the second decoder in the segmentation of glands and nuclei. The results confirmed the superiority of our approach, especially in Covid-19 infections and the segmentation of bone metastases. In addition, the hybrid encoder showed exceptional performance in the segmentation of glands and nuclei, solidifying its role in modern medical image analysis.
Read more5/8/2024
🌐
0
GCtx-UNet: Efficient Network for Medical Image Segmentation
Khaled Alrfou, Tian Zhao
Medical image segmentation is crucial for disease diagnosis and monitoring. Though effective, the current segmentation networks such as UNet struggle with capturing long-range features. More accurate models such as TransUNet, Swin-UNet, and CS-UNet have higher computation complexity. To address this problem, we propose GCtx-UNet, a lightweight segmentation architecture that can capture global and local image features with accuracy better or comparable to the state-of-the-art approaches. GCtx-UNet uses vision transformer that leverages global context self-attention modules joined with local self-attention to model long and short range spatial dependencies. GCtx-UNet is evaluated on the Synapse multi-organ abdominal CT dataset, the ACDC cardiac MRI dataset, and several polyp segmentation datasets. In terms of Dice Similarity Coefficient (DSC) and Hausdorff Distance (HD) metrics, GCtx-UNet outperformed CNN-based and Transformer-based approaches, with notable gains in the segmentation of complex and small anatomical structures. Moreover, GCtx-UNet is much more efficient than the state-of-the-art approaches with smaller model size, lower computation workload, and faster training and inference speed, making it a practical choice for clinical applications.
Read more6/11/2024