Modality-Order Matters! A Novel Hierarchical Feature Fusion Method for CoSAm: A Code-Switched Autism Corpus

0
✨
Sign in to get full access
Overview
- Autism Spectrum Disorder (ASD) is a complex neurodevelopmental challenge with a wide range of difficulties in social interaction, communication, and repetitive behaviors.
- The growing prevalence of ASD underscores the need for comprehensive research to better understand the disorder and improve early detection methods.
- This study introduces a novel hierarchical feature fusion approach to enhance early ASD detection in children through the analysis of code-switched speech (English and Hindi).
Plain English Explanation
The paper discusses a new method for early detection of autism in children by analyzing their speech patterns. Autism is a complex condition that can affect how a person interacts with others, communicates, and behaves. As the number of people diagnosed with autism has been increasing, there is a growing need for better ways to identify autism early on.
This research team developed a novel approach that combines different types of speech features, including acoustic (sound), paralinguistic (how something is said), and linguistic (the words used), to improve the accuracy of autism detection. They used advanced audio processing techniques and transformer encoders to integrate these different speech characteristics.
The researchers collected a dataset of speech recordings from children with autism and those without, where the children spoke in a mix of English and Hindi (known as "code-switching"). By analyzing the complexity and variability of the speech patterns, the researchers were able to achieve very high accuracy in distinguishing between the two groups. This suggests that this approach could be a valuable tool for early autism detection.
Technical Explanation
The study focused on developing a hierarchical feature fusion method to enhance the early detection of Autism Spectrum Disorder (ASD) in children through the analysis of code-switched speech (English and Hindi). The researchers collected a dataset called CoSAm, which includes 61 voice recordings from 30 children diagnosed with ASD and 31 neurotypical children, aged between 3 and 13 years, resulting in a total of 159.75 minutes of voice recordings.
The feature analysis involved extracting Mel-Frequency Cepstral Coefficients (MFCCs) and a wide range of statistical attributes to capture speech pattern variability and complexity. The researchers then employed a hierarchical fusion technique, where acoustic and linguistic features were combined first, followed by the addition of paralinguistic features. This innovative approach was designed to improve the classification robustness and accuracy, which are crucial for early and precise ASD identification.
The best model performance achieved an accuracy of 98.75% using this hierarchical fusion strategy, demonstrating the effectiveness of the proposed method in distinguishing between children with ASD and neurotypical children based on their code-switched speech patterns.
Critical Analysis
The study presents a promising approach for the early detection of Autism Spectrum Disorder (ASD) in children using a hierarchical feature fusion technique on code-switched speech data. The high accuracy achieved by the model suggests that this method could be a valuable tool for early intervention and improved outcomes for individuals with ASD.
However, the study does have some limitations that should be considered. The dataset used is relatively small, with only 61 voice recordings, which may limit the generalizability of the findings. Additionally, the study did not explore the potential impact of factors such as age, gender, or socioeconomic status on the speech patterns of children with ASD, which could provide valuable insights for refining the detection method.
Further research is needed to validate the findings on larger and more diverse datasets, as well as to investigate the long-term clinical implications of this approach. Exploring the integration of this method with other diagnostic tools and its implementation in real-world clinical settings would also be valuable next steps.
Conclusion
This study introduces a novel hierarchical feature fusion method for enhancing the early detection of Autism Spectrum Disorder (ASD) in children through the analysis of code-switched speech. The high accuracy achieved by the model demonstrates the potential of this approach to improve early identification of ASD, which is crucial for timely intervention and better outcomes for individuals with the condition.
The study's findings contribute to the growing body of research exploring the use of speech analysis and machine learning techniques for the early detection of neurodevelopmental disorders. As the prevalence of ASD continues to rise, this type of innovative research is essential for advancing our understanding of the disorder and developing more effective tools for its identification and management.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✨
0
Modality-Order Matters! A Novel Hierarchical Feature Fusion Method for CoSAm: A Code-Switched Autism Corpus
Mohd Mujtaba Akhtar, Girish, Muskaan Singh, Orchid Chetia Phukan
Autism Spectrum Disorder (ASD) is a complex neuro-developmental challenge, presenting a spectrum of difficulties in social interaction, communication, and the expression of repetitive behaviors in different situations. This increasing prevalence underscores the importance of ASD as a major public health concern and the need for comprehensive research initiatives to advance our understanding of the disorder and its early detection methods. This study introduces a novel hierarchical feature fusion method aimed at enhancing the early detection of ASD in children through the analysis of code-switched speech (English and Hindi). Employing advanced audio processing techniques, the research integrates acoustic, paralinguistic, and linguistic information using Transformer Encoders. This innovative fusion strategy is designed to improve classification robustness and accuracy, crucial for early and precise ASD identification. The methodology involves collecting a code-switched speech corpus, CoSAm, from children diagnosed with ASD and a matched control group. The dataset comprises 61 voice recordings from 30 children diagnosed with ASD and 31 from neurotypical children, aged between 3 and 13 years, resulting in a total of 159.75 minutes of voice recordings. The feature analysis focuses on MFCCs and extensive statistical attributes to capture speech pattern variability and complexity. The best model performance is achieved using a hierarchical fusion technique with an accuracy of 98.75% using a combination of acoustic and linguistic features first, followed by paralinguistic features in a hierarchical manner.
Read more7/24/2024

0
Automatic Voice Classification Of Autistic Subjects
Jessica Vacca, Natascia Brondino, Fabio Dell'Acqua, Anna Vizziello, Pietro Savazzi
Autism Spectrum Disorders (ASD) describe a heterogeneous set of conditions classified as neurodevelopmental disorders. Although the mechanisms underlying ASD are not yet fully understood, more recent literature focused on multiple genetics and/or environmental risk factors. Heterogeneity of symptoms, especially in milder forms of this condition, could be a challenge for the clinician. In this work, an automatic speech classification algorithm is proposed to characterize the prosodic elements that best distinguish autism, to support the traditional diagnosis. The performance of the proposed algorithm is evaluted by testing the classification algorithms on a dataset composed of recorded speeches, collected among both autustic and non autistic subjects.
Read more6/21/2024
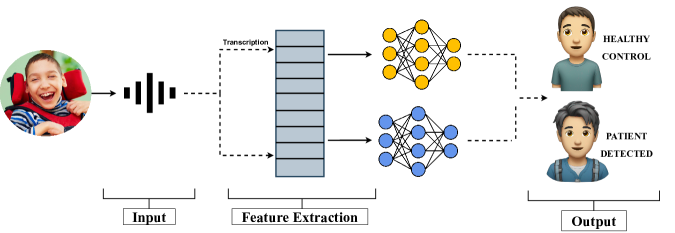
0
NeuRO: An Application for Code-Switched Autism Detection in Children
Mohd Mujtaba Akhtar, Girish, Orchid Chetia Phukan, Muskaan Singh
Code-switching is a common communication phenomenon where individuals alternate between two or more languages or linguistic styles within a single conversation. Autism Spectrum Disorder (ASD) is a developmental disorder posing challenges in social interaction, communication, and repetitive behaviors. Detecting ASD in individuals with code-switch scenario presents unique challenges. In this paper, we address this problem by building an application NeuRO which aims to detect potential signs of autism in code-switched conversations, facilitating early intervention and support for individuals with ASD.
Read more6/7/2024
💬
0
Semi-supervised Learning for Code-Switching ASR with Large Language Model Filter
Yu Xi, Wen Ding, Kai Yu, Junjie Lai
Code-switching (CS) phenomenon occurs when words or phrases from different languages are alternated in a single sentence. Due to data scarcity, building an effective CS Automatic Speech Recognition (ASR) system remains challenging. In this paper, we propose to enhance CS-ASR systems by utilizing rich unsupervised monolingual speech data within a semi-supervised learning framework, particularly when access to CS data is limited. To achieve this, we establish a general paradigm for applying noisy student training (NST) to the CS-ASR task. Specifically, we introduce the LLM-Filter, which leverages well-designed prompt templates to activate the correction capability of large language models (LLMs) for monolingual data selection and pseudo-labels refinement during NST. Our experiments on the supervised ASRU-CS and unsupervised AISHELL-2 and LibriSpeech datasets show that our method not only achieves significant improvements over supervised and semi-supervised learning baselines for the CS task, but also attains better performance compared with the fully-supervised oracle upper-bound on the CS English part. Additionally, we further investigate the influence of accent on AESRC dataset and demonstrate that our method can get achieve additional benefits when the monolingual data contains relevant linguistic characteristic.
Read more7/8/2024