Modeling Orthographic Variation in Occitan's Dialects
2404.19315
0
0
➖
Abstract
Effectively normalizing textual data poses a considerable challenge, especially for low-resource languages lacking standardized writing systems. In this study, we fine-tuned a multilingual model with data from several Occitan dialects and conducted a series of experiments to assess the model's representations of these dialects. For evaluation purposes, we compiled a parallel lexicon encompassing four Occitan dialects. Intrinsic evaluations of the model's embeddings revealed that surface similarity between the dialects strengthened representations. When the model was further fine-tuned for part-of-speech tagging and Universal Dependency parsing, its performance was robust to dialectical variation, even when trained solely on part-of-speech data from a single dialect. Our findings suggest that large multilingual models minimize the need for spelling normalization during pre-processing.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This study explores the challenge of effectively normalizing textual data, particularly for low-resource languages with non-standardized writing systems.
- The researchers fine-tuned a multilingual model using data from several Occitan dialects and conducted experiments to assess the model's representations of these dialects.
- For evaluation, they compiled a parallel lexicon covering four Occitan dialects.
- The model's performance was robust to dialectical variation, even when trained solely on part-of-speech data from a single dialect.
- The findings suggest that large multilingual models can minimize the need for spelling normalization during pre-processing.
Plain English Explanation
Normalizing text data, or ensuring it's in a consistent format, can be especially challenging for languages that don't have a widely accepted written standard. In this study, the researchers took a multilingual language model and fine-tuned it using data from several different Occitan dialects, which are related but have variations in spelling and grammar.
To test how well the model handled these dialect differences, the researchers created a dictionary that translated the same words across four Occitan dialects. They found that the model was able to learn representations of the dialects that captured their similarities, and that the model's performance on tasks like part-of-speech tagging and syntactic parsing remained strong even when it was only trained on data from a single dialect.
This suggests that using a large, multilingual model can help overcome the need to carefully normalize text data before using it for natural language processing tasks, at least for related dialects. The model is able to learn the similarities and differences between the dialects and apply that knowledge effectively.
Technical Explanation
The researchers in this study fine-tuned a multilingual model using data from several Occitan dialects, which are related but have variations in spelling and grammar. This was done to assess the model's ability to effectively represent these dialects and handle the orthographic variation.
For evaluation, the researchers compiled a parallel lexicon covering four Occitan dialects. Intrinsic evaluations of the model's word embeddings revealed that the surface similarity between the dialects was reflected in the model's representations.
When the model was further fine-tuned for part-of-speech tagging and Universal Dependency parsing, its performance remained robust to dialectical variation. Notably, the model maintained strong performance even when it was trained solely on part-of-speech data from a single dialect.
These findings suggest that using a large, multilingual model can help minimize the need for extensive spelling normalization during pre-processing, as the model is able to learn the similarities and differences between related dialects and apply that knowledge effectively.
Critical Analysis
The paper provides a promising approach to handling orthographic variation in low-resource languages, but there are a few caveats to consider. First, the study is limited to Occitan dialects, which are relatively closely related. It's unclear how well the findings would generalize to more distant language varieties or unrelated dialects.
Additionally, the researchers note that their evaluation focused on lexical-level tasks, and further research is needed to assess the model's performance on more complex, discourse-level tasks that may be more sensitive to dialectical differences.
Another potential limitation is the reliance on a parallel lexicon for evaluation. While this provides a controlled way to assess the model's representations, it may not fully capture the nuances of real-world text. Evaluation of geographical distortions in language models is an important consideration when working with dialectal data.
Overall, this study demonstrates the potential for large, multilingual models to handle orthographic variation, but further research is needed to explore the boundaries of this approach and its applicability to a wider range of language scenarios.
Conclusion
This study explores the use of a multilingual language model to effectively represent and process textual data from several Occitan dialects, which have non-standardized writing systems. The findings suggest that such models can learn representations that capture the similarities and differences between related dialects, and that this knowledge can be applied to maintain strong performance on tasks like part-of-speech tagging and syntactic parsing, even when the model is trained on data from a single dialect.
These results have important implications for natural language processing in low-resource languages and dialects, as they indicate that the need for extensive spelling normalization during pre-processing can be reduced by leveraging the capabilities of large, multilingual models. This could help make NLP more accessible and effective for a wider range of linguistic communities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Modeling Orthographic Variation Improves NLP Performance for Nigerian Pidgin
Pin-Jie Lin, Merel Scholman, Muhammed Saeed, Vera Demberg
0
0
Nigerian Pidgin is an English-derived contact language and is traditionally an oral language, spoken by approximately 100 million people. No orthographic standard has yet been adopted, and thus the few available Pidgin datasets that exist are characterised by noise in the form of orthographic variations. This contributes to under-performance of models in critical NLP tasks. The current work is the first to describe various types of orthographic variations commonly found in Nigerian Pidgin texts, and model this orthographic variation. The variations identified in the dataset form the basis of a phonetic-theoretic framework for word editing, which is used to generate orthographic variations to augment training data. We test the effect of this data augmentation on two critical NLP tasks: machine translation and sentiment analysis. The proposed variation generation framework augments the training data with new orthographic variants which are relevant for the test set but did not occur in the training set originally. Our results demonstrate the positive effect of augmenting the training data with a combination of real texts from other corpora as well as synthesized orthographic variation, resulting in performance improvements of 2.1 points in sentiment analysis and 1.4 BLEU points in translation to English.
4/30/2024
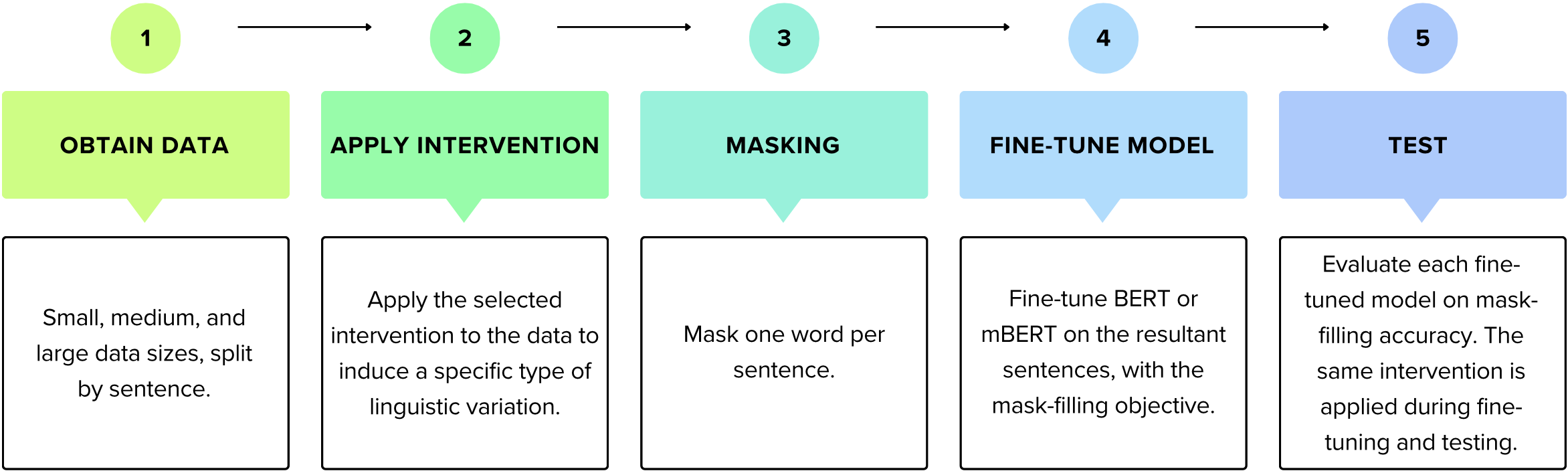
We're Calling an Intervention: Taking a Closer Look at Language Model Adaptation to Different Types of Linguistic Variation
Aarohi Srivastava, David Chiang
0
0
We present a suite of interventions and experiments that allow us to understand language model adaptation to text with linguistic variation (e.g., nonstandard or dialectal text). Our interventions address several features of linguistic variation, resulting in character, subword, and word-level changes. Applying our interventions during language model adaptation with varying size and nature of training data, we gain important insights into what makes linguistic variation particularly difficult for language models to deal with. For instance, on text with character-level variation, performance improves with even a few training examples but approaches a plateau, suggesting that more data is not the solution. In contrast, on text with variation involving new words or meanings, far more data is needed, but it leads to a massive breakthrough in performance. Our findings inform future work on dialectal NLP and making language models more robust to linguistic variation overall. We make the code for our interventions, which can be applied to any English text data, publicly available.
4/12/2024
🌿
Natural Language Processing for Dialects of a Language: A Survey
Aditya Joshi, Raj Dabre, Diptesh Kanojia, Zhuang Li, Haolan Zhan, Gholamreza Haffari, Doris Dippold
0
0
State-of-the-art natural language processing (NLP) models are trained on massive training corpora, and report a superlative performance on evaluation datasets. This survey delves into an important attribute of these datasets: the dialect of a language. Motivated by the performance degradation of NLP models for dialectic datasets and its implications for the equity of language technologies, we survey past research in NLP for dialects in terms of datasets, and approaches. We describe a wide range of NLP tasks in terms of two categories: natural language understanding (NLU) (for tasks such as dialect classification, sentiment analysis, parsing, and NLU benchmarks) and natural language generation (NLG) (for summarisation, machine translation, and dialogue systems). The survey is also broad in its coverage of languages which include English, Arabic, German among others. We observe that past work in NLP concerning dialects goes deeper than mere dialect classification, and . This includes early approaches that used sentence transduction that lead to the recent approaches that integrate hypernetworks into LoRA. We expect that this survey will be useful to NLP researchers interested in building equitable language technologies by rethinking LLM benchmarks and model architectures.
4/1/2024
💬
Evaluation of Geographical Distortions in Language Models: A Crucial Step Towards Equitable Representations
R'emy Decoupes, Roberto Interdonato, Mathieu Roche, Maguelonne Teisseire, Sarah Valentin
0
0
Language models now constitute essential tools for improving efficiency for many professional tasks such as writing, coding, or learning. For this reason, it is imperative to identify inherent biases. In the field of Natural Language Processing, five sources of bias are well-identified: data, annotation, representation, models, and research design. This study focuses on biases related to geographical knowledge. We explore the connection between geography and language models by highlighting their tendency to misrepresent spatial information, thus leading to distortions in the representation of geographical distances. This study introduces four indicators to assess these distortions, by comparing geographical and semantic distances. Experiments are conducted from these four indicators with ten widely used language models. Results underscore the critical necessity of inspecting and rectifying spatial biases in language models to ensure accurate and equitable representations.
4/29/2024