Natural Language Processing for Dialects of a Language: A Survey
2401.05632
0
0
🌿
Abstract
State-of-the-art natural language processing (NLP) models are trained on massive training corpora, and report a superlative performance on evaluation datasets. This survey delves into an important attribute of these datasets: the dialect of a language. Motivated by the performance degradation of NLP models for dialectic datasets and its implications for the equity of language technologies, we survey past research in NLP for dialects in terms of datasets, and approaches. We describe a wide range of NLP tasks in terms of two categories: natural language understanding (NLU) (for tasks such as dialect classification, sentiment analysis, parsing, and NLU benchmarks) and natural language generation (NLG) (for summarisation, machine translation, and dialogue systems). The survey is also broad in its coverage of languages which include English, Arabic, German among others. We observe that past work in NLP concerning dialects goes deeper than mere dialect classification, and . This includes early approaches that used sentence transduction that lead to the recent approaches that integrate hypernetworks into LoRA. We expect that this survey will be useful to NLP researchers interested in building equitable language technologies by rethinking LLM benchmarks and model architectures.
Get summaries of the top AI research delivered straight to your inbox:
Introduction
Motivation
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Evaluating Dialect Robustness of Language Models via Conversation Understanding
Dipankar Srirag, Aditya Joshi
0
0
With an evergrowing number of LLMs reporting superlative performance for English, their ability to perform equitably for different dialects of English (i.e., dialect robustness) needs to be ascertained. Specifically, we use English language (US English or Indian English) conversations between humans who play the word-guessing game of `taboo'. We formulate two evaluative tasks: target word prediction (TWP) (i.e.predict the masked target word in a conversation) and target word selection (TWS) (i.e., select the most likely masked target word in a conversation, from among a set of candidate words). Extending MD3, an existing dialectic dataset of taboo-playing conversations, we introduce M-MD3, a target-word-masked version of MD3 with the USEng and IndEng subsets. We add two subsets: AITrans (where dialectic information is removed from IndEng) and AIGen (where LLMs are prompted to generate conversations). Our evaluation uses pre-trained and fine-tuned versions of two closed-source (GPT-4/3.5) and two open-source LLMs (Mistral and Gemma). LLMs perform significantly better for US English than Indian English for both TWP and TWS, for all settings. While GPT-based models perform the best, the comparatively smaller models work more equitably for short conversations (<8 turns). Our results on AIGen and AITrans (the best and worst-performing subset) respectively show that LLMs may learn a dialect of their own based on the composition of the training data, and that dialect robustness is indeed a challenging task. Our evaluation methodology exhibits a novel way to examine attributes of language models using pre-existing dialogue datasets.
5/10/2024
👨🏫
Data-Augmentation-Based Dialectal Adaptation for LLMs
Fahim Faisal, Antonios Anastasopoulos
0
0
This report presents GMUNLP's participation to the Dialect-Copa shared task at VarDial 2024, which focuses on evaluating the commonsense reasoning capabilities of large language models (LLMs) on South Slavic micro-dialects. The task aims to assess how well LLMs can handle non-standard dialectal varieties, as their performance on standard languages is already well-established. We propose an approach that combines the strengths of different types of language models and leverages data augmentation techniques to improve task performance on three South Slavic dialects: Chakavian, Cherkano, and Torlak. We conduct experiments using a language-family-focused encoder-based model (BERTi'c) and a domain-agnostic multilingual model (AYA-101). Our results demonstrate that the proposed data augmentation techniques lead to substantial performance gains across all three test datasets in the open-source model category. This work highlights the practical utility of data augmentation and the potential of LLMs in handling non-standard dialectal varieties, contributing to the broader goal of advancing natural language understanding in low-resource and dialectal settings. Code:https://github.com/ffaisal93/dialect_copa
4/15/2024
Computational Job Market Analysis with Natural Language Processing
Mike Zhang
0
0
[Abridged Abstract] Recent technological advances underscore labor market dynamics, yielding significant consequences for employment prospects and increasing job vacancy data across platforms and languages. Aggregating such data holds potential for valuable insights into labor market demands, new skills emergence, and facilitating job matching for various stakeholders. However, despite prevalent insights in the private sector, transparent language technology systems and data for this domain are lacking. This thesis investigates Natural Language Processing (NLP) technology for extracting relevant information from job descriptions, identifying challenges including scarcity of training data, lack of standardized annotation guidelines, and shortage of effective extraction methods from job ads. We frame the problem, obtaining annotated data, and introducing extraction methodologies. Our contributions include job description datasets, a de-identification dataset, and a novel active learning algorithm for efficient model training. We propose skill extraction using weak supervision, a taxonomy-aware pre-training methodology adapting multilingual language models to the job market domain, and a retrieval-augmented model leveraging multiple skill extraction datasets to enhance overall performance. Finally, we ground extracted information within a designated taxonomy.
5/1/2024
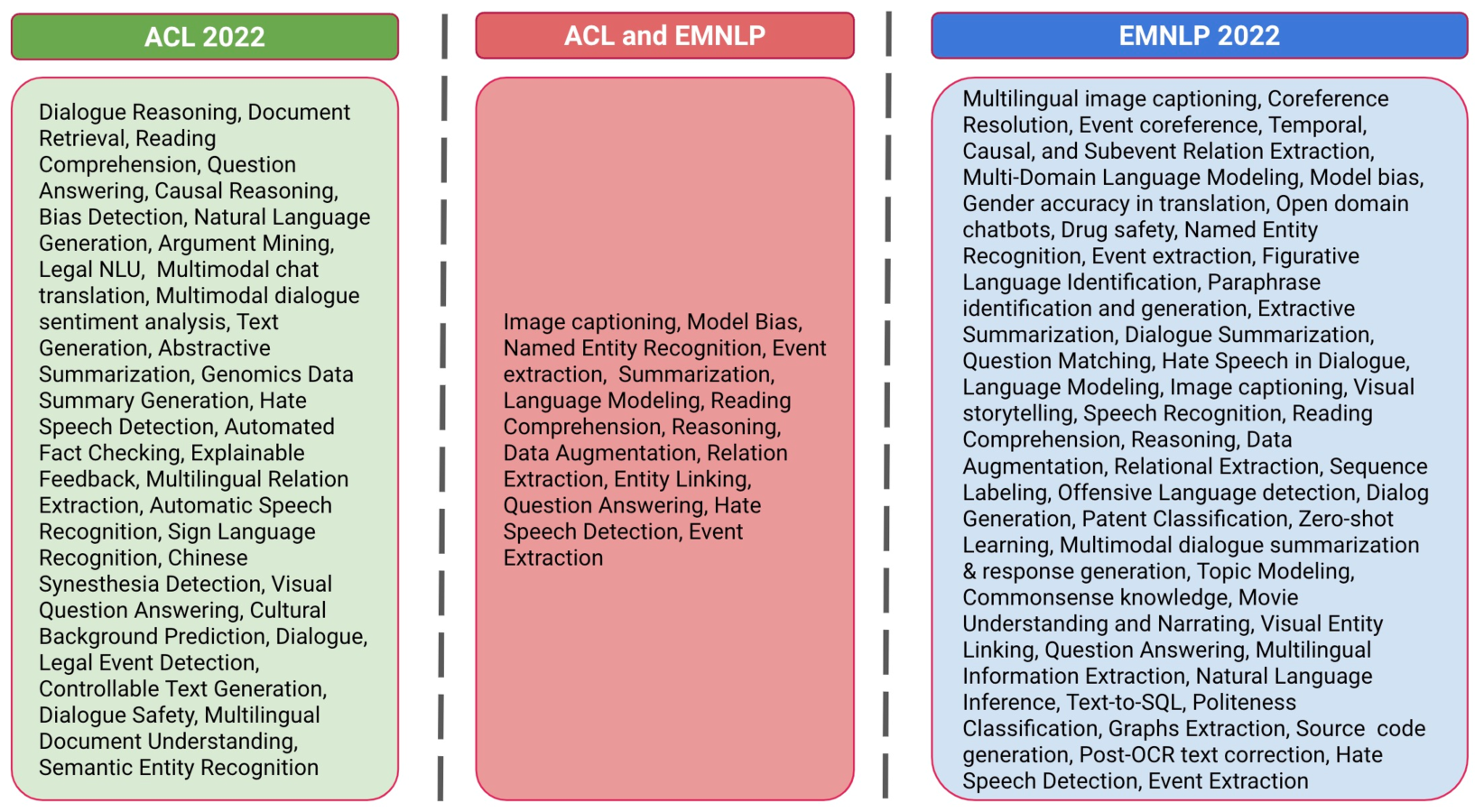
Revealing Trends in Datasets from the 2022 ACL and EMNLP Conferences
Jesse Atuhurra, Hidetaka Kamigaito
0
0
Natural language processing (NLP) has grown significantly since the advent of the Transformer architecture. Transformers have given birth to pre-trained large language models (PLMs). There has been tremendous improvement in the performance of NLP systems across several tasks. NLP systems are on par or, in some cases, better than humans at accomplishing specific tasks. However, it remains the norm that emph{better quality datasets at the time of pretraining enable PLMs to achieve better performance, regardless of the task.} The need to have quality datasets has prompted NLP researchers to continue creating new datasets to satisfy particular needs. For example, the two top NLP conferences, ACL and EMNLP, accepted ninety-two papers in 2022, introducing new datasets. This work aims to uncover the trends and insights mined within these datasets. Moreover, we provide valuable suggestions to researchers interested in curating datasets in the future.
4/16/2024