MoManifold: Learning to Measure 3D Human Motion via Decoupled Joint Acceleration Manifolds

0

Sign in to get full access
Overview
- The paper presents MoManifold, a learning-based method for measuring 3D human motion by decoupling joint acceleration manifolds.
- It introduces a novel neural network architecture and training approach to model and predict human motion in a decoupled way.
- The proposed method enables accurate 3D human motion reconstruction from sparse or noisy input data.
Plain English Explanation
The paper introduces a new way to measure and predict the motion of the human body in 3D space. The key insight is to decouple or separate the motion of different body parts, rather than trying to model the entire body as a single unit.
The researchers developed a neural network that can take sparse or noisy input data about the movements of a person, and use that to accurately reconstruct the full 3D motion of their body. This is done by breaking down the motion into separate "manifolds" or surfaces that represent the acceleration of each individual joint or body part.
By modeling the motion in this decoupled way, the system is able to better capture the complex, interdependent nature of human movement. This allows it to predict the 3D trajectory of the entire body more accurately, even when the input data is limited or imperfect.
Technical Explanation
The core of the MoManifold approach is a neural network architecture that models human motion as a set of decoupled joint acceleration manifolds. The network takes 3D joint position and velocity data as input, and outputs a reconstructed 3D motion trajectory.
The key innovation is the use of manifold-aware layers that learn a low-dimensional representation of the nonlinear acceleration dynamics for each joint independently. This allows the model to align and combine the decoupled joint manifolds to produce an accurate full-body motion prediction.
The network is trained end-to-end on large motion capture datasets, learning to map the input joint trajectories to the corresponding decoupled acceleration manifolds. This learning approach enables the model to generalize and produce realistic 3D human motions, even from sparse or noisy input data.
Critical Analysis
The paper presents a compelling technical approach to the challenge of 3D human motion modeling and reconstruction. The key innovation of decoupling the joint acceleration dynamics is a conceptually elegant solution that allows the model to better capture the complex, interdependent nature of human movement.
However, the paper does not discuss certain limitations of the approach. For example, it is unclear how the model would handle highly
Furthermore, the evaluation is primarily focused on motion reconstruction accuracy, without much discussion of the computational efficiency or real-time performance of the approach. These practical considerations would be important for deploying the system in real-world applications.
Conclusion
The MoManifold paper presents a novel and technically sophisticated approach to 3D human motion modeling and reconstruction. By decoupling the joint acceleration dynamics into independent manifolds, the system is able to accurately predict full-body motions from sparse or noisy input data.
This work demonstrates the potential of learning-based methods to tackle the challenge of human motion analysis, with implications for applications ranging from animation to robotics. Further research to address the identified limitations could help solidify the MoManifold approach as a powerful tool for measuring and understanding human movement in 3D space.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MoManifold: Learning to Measure 3D Human Motion via Decoupled Joint Acceleration Manifolds
Ziqiang Dang, Tianxing Fan, Boming Zhao, Xujie Shen, Lei Wang, Guofeng Zhang, Zhaopeng Cui
Incorporating temporal information effectively is important for accurate 3D human motion estimation and generation which have wide applications from human-computer interaction to AR/VR. In this paper, we present MoManifold, a novel human motion prior, which models plausible human motion in continuous high-dimensional motion space. Different from existing mathematical or VAE-based methods, our representation is designed based on the neural distance field, which makes human dynamics explicitly quantified to a score and thus can measure human motion plausibility. Specifically, we propose novel decoupled joint acceleration manifolds to model human dynamics from existing limited motion data. Moreover, we introduce a novel optimization method using the manifold distance as guidance, which facilitates a variety of motion-related tasks. Extensive experiments demonstrate that MoManifold outperforms existing SOTAs as a prior in several downstream tasks such as denoising real-world human mocap data, recovering human motion from partial 3D observations, mitigating jitters for SMPL-based pose estimators, and refining the results of motion in-betweening.
Read more9/4/2024

0
Motion Manifold Flow Primitives for Language-Guided Trajectory Generation
Yonghyeon Lee, Byeongho Lee, Seungyeon Kim, Frank C. Park
Developing text-based robot trajectory generation models is made particularly difficult by the small dataset size, high dimensionality of the trajectory space, and the inherent complexity of the text-conditional motion distribution. Recent manifold learning-based methods have partially addressed the dimensionality and dataset size issues, but struggle with the complex text-conditional distribution. In this paper we propose a text-based trajectory generation model that attempts to address all three challenges while relying on only a handful of demonstration trajectory data. Our key idea is to leverage recent flow-based models capable of capturing complex conditional distributions, not directly in the high-dimensional trajectory space, but rather in the low-dimensional latent coordinate space of the motion manifold, with deliberately designed regularization terms to ensure smoothness of motions and robustness to text variations. We show that our {it Motion Manifold Flow Primitive (MMFP)} framework can accurately generate qualitatively distinct motions for a wide range of text inputs, significantly outperforming existing methods.
Read more7/30/2024

0
Learning Human Motion from Monocular Videos via Cross-Modal Manifold Alignment
Shuaiying Hou, Hongyu Tao, Junheng Fang, Changqing Zou, Hujun Bao, Weiwei Xu
Learning 3D human motion from 2D inputs is a fundamental task in the realms of computer vision and computer graphics. Many previous methods grapple with this inherently ambiguous task by introducing motion priors into the learning process. However, these approaches face difficulties in defining the complete configurations of such priors or training a robust model. In this paper, we present the Video-to-Motion Generator (VTM), which leverages motion priors through cross-modal latent feature space alignment between 3D human motion and 2D inputs, namely videos and 2D keypoints. To reduce the complexity of modeling motion priors, we model the motion data separately for the upper and lower body parts. Additionally, we align the motion data with a scale-invariant virtual skeleton to mitigate the interference of human skeleton variations to the motion priors. Evaluated on AIST++, the VTM showcases state-of-the-art performance in reconstructing 3D human motion from monocular videos. Notably, our VTM exhibits the capabilities for generalization to unseen view angles and in-the-wild videos.
Read more4/16/2024
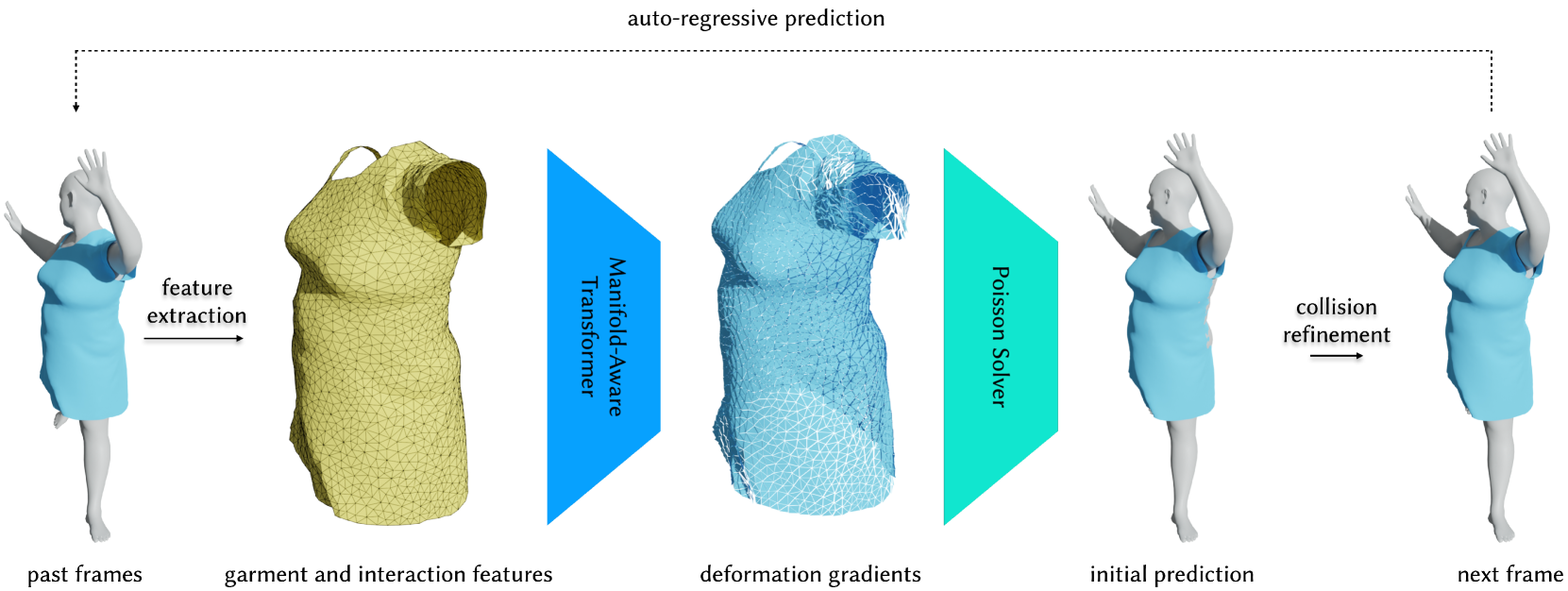
0
Neural Garment Dynamics via Manifold-Aware Transformers
Peizhuo Li, Tuanfeng Y. Wang, Timur Levent Kesdogan, Duygu Ceylan, Olga Sorkine-Hornung
Data driven and learning based solutions for modeling dynamic garments have significantly advanced, especially in the context of digital humans. However, existing approaches often focus on modeling garments with respect to a fixed parametric human body model and are limited to garment geometries that were seen during training. In this work, we take a different approach and model the dynamics of a garment by exploiting its local interactions with the underlying human body. Specifically, as the body moves, we detect local garment-body collisions, which drive the deformation of the garment. At the core of our approach is a mesh-agnostic garment representation and a manifold-aware transformer network design, which together enable our method to generalize to unseen garment and body geometries. We evaluate our approach on a wide variety of garment types and motion sequences and provide competitive qualitative and quantitative results with respect to the state of the art.
Read more7/9/2024