MoPE: Parameter-Efficient and Scalable Multimodal Fusion via Mixture of Prompt Experts

0
Sign in to get full access
Overview
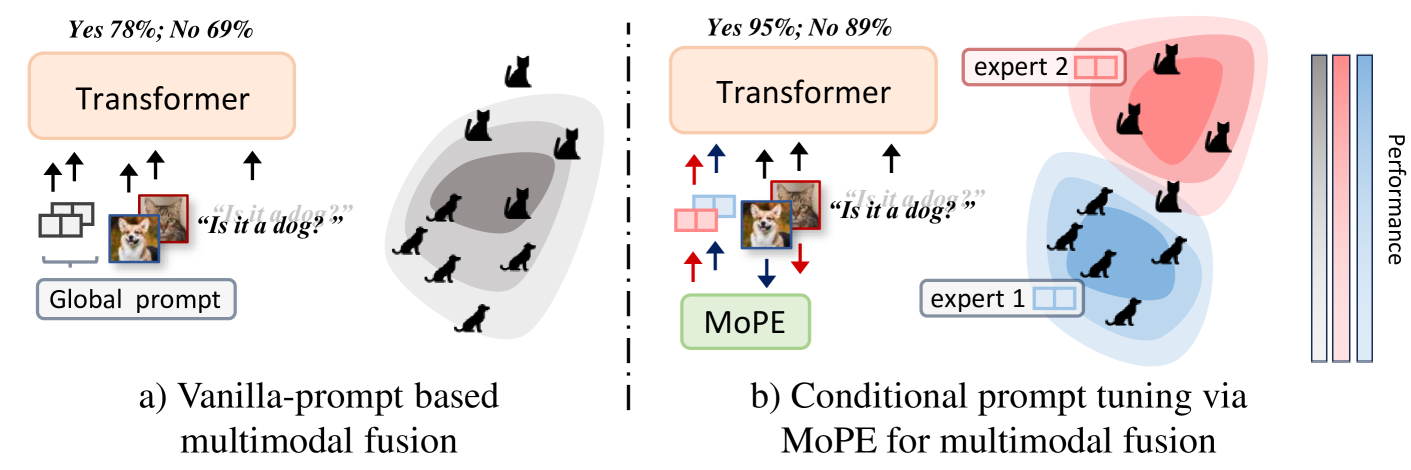
- MoPE is a parameter-efficient and scalable multimodal fusion method that uses a mixture of prompt experts.
- It aims to address the limitations of existing multimodal fusion techniques, such as high computational cost and lack of scalability.
- MoPE achieves this by leveraging prompt-based learning and a mixture of experts architecture.
Plain English Explanation
MoPE: Parameter-Efficient and Scalable Multimodal Fusion via Mixture of Prompt Experts is a new approach to combining information from multiple data sources, such as text and images. Existing methods for this task, known as "multimodal fusion," can be computationally expensive and struggle to scale to larger datasets.
MoPE aims to address these issues by using a technique called "prompt-based learning." Instead of training a large, complex model to handle all the data, MoPE uses a collection of smaller "expert" models, each focused on a specific aspect of the task. These experts are then combined using a "mixture of experts" architecture, which allows the system to dynamically choose the best expert(s) for each input.
This approach has several benefits. First, it is more parameter-efficient, meaning it requires fewer trainable parameters than a single, large model. This makes it faster and cheaper to train and deploy. Second, the mixture of experts design makes the system more scalable, as new experts can be added to handle additional data sources or tasks without having to retrain the entire model.
Overall, MoPE represents a promising new direction for multimodal fusion that could lead to more efficient and flexible AI systems capable of handling a wide range of data and tasks.
Technical Explanation
MoPE: Parameter-Efficient and Scalable Multimodal Fusion via Mixture of Prompt Experts proposes a novel approach to multimodal fusion that combines prompt-based learning with a mixture of experts architecture.
The key idea is to use a collection of smaller "prompt expert" models, each specialized in processing a particular modality (e.g., text or image). These experts are then combined using a gating network, which learns to dynamically select the most relevant experts for a given input.
This design offers several advantages over traditional multimodal fusion techniques:
-
Parameter Efficiency: By using a mixture of smaller experts rather than a single large model, MoPE significantly reduces the total number of trainable parameters, making it more efficient to train and deploy.
-
Scalability: The mixture of experts architecture allows new experts to be added to handle additional data sources or tasks without having to retrain the entire system.
-
Interpretability: The modular design of MoPE makes it easier to understand and debug the system, as the role of each expert can be analyzed independently.
The authors evaluate MoPE on several multimodal benchmarks, demonstrating its superior performance compared to state-of-the-art fusion methods while using fewer parameters. They also show that MoPE can effectively handle missing modalities and scales well to larger datasets.
Critical Analysis
MoPE: Parameter-Efficient and Scalable Multimodal Fusion via Mixture of Prompt Experts presents a promising approach to multimodal fusion, but there are a few potential limitations and areas for further research:
-
Hyperparameter Tuning: The performance of MoPE may be sensitive to the choice of hyperparameters, such as the number of experts and the gating network architecture. The authors do not provide a detailed analysis of how these hyperparameters impact the model's performance.
-
Interpretability Limitations: While the modular design of MoPE can improve interpretability, the gating network that combines the experts may still be a "black box" to some extent. Further research could explore ways to make the gating network more transparent and interpretable.
-
Generalization to Novel Tasks: The authors primarily evaluate MoPE on existing multimodal benchmarks. It would be valuable to assess how well the model can generalize to new, unseen tasks, especially those that require more complex reasoning or cross-modal interactions.
-
Computational Overhead: While MoPE is more parameter-efficient than traditional fusion methods, the overhead of the gating network and the need to forward data through multiple expert models may still result in higher computational requirements than simpler fusion techniques.
Overall, MoPE: Parameter-Efficient and Scalable Multimodal Fusion via Mixture of Prompt Experts represents a promising step forward in multimodal fusion research, and the authors have highlighted several important directions for future work.
Conclusion
MoPE: Parameter-Efficient and Scalable Multimodal Fusion via Mixture of Prompt Experts introduces a novel approach to multimodal fusion that combines prompt-based learning and a mixture of experts architecture. This design allows for more parameter-efficient and scalable multimodal models, addressing key limitations of existing fusion techniques.
The results presented in the paper suggest that MoPE can outperform state-of-the-art methods on several multimodal benchmarks while using fewer trainable parameters. This could lead to more efficient and flexible AI systems capable of handling diverse data sources and tasks.
However, the paper also highlights areas for further research, such as improving the interpretability of the gating network and assessing the model's ability to generalize to novel tasks. Addressing these challenges could help unlock the full potential of MoPE and similar approaches to multimodal fusion.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MoPE: Parameter-Efficient and Scalable Multimodal Fusion via Mixture of Prompt Experts
Ruixiang Jiang, Lingbo Liu, Changwen Chen
Despite the demonstrated parameter efficiency of prompt-based multimodal fusion methods, their limited adaptivity and expressiveness often result in suboptimal performance compared to other tuning approaches. In this paper, we address these limitations by decomposing the vanilla prompts to adaptively capture instance-level features. Building upon this decomposition, we introduce the mixture of prompt experts (MoPE) technique to enhance the expressiveness of prompt tuning. MoPE leverages multimodal pairing priors to route the most effective prompt on a per-instance basis. Compared to vanilla prompting, our MoPE-based fusion method exhibits greater expressiveness, scaling more effectively with the training data and the overall number of trainable parameters. We also investigate regularization terms for expert routing, which lead to emergent expert specialization during training, paving the way for interpretable soft prompting. Extensive experiments across six multimodal datasets spanning four modalities demonstrate that our method achieves state-of-the-art results for prompt fusion, matching or even surpassing the performance of fine-tuning while requiring only 0.8% of the trainable parameters. Code will be released: https://github.com/songrise/MoPE.
Read more9/12/2024
🔍
0
Multi-Prompt with Depth Partitioned Cross-Modal Learning
Yingjie Tian, Yiqi Wang, Xianda Guo, Zheng Zhu, Long Chen
In recent years, soft prompt learning methods have been proposed to fine-tune large-scale vision-language pre-trained models for various downstream tasks. These methods typically combine learnable textual tokens with class tokens as input for models with frozen parameters. However, they often employ a single prompt to describe class contexts, failing to capture categories' diverse attributes adequately. This study introduces the Partitioned Multi-modal Prompt (PMPO), a multi-modal prompting technique that extends the soft prompt from a single learnable prompt to multiple prompts. Our method divides the visual encoder depths and connects learnable prompts to the separated visual depths, enabling different prompts to capture the hierarchical contextual depths of visual representations. Furthermore, to maximize the advantages of multi-prompt learning, we incorporate prior information from manually designed templates and learnable multi-prompts, thus improving the generalization capabilities of our approach. We evaluate the effectiveness of our approach on three challenging tasks: new class generalization, cross-dataset evaluation, and domain generalization. For instance, our method achieves a $79.28$ harmonic mean, averaged over 11 diverse image recognition datasets ($+7.62$ compared to CoOp), demonstrating significant competitiveness compared to state-of-the-art prompting methods.
Read more5/1/2024
🚀
0
FuseMoE: Mixture-of-Experts Transformers for Fleximodal Fusion
Xing Han, Huy Nguyen, Carl Harris, Nhat Ho, Suchi Saria
As machine learning models in critical fields increasingly grapple with multimodal data, they face the dual challenges of handling a wide array of modalities, often incomplete due to missing elements, and the temporal irregularity and sparsity of collected samples. Successfully leveraging this complex data, while overcoming the scarcity of high-quality training samples, is key to improving these models' predictive performance. We introduce ``FuseMoE'', a mixture-of-experts framework incorporated with an innovative gating function. Designed to integrate a diverse number of modalities, FuseMoE is effective in managing scenarios with missing modalities and irregularly sampled data trajectories. Theoretically, our unique gating function contributes to enhanced convergence rates, leading to better performance in multiple downstream tasks. The practical utility of FuseMoE in the real world is validated by a diverse set of challenging prediction tasks.
Read more5/24/2024

0
One Prompt is not Enough: Automated Construction of a Mixture-of-Expert Prompts
Ruochen Wang, Sohyun An, Minhao Cheng, Tianyi Zhou, Sung Ju Hwang, Cho-Jui Hsieh
Large Language Models (LLMs) exhibit strong generalization capabilities to novel tasks when prompted with language instructions and in-context demos. Since this ability sensitively depends on the quality of prompts, various methods have been explored to automate the instruction design. While these methods demonstrated promising results, they also restricted the searched prompt to one instruction. Such simplification significantly limits their capacity, as a single demo-free instruction might not be able to cover the entire complex problem space of the targeted task. To alleviate this issue, we adopt the Mixture-of-Expert paradigm and divide the problem space into a set of sub-regions; Each sub-region is governed by a specialized expert, equipped with both an instruction and a set of demos. A two-phase process is developed to construct the specialized expert for each region: (1) demo assignment: Inspired by the theoretical connection between in-context learning and kernel regression, we group demos into experts based on their semantic similarity; (2) instruction assignment: A region-based joint search of an instruction per expert complements the demos assigned to it, yielding a synergistic effect. The resulting method, codenamed Mixture-of-Prompts (MoP), achieves an average win rate of 81% against prior arts across several major benchmarks.
Read more7/2/2024