MORE: Multi-mOdal REtrieval Augmented Generative Commonsense Reasoning
2402.13625
0
0

Abstract
Since commonsense information has been recorded significantly less frequently than its existence, language models pre-trained by text generation have difficulty to learn sufficient commonsense knowledge. Several studies have leveraged text retrieval to augment the models' commonsense ability. Unlike text, images capture commonsense information inherently but little effort has been paid to effectively utilize them. In this work, we propose a novel Multi-mOdal REtrieval (MORE) augmentation framework, to leverage both text and images to enhance the commonsense ability of language models. Extensive experiments on the Common-Gen task have demonstrated the efficacy of MORE based on the pre-trained models of both single and multiple modalities.
Create account to get full access
Overview
- Presents a novel approach called MORE (Multi-mOdal REtrieval Augmented Generative Commonsense Reasoning) for incorporating multimodal information into generative commonsense reasoning tasks.
- Leverages large language models, multimodal retrieval, and commonsense reasoning to tackle challenging language understanding problems.
- Demonstrates performance improvements on multiple benchmark tasks compared to existing methods.
Plain English Explanation
The paper introduces a new system called MORE that aims to improve the ability of language models to reason about the world in a more natural and human-like way. The key idea is to combine the power of large language models, which can generate human-like text, with the ability to retrieve relevant information from a multimodal (text and image) knowledge base.
By accessing this diverse knowledge base, the model can draw upon a richer understanding of the world to reason about complex scenarios and questions, rather than relying solely on the limited information contained in the training text. This approach is particularly useful for tasks that require commonsense reasoning, where the model needs to understand the implicit context and relationships between different concepts.
The paper shows that this multimodal retrieval-augmented approach leads to significant performance gains on a variety of benchmark tasks, such as link to "Unified Text-to-Image Generation & Retrieval" and link to "Multi-Modal Retrieval with Large Language Model Based". This suggests that incorporating diverse sources of information can help language models better comprehend and reason about the world, bringing us one step closer to more natural and intelligent language understanding systems.
Technical Explanation
The MORE system combines large language models, multimodal retrieval, and commonsense reasoning to tackle challenging language understanding tasks. The core components include:
-
Retrieval Module: This module uses a link to "UNIRAG: Universal Retrieval Augmentation for Multi-Modal Large Language Models" to retrieve relevant multimodal information (text and images) from a knowledge base, given an input query.
-
Reasoning Module: The retrieved information is then used to augment the input to a large language model, which can then generate commonsense-informed responses or answer questions. This reasoning module leverages link to "Retrieval Meets Reasoning: Even High School Textbook" to effectively integrate the retrieved knowledge.
The paper evaluates the MORE system on a range of benchmark tasks, including visual commonsense reasoning, open-ended question answering, and multi-hop reasoning. The results demonstrate that the multimodal retrieval-augmented approach significantly outperforms existing language-only models, showcasing the benefits of incorporating diverse sources of information for improved commonsense reasoning.
Critical Analysis
The paper presents a well-designed and compelling approach to incorporating multimodal information into generative commonsense reasoning tasks. The use of large language models, coupled with a retrieval-based knowledge augmentation mechanism, is a promising direction for advancing the state-of-the-art in language understanding.
However, the paper does not address certain limitations and potential concerns:
-
Scalability and Efficiency: While the multimodal retrieval component is a key innovation, the computational overhead of querying a large knowledge base may limit the practical deployment of the MORE system, especially in real-time applications.
-
Bias and Fairness: As with any machine learning system, there are concerns about the potential for biases and fairness issues, particularly when the training data and knowledge base may not be representative of diverse perspectives and experiences.
-
Interpretability and Transparency: The paper does not delve into the interpretability of the MORE system's reasoning process, which is an important consideration for building trust and understanding in real-world applications.
Addressing these limitations and potential issues could further strengthen the impact and applicability of the MORE approach, and would be valuable avenues for future research.
Conclusion
The MORE system presented in this paper demonstrates a promising approach to incorporating multimodal information into generative commonsense reasoning tasks. By leveraging large language models, multimodal retrieval, and commonsense reasoning, the system is able to significantly outperform existing language-only models on a variety of benchmark tasks.
This research represents an important step forward in the quest for more natural and intelligent language understanding systems, which could have far-reaching implications for a wide range of applications, from question-answering and conversational AI to content generation and knowledge-based decision-making. As the field continues to evolve, addressing the limitations and concerns raised in the critical analysis could further enhance the impact and practical applicability of this innovative approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
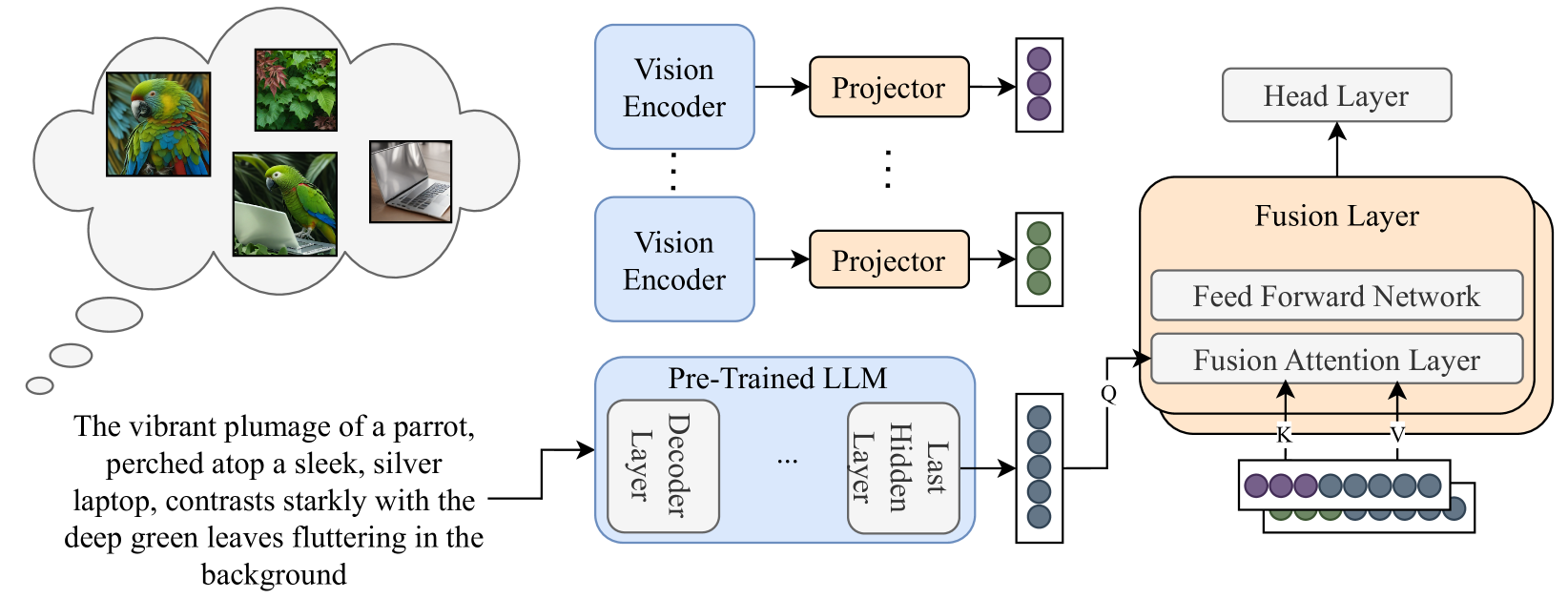
Improving Visual Commonsense in Language Models via Multiple Image Generation
Guy Yariv, Idan Schwartz, Yossi Adi, Sagie Benaim
0
0
Commonsense reasoning is fundamentally based on multimodal knowledge. However, existing large language models (LLMs) are primarily trained using textual data only, limiting their ability to incorporate essential visual information. In contrast, Visual Language Models, which excel at visually-oriented tasks, often fail at non-visual tasks such as basic commonsense reasoning. This divergence highlights a critical challenge - the integration of robust visual understanding with foundational text-based language reasoning. To this end, we introduce a method aimed at enhancing LLMs' visual commonsense. Specifically, our method generates multiple images based on the input text prompt and integrates these into the model's decision-making process by mixing their prediction probabilities. To facilitate multimodal grounded language modeling, we employ a late-fusion layer that combines the projected visual features with the output of a pre-trained LLM conditioned on text only. This late-fusion layer enables predictions based on comprehensive image-text knowledge as well as text only when this is required. We evaluate our approach using several visual commonsense reasoning tasks together with traditional NLP tasks, including common sense reasoning and reading comprehension. Our experimental results demonstrate significant superiority over existing baselines. When applied to recent state-of-the-art LLMs (e.g., Llama3), we observe improvements not only in visual common sense but also in traditional NLP benchmarks. Code and models are available under https://github.com/guyyariv/vLMIG.
6/21/2024

Retrieval Meets Reasoning: Even High-school Textbook Knowledge Benefits Multimodal Reasoning
Cheng Tan, Jingxuan Wei, Linzhuang Sun, Zhangyang Gao, Siyuan Li, Bihui Yu, Ruifeng Guo, Stan Z. Li
0
0
Large language models equipped with retrieval-augmented generation (RAG) represent a burgeoning field aimed at enhancing answering capabilities by leveraging external knowledge bases. Although the application of RAG with language-only models has been extensively explored, its adaptation into multimodal vision-language models remains nascent. Going beyond mere answer generation, the primary goal of multimodal RAG is to cultivate the models' ability to reason in response to relevant queries. To this end, we introduce a novel multimodal RAG framework named RMR (Retrieval Meets Reasoning). The RMR framework employs a bi-modal retrieval module to identify the most relevant question-answer pairs, which then serve as scaffolds for the multimodal reasoning process. This training-free approach not only encourages the model to engage deeply with the reasoning processes inherent in the retrieved content but also facilitates the generation of answers that are precise and richly interpretable. Surprisingly, utilizing solely the ScienceQA dataset, collected from elementary and high school science curricula, RMR significantly boosts the performance of various vision-language models across a spectrum of benchmark datasets, including A-OKVQA, MMBench, and SEED. These outcomes highlight the substantial potential of our multimodal retrieval and reasoning mechanism to improve the reasoning capabilities of vision-language models.
6/3/2024

Unified Text-to-Image Generation and Retrieval
Leigang Qu, Haochuan Li, Tan Wang, Wenjie Wang, Yongqi Li, Liqiang Nie, Tat-Seng Chua
0
0
How humans can efficiently and effectively acquire images has always been a perennial question. A typical solution is text-to-image retrieval from an existing database given the text query; however, the limited database typically lacks creativity. By contrast, recent breakthroughs in text-to-image generation have made it possible to produce fancy and diverse visual content, but it faces challenges in synthesizing knowledge-intensive images. In this work, we rethink the relationship between text-to-image generation and retrieval and propose a unified framework in the context of Multimodal Large Language Models (MLLMs). Specifically, we first explore the intrinsic discriminative abilities of MLLMs and introduce a generative retrieval method to perform retrieval in a training-free manner. Subsequently, we unify generation and retrieval in an autoregressive generation way and propose an autonomous decision module to choose the best-matched one between generated and retrieved images as the response to the text query. Additionally, we construct a benchmark called TIGeR-Bench, including creative and knowledge-intensive domains, to standardize the evaluation of unified text-to-image generation and retrieval. Extensive experimental results on TIGeR-Bench and two retrieval benchmarks, i.e., Flickr30K and MS-COCO, demonstrate the superiority and effectiveness of our proposed method.
6/11/2024
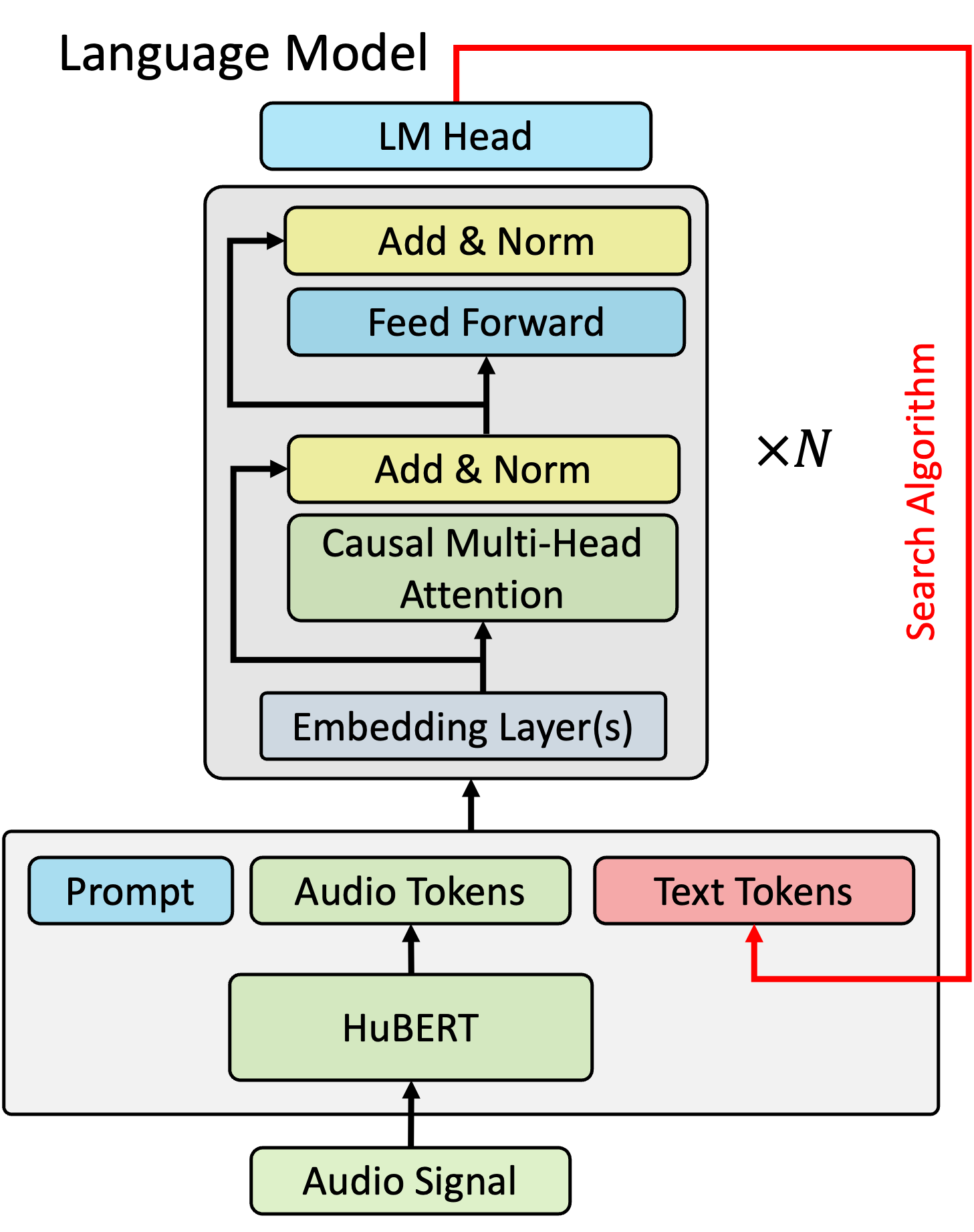
Multi-Modal Retrieval For Large Language Model Based Speech Recognition
Jari Kolehmainen, Aditya Gourav, Prashanth Gurunath Shivakumar, Yile Gu, Ankur Gandhe, Ariya Rastrow, Grant Strimel, Ivan Bulyko
0
0
Retrieval is a widely adopted approach for improving language models leveraging external information. As the field moves towards multi-modal large language models, it is important to extend the pure text based methods to incorporate other modalities in retrieval as well for applications across the wide spectrum of machine learning tasks and data types. In this work, we propose multi-modal retrieval with two approaches: kNN-LM and cross-attention techniques. We demonstrate the effectiveness of our retrieval approaches empirically by applying them to automatic speech recognition tasks with access to external information. Under this setting, we show that speech-based multi-modal retrieval outperforms text based retrieval, and yields up to 50 % improvement in word error rate over the multi-modal language model baseline. Furthermore, we achieve state-of-the-art recognition results on the Spoken-Squad question answering dataset.
6/17/2024