Improving Visual Commonsense in Language Models via Multiple Image Generation
2406.13621
0
0
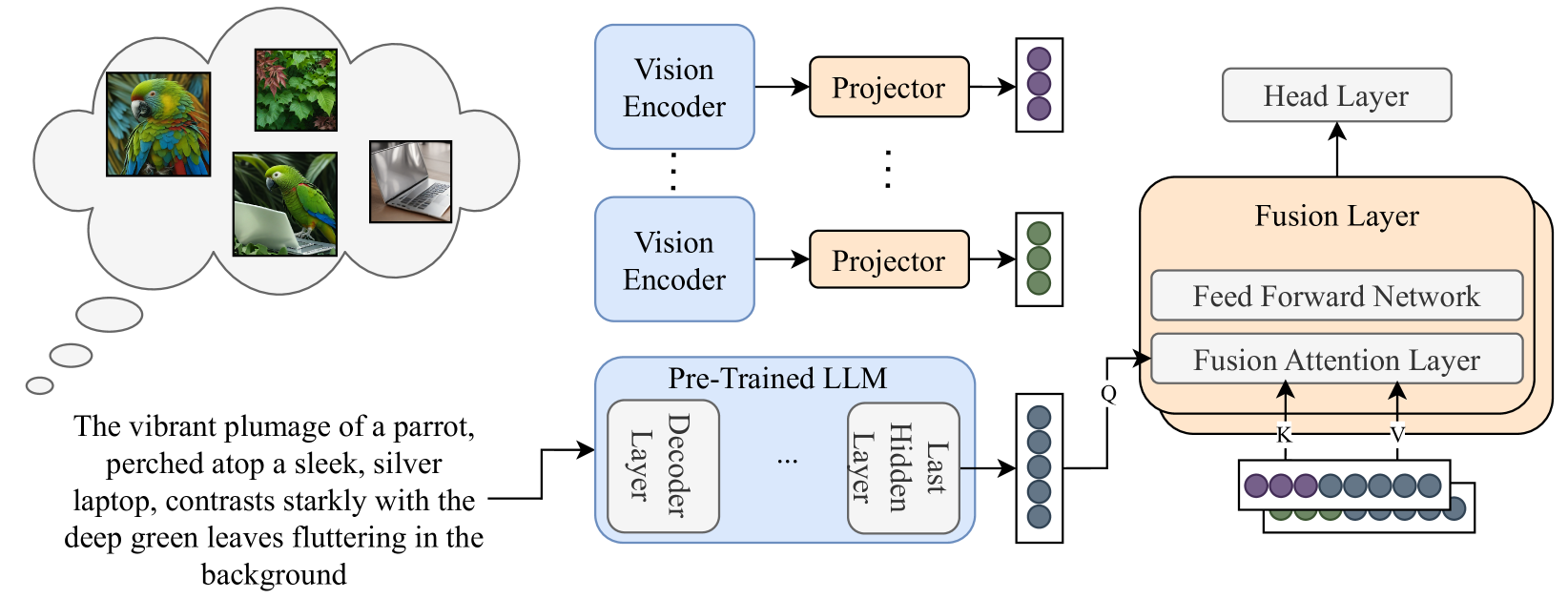
Abstract
Commonsense reasoning is fundamentally based on multimodal knowledge. However, existing large language models (LLMs) are primarily trained using textual data only, limiting their ability to incorporate essential visual information. In contrast, Visual Language Models, which excel at visually-oriented tasks, often fail at non-visual tasks such as basic commonsense reasoning. This divergence highlights a critical challenge - the integration of robust visual understanding with foundational text-based language reasoning. To this end, we introduce a method aimed at enhancing LLMs' visual commonsense. Specifically, our method generates multiple images based on the input text prompt and integrates these into the model's decision-making process by mixing their prediction probabilities. To facilitate multimodal grounded language modeling, we employ a late-fusion layer that combines the projected visual features with the output of a pre-trained LLM conditioned on text only. This late-fusion layer enables predictions based on comprehensive image-text knowledge as well as text only when this is required. We evaluate our approach using several visual commonsense reasoning tasks together with traditional NLP tasks, including common sense reasoning and reading comprehension. Our experimental results demonstrate significant superiority over existing baselines. When applied to recent state-of-the-art LLMs (e.g., Llama3), we observe improvements not only in visual common sense but also in traditional NLP benchmarks. Code and models are available under https://github.com/guyyariv/vLMIG.
Create account to get full access
Overview
- This research paper explores how to improve the visual commonsense reasoning capabilities of large language models through the use of multiple image generation.
- The goal is to enhance the ability of these models to understand and reason about the visual world, which is crucial for tasks like image captioning, visual question answering, and commonsense reasoning.
Plain English Explanation
Large language models like GPT-3 have become incredibly powerful at processing and generating human-like text. However, their understanding of the visual world is often limited, as they primarily rely on textual information. The authors of this paper hypothesize that by training language models to generate multiple images for a given prompt, their visual commonsense reasoning abilities can be significantly improved.
The key idea is that the process of generating multiple plausible images for a particular scenario forces the model to explore and reason about the visual world in a more comprehensive way. This, in turn, can lead to a better understanding of visual commonsense, which is the intuitive knowledge about the relationships between objects, their typical properties, and how they interact in the physical world.
By bridging the gap between language and vision, this approach aims to create more multi-modal large language models that can provide better context and emotion understanding compared to models that rely solely on textual information.
Technical Explanation
The researchers propose a novel framework called VICOR, which stands for "Visual Commonsense Reasoning." The main components of this framework include:
-
Multi-Image Generation: The language model is trained to generate multiple plausible images for a given prompt, rather than a single image. This encourages the model to explore and reason about the visual world more comprehensively.
-
Visual Commonsense Evaluation: The researchers developed a suite of visual commonsense reasoning tasks to assess the model's understanding of the visual world. These tasks cover a wide range of visual commonsense concepts, such as object affordances, spatial relationships, and physical intuitions.
-
Knowledge Distillation: The authors use a knowledge distillation approach to transfer the visual commonsense knowledge from the multi-image generation model to a standard language model, effectively "bridging the gap" between language and vision.
Through extensive experiments, the researchers demonstrate that the VICOR framework significantly improves the visual commonsense reasoning capabilities of large language models, outperforming previous approaches that focused solely on single-image generation or retrieval-based methods.
Critical Analysis
The VICOR framework represents an important step forward in enhancing multi-modal large language models and their ability to reason about the visual world. However, the paper also acknowledges several limitations and areas for future research:
-
Scalability: The multi-image generation approach used in VICOR can be computationally expensive, especially as the number of generated images increases. Exploring more efficient architectures or generation techniques could help address this issue.
-
Generalization: While the model performs well on the specific visual commonsense reasoning tasks developed for the research, it's unclear how well the acquired knowledge generalizes to real-world applications or unseen scenarios. Further evaluation on diverse datasets and use cases would be valuable.
-
Interpretability: As with many complex deep learning models, the inner workings of the VICOR framework can be difficult to interpret. Developing techniques to explain the model's reasoning could make it more transparent and trustworthy.
-
Multimodal Integration: The current approach primarily focuses on bridging the gap between language and vision. Exploring ways to further integrate other modalities, such as audio or tactile information, could lead to even more robust and comprehensive commonsense reasoning.
Overall, this research represents an important advancement in the field of multi-modal large language models and their ability to understand and reason about the visual world. The VICOR framework provides a promising avenue for improving the context and emotion understanding of these powerful models, paving the way for more intelligent and versatile AI systems.
Conclusion
The paper "Improving Visual Commonsense in Language Models via Multiple Image Generation" presents a novel framework called VICOR that effectively enhances the visual commonsense reasoning capabilities of large language models. By training these models to generate multiple plausible images for a given prompt, the researchers demonstrate a significant improvement in the models' understanding of the visual world and their ability to reason about visual commonsense concepts.
This work represents an important step forward in bridging the gap between language and vision and creating more comprehensive multi-modal large language models. As these models become increasingly capable of understanding and reasoning about the visual world, they have the potential to drive advancements in a wide range of applications, from image captioning and visual question answering to commonsense-based decision-making and reasoning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
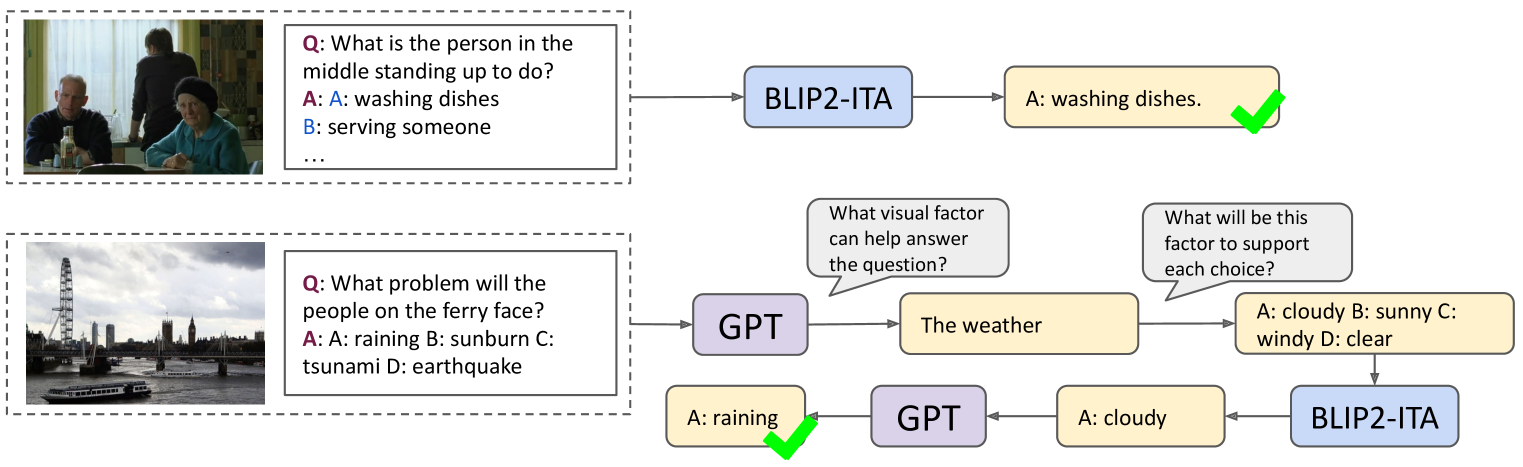
ViCor: Bridging Visual Understanding and Commonsense Reasoning with Large Language Models
Kaiwen Zhou, Kwonjoon Lee, Teruhisa Misu, Xin Eric Wang
0
0
In our work, we explore the synergistic capabilities of pre-trained vision-and-language models (VLMs) and large language models (LLMs) on visual commonsense reasoning (VCR) problems. We find that VLMs and LLMs-based decision pipelines are good at different kinds of VCR problems. Pre-trained VLMs exhibit strong performance for problems involving understanding the literal visual content, which we noted as visual commonsense understanding (VCU). For problems where the goal is to infer conclusions beyond image content, which we noted as visual commonsense inference (VCI), VLMs face difficulties, while LLMs, given sufficient visual evidence, can use commonsense to infer the answer well. We empirically validate this by letting LLMs classify VCR problems into these two categories and show the significant difference between VLM and LLM with image caption decision pipelines on two subproblems. Moreover, we identify a challenge with VLMs' passive perception, which may miss crucial context information, leading to incorrect reasoning by LLMs. Based on these, we suggest a collaborative approach, named ViCor, where pre-trained LLMs serve as problem classifiers to analyze the problem category, then either use VLMs to answer the question directly or actively instruct VLMs to concentrate on and gather relevant visual elements to support potential commonsense inferences. We evaluate our framework on two VCR benchmark datasets and outperform all other methods that do not require in-domain fine-tuning.
5/20/2024
💬
Explaining Multi-modal Large Language Models by Analyzing their Vision Perception
Loris Giulivi, Giacomo Boracchi
0
0
Multi-modal Large Language Models (MLLMs) have demonstrated remarkable capabilities in understanding and generating content across various modalities, such as images and text. However, their interpretability remains a challenge, hindering their adoption in critical applications. This research proposes a novel approach to enhance the interpretability of MLLMs by focusing on the image embedding component. We combine an open-world localization model with a MLLM, thus creating a new architecture able to simultaneously produce text and object localization outputs from the same vision embedding. The proposed architecture greatly promotes interpretability, enabling us to design a novel saliency map to explain any output token, to identify model hallucinations, and to assess model biases through semantic adversarial perturbations.
5/29/2024
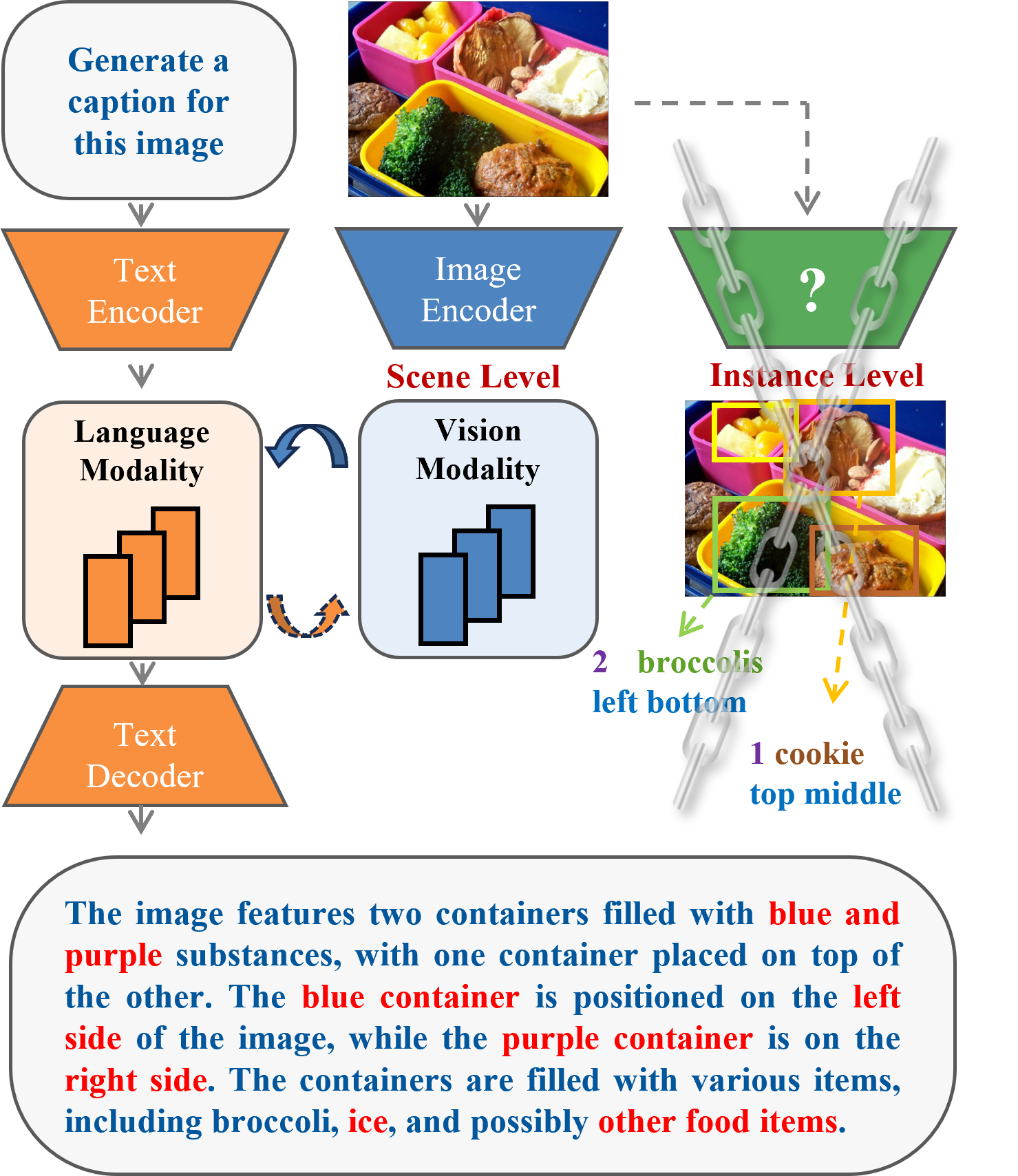
MR-MLLM: Mutual Reinforcement of Multimodal Comprehension and Vision Perception
Guanqun Wang, Xinyu Wei, Jiaming Liu, Ray Zhang, Yichi Zhang, Kevin Zhang, Maurice Chong, Shanghang Zhang
0
0
In recent years, multimodal large language models (MLLMs) have shown remarkable capabilities in tasks like visual question answering and common sense reasoning, while visual perception models have made significant strides in perception tasks, such as detection and segmentation. However, MLLMs mainly focus on high-level image-text interpretations and struggle with fine-grained visual understanding, and vision perception models usually suffer from open-world distribution shifts due to their limited model capacity. To overcome these challenges, we propose the Mutually Reinforced Multimodal Large Language Model (MR-MLLM), a novel framework that synergistically enhances visual perception and multimodal comprehension. First, a shared query fusion mechanism is proposed to harmonize detailed visual inputs from vision models with the linguistic depth of language models, enhancing multimodal comprehension and vision perception synergistically. Second, we propose the perception-enhanced cross-modal integration method, incorporating novel modalities from vision perception outputs, like object detection bounding boxes, to capture subtle visual elements, thus enriching the understanding of both visual and textual data. In addition, an innovative perception-embedded prompt generation mechanism is proposed to embed perceptual information into the language model's prompts, aligning the responses contextually and perceptually for a more accurate multimodal interpretation. Extensive experiments demonstrate MR-MLLM's superior performance in various multimodal comprehension and vision perception tasks, particularly those requiring corner case vision perception and fine-grained language comprehension.
6/26/2024

MORE: Multi-mOdal REtrieval Augmented Generative Commonsense Reasoning
Wanqing Cui, Keping Bi, Jiafeng Guo, Xueqi Cheng
0
0
Since commonsense information has been recorded significantly less frequently than its existence, language models pre-trained by text generation have difficulty to learn sufficient commonsense knowledge. Several studies have leveraged text retrieval to augment the models' commonsense ability. Unlike text, images capture commonsense information inherently but little effort has been paid to effectively utilize them. In this work, we propose a novel Multi-mOdal REtrieval (MORE) augmentation framework, to leverage both text and images to enhance the commonsense ability of language models. Extensive experiments on the Common-Gen task have demonstrated the efficacy of MORE based on the pre-trained models of both single and multiple modalities.
6/17/2024