A More Scalable Sparse Dynamic Data Exchange
2308.13869
0
0
📊
Abstract
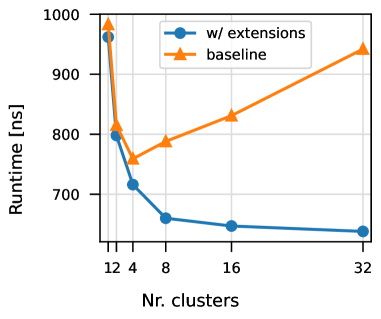
Parallel architectures are continually increasing in performance and scale, while underlying algorithmic infrastructure often fail to take full advantage of available compute power. Within the context of MPI, irregular communication patterns create bottlenecks in parallel applications. One common bottleneck is the sparse dynamic data exchange, often required when forming communication patterns within applications. There are a large variety of approaches for these dynamic exchanges, with optimizations implemented directly in parallel applications. This paper proposes a novel API within an MPI extension library, allowing for applications to utilize the variety of provided optimizations for sparse dynamic data exchange methods. Further, the paper presents novel locality-aware sparse dynamic data exchange algorithms. Finally, performance results show significant speedups up to 20x with the novel locality-aware algorithms.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Parallel computing systems are becoming more powerful and scalable, but the underlying software often struggles to fully utilize the available computing resources.
- One common bottleneck in parallel applications is the sparse dynamic data exchange, where data needs to be exchanged between different parts of the application in an irregular pattern.
- Researchers have proposed various approaches to optimize these dynamic data exchanges, but the solutions are often implemented directly in the parallel applications themselves.
Plain English Explanation
Imagine you have a group of people working on a project together. They are all very skilled and can work quickly, but they need to constantly share information with each other as the project progresses.
The way they share this information is like a complex dance - sometimes one person needs to talk to everyone, sometimes just a few people need to talk, and the patterns are constantly changing. This can create bottlenecks and slow down the whole project.
The researchers in this paper have come up with a new way to help manage this dance of information sharing. They have created a special "toolkit" that the project teams can use to optimize how they share information, without having to completely rewrite their entire project code.
This toolkit provides a variety of different techniques the teams can try, to find the ones that work best for their particular project and the way information needs to be shared. The key innovation is that these optimization techniques are tailored to be aware of where people are located physically or logically, so they can minimize the distance information has to travel.
By using this toolkit, the researchers showed the project teams could speed up their information sharing by up to 20 times, which can make a big difference in how quickly the overall project gets completed.
Technical Explanation
The paper focuses on addressing the challenge of sparse dynamic data exchange patterns in parallel applications running on MPI (Message Passing Interface) systems. These irregular communication patterns can create performance bottlenecks that limit the ability of parallel architectures to fully utilize their available compute power.
The researchers propose a novel API within an MPI extension library that allows applications to leverage a variety of optimized approaches for handling sparse dynamic data exchanges. Crucially, the paper introduces new locality-aware sparse dynamic data exchange algorithms that take into account the physical or logical proximity of the communicating processes.
The evaluation involved running experiments to compare the performance of the proposed locality-aware algorithms against other approaches. The results demonstrate significant speedups of up to 20x for certain workloads, highlighting the potential benefits of the researchers' techniques.
Critical Analysis
The paper provides a solid technical contribution by introducing a flexible API and novel algorithms to address a common performance bottleneck in parallel applications. The locality-aware aspects of the new algorithms are a particularly interesting innovation, as they aim to optimize communication patterns based on the underlying system architecture.
However, the paper does not extensively explore potential limitations or caveats of the proposed approach. For example, it would be valuable to understand how the techniques scale as the number of processes or the complexity of the communication patterns increases. Additionally, the paper does not discuss the overhead or implementation complexity of integrating the new API and algorithms into existing parallel applications.
Further research could also investigate how these techniques perform across a wider range of parallel applications and workloads, as the current evaluation is somewhat limited in scope. Exploring potential extensions or complementary approaches to address other parallel computing bottlenecks could also be an interesting direction for future work.
Overall, this paper presents a promising step forward in optimizing parallel application performance by focusing on the challenges of sparse dynamic data exchange. The novel algorithms and API provide a flexible foundation for further research and development in this area.
Conclusion
This paper tackles the important challenge of improving the performance of parallel computing systems by addressing a common bottleneck related to sparse dynamic data exchange patterns. The researchers have developed a new API and locality-aware algorithms that allow parallel applications to more efficiently manage these irregular communication requirements.
By providing a toolkit of optimized techniques that can be integrated into existing applications, the researchers have created a flexible solution that can be tailored to the specific needs of different parallel computing workloads. The significant performance improvements demonstrated in the evaluation, with speedups of up to 20x, highlight the potential impact of this work.
As parallel architectures continue to grow in power and scale, addressing software-level bottlenecks like sparse dynamic data exchange will be crucial to ensuring these systems can fully deliver on their performance potential. The innovations presented in this paper represent an important step forward in this ongoing effort to unlock the full capabilities of parallel computing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
SpComm3D: A Framework for Enabling Sparse Communication in 3D Sparse Kernels
Nabil Abubaker, Torsten Hoefler
0
0
Existing 3D algorithms for distributed-memory sparse kernels suffer from limited scalability due to reliance on bulk sparsity-agnostic communication. While easier to use, sparsity-agnostic communication leads to unnecessary bandwidth and memory consumption. We present SpComm3D, a framework for enabling sparsity-aware communication and minimal memory footprint such that no unnecessary data is communicated or stored in memory. SpComm3D performs sparse communication efficiently with minimal or no communication buffers to further reduce memory consumption. SpComm3D detaches the local computation at each processor from the communication, allowing flexibility in choosing the best accelerated version for computation. We build 3D algorithms with SpComm3D for the two important sparse ML kernels: Sampled Dense-Dense Matrix Multiplication (SDDMM) and Sparse matrix-matrix multiplication (SpMM). Experimental evaluations on up to 1800 processors demonstrate that SpComm3D has superior scalability and outperforms state-of-the-art sparsity-agnostic methods with up to 20x improvement in terms of communication, memory, and runtime of SDDMM and SpMM. The code is available at: https://github.com/nfabubaker/SpComm3D
5/1/2024
🔍
A Communication Avoiding and Reducing Algorithm for Symmetric Eigenproblem for Very Small Matrices
Takahiro Katagiri, Jun'ichi Iwata, Kazuyuki Uchida
0
0
In this paper, a parallel symmetric eigensolver with very small matrices in massively parallel processing is considered. We define very small matrices that fit the sizes of caches per node in a supercomputer. We assume that the sizes also fit the exa-scale computing requirements of current production runs of an application. To minimize communication time, we added several communication avoiding and communication reducing algorithms based on Message Passing Interface (MPI) non-blocking implementations. A performance evaluation with up to full nodes of the FX10 system indicates that (1) the MPI non-blocking implementation is 3x as efficient as the baseline implementation, (2) the hybrid MPI execution is 1.9x faster than the pure MPI execution, (3) our proposed solver is 2.3x and 22x faster than a ScaLAPACK routine with optimized blocking size and cyclic-cyclic distribution, respectively.
5/2/2024
Optimizing Offload Performance in Heterogeneous MPSoCs
Luca Colagrande, Luca Benini
0
0
Heterogeneous multi-core architectures combine a few host cores, optimized for single-thread performance, with many small energy-efficient accelerator cores for data-parallel processing, on a single chip. Offloading a computation to the many-core acceleration fabric introduces a communication and synchronization cost which reduces the speedup attainable on the accelerator, particularly for small and fine-grained parallel tasks. We demonstrate that by co-designing the hardware and offload routines, we can increase the speedup of an offloaded DAXPY kernel by as much as 47.9%. Furthermore, we show that it is possible to accurately model the runtime of an offloaded application, accounting for the offload overheads, with as low as 1% MAPE error, enabling optimal offload decisions under offload execution time constraints.
4/3/2024
Efficient Distributed Data Structures for Future Many-core Architectures
Panagiota Fatourou, Nikolaos D. Kallimanis, Eleni Kanellou, Odysseas Makridakis, Christi Symeonidou
0
0
We study general techniques for implementing distributed data structures on top of future many-core architectures with non cache-coherent or partially cache-coherent memory. With the goal of contributing towards what might become, in the future, the concurrency utilities package in Java collections for such architectures, we end up with a comprehensive collection of data structures by considering different variants of these techniques. To achieve scalability, we study a generic scheme which makes all our implementations hierarchical. We consider a collection of known techniques for improving the scalability of concurrent data structures and we adjust them to work in our setting. We have performed experiments which illustrate that some of these techniques have indeed high impact on achieving scalability. Our experiments also reveal the performance and scalability power of the hierarchical approach. We finally present experiments to study energy consumption aspects of the proposed techniques by using an energy model recently proposed for such architectures.
4/9/2024