Efficient Distributed Data Structures for Future Many-core Architectures

0
Sign in to get full access
Overview
- Exploring efficient distributed data structures for future many-core architectures
- Focuses on designing data structures that can effectively utilize the resources of emerging hardware with massive parallelism
- Aims to address challenges in scalability, synchronization, and memory efficiency for distributed data structures
Plain English Explanation
Modern computers are becoming increasingly powerful, with many cores (processors) working together in parallel. This trend of "many-core" architectures presents both opportunities and challenges for how we design and use data structures - the building blocks of software programs.
The research paper examines ways to create efficient distributed data structures that can take full advantage of these new many-core systems. Distributed data structures allow data to be spread across multiple computers or processors, enabling greater parallelism and scalability. More Scalable Sparse Dynamic Data Exchange and Sharding: Distributed Data in Databases - A Critical Review are two related areas of research on distributed data structures.
The key goals are to design data structures that can efficiently leverage the massive parallelism of future many-core chips, while also addressing challenges like synchronization (coordinating access between multiple processors) and memory usage. This could lead to significant performance improvements for applications that rely on distributed data, such as Rip: A Linked List for Distributed Systems, CSSTS: Dynamic Data Structures for Concurrent Partial Orders, and Haina: A Decentralized Secure Storage Framework Based on Blockchain.
Technical Explanation
The paper provides an abstract description of the hardware characteristics that the researchers expect to see in future many-core systems, including features like high core counts, heterogeneous cores, coherent shared memory, and specialized accelerators. This serves as the basis for designing efficient distributed data structures that can effectively harness the capabilities of this emerging hardware.
The researchers then discuss several key design principles for distributed data structures in this context, such as:
- Minimizing synchronization overhead between cores to improve scalability
- Leveraging specialized hardware features (e.g., accelerators) to offload certain operations
- Optimizing data placement and access patterns to reduce memory usage and improve cache efficiency
The paper also explores various practical implementation strategies and trade-offs, such as the use of partitioned data structures, lock-free synchronization techniques, and specialized data layouts. The researchers present examples of how these principles can be applied to design efficient distributed versions of commonly used data structures like hash tables and priority queues.
Critical Analysis
The paper provides a thoughtful and well-reasoned approach to designing distributed data structures for future many-core architectures. The authors carefully consider the hardware trends and challenges, and their proposed design principles seem well-aligned with addressing the key issues of scalability, synchronization, and memory efficiency.
That said, the paper is primarily focused on the high-level architectural and design aspects, and does not delve deeply into the implementation details or empirical evaluation of the proposed techniques. Further research would be needed to fully validate the effectiveness of these approaches in real-world scenarios and to explore potential limitations or edge cases.
Additionally, the paper does not address some broader questions, such as the impact of these distributed data structures on programming models, software development workflows, and system-level resource management. These are important considerations that could influence the ultimate adoption and impact of the proposed ideas.
Conclusion
This research paper presents a forward-looking exploration of efficient distributed data structures for the many-core architectures of the future. By carefully considering the hardware trends and design principles, the authors outline a promising path for creating data structures that can effectively leverage the massive parallelism of emerging systems.
While further research and validation is needed, the ideas presented in this paper have the potential to drive significant performance improvements for a wide range of distributed and parallel applications. As the computing industry continues its relentless march towards ever-greater levels of parallelism, these types of innovative data structure designs will be crucial for unlocking the full potential of the hardware.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Efficient Distributed Data Structures for Future Many-core Architectures
Panagiota Fatourou, Nikolaos D. Kallimanis, Eleni Kanellou, Odysseas Makridakis, Christi Symeonidou
We study general techniques for implementing distributed data structures on top of future many-core architectures with non cache-coherent or partially cache-coherent memory. With the goal of contributing towards what might become, in the future, the concurrency utilities package in Java collections for such architectures, we end up with a comprehensive collection of data structures by considering different variants of these techniques. To achieve scalability, we study a generic scheme which makes all our implementations hierarchical. We consider a collection of known techniques for improving the scalability of concurrent data structures and we adjust them to work in our setting. We have performed experiments which illustrate that some of these techniques have indeed high impact on achieving scalability. Our experiments also reveal the performance and scalability power of the hierarchical approach. We finally present experiments to study energy consumption aspects of the proposed techniques by using an energy model recently proposed for such architectures.
Read more4/9/2024
🗣️
0
Concurrent aggregate queries
Gal Sela, Erez Petrank
Concurrent data structures serve as fundamental building blocks for concurrent computing. Many concurrent counterparts have been designed for basic sequential mechanisms; however, one notable omission is a concurrent tree that supports aggregate queries. Aggregate queries essentially compile succinct information about a range of data items, for example, calculating the average salary of employees in their 30s. Such queries play an essential role in various applications and are commonly taught in undergraduate data structures courses. In this paper, we formalize a type of aggregate queries that can be efficiently supported by concurrent trees and present a design for implementing these queries on concurrent trees. We bring two algorithms implementing this design, where one optimizes for tree update time, while the other optimizes for aggregate query time. We analyze their correctness and complexity, demonstrating the trade-offs between query time and update time.
Read more5/14/2024
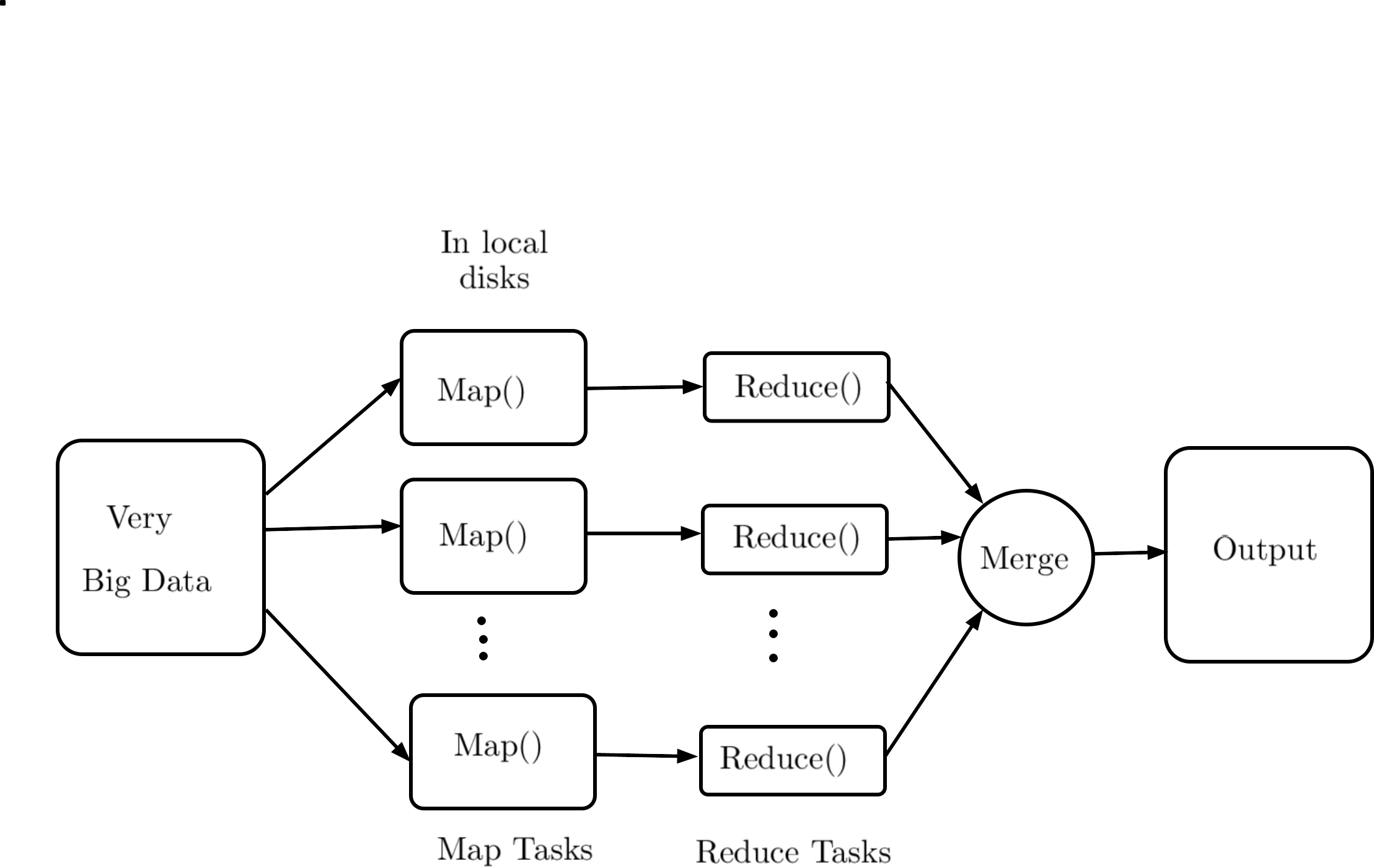
0
Analysis of Distributed Algorithms for Big-data
Rajendra Purohit, K R Chowdhary, S D Purohit
The parallel and distributed processing are becoming de facto industry standard, and a large part of the current research is targeted on how to make computing scalable and distributed, dynamically, without allocating the resources on permanent basis. The present article focuses on the study and performance of distributed and parallel algorithms their file systems, to achieve scalability at local level (OpenMP platform), and at global level where computing and file systems are distributed. Various applications, algorithms,file systems have been used to demonstrate the areas, and their performance studies have been presented. The systems and applications chosen here are of open-source nature, due to their wider applicability.
Read more4/10/2024
📊
10
Concurrent Data Structures Made Easy (Extended Version)
Callista Le, Kiran Gopinathan, Koon Wen Lee, Seth Gilbert, Ilya Sergey
Design of an efficient thread-safe concurrent data structure is a balancing act between its implementation complexity and performance. Lock-based concurrent data structures, which are relatively easy to derive from their sequential counterparts and to prove thread-safe, suffer from poor throughput under even light multi-threaded workload. At the same time, lock-free concurrent structures allow for high throughput, but are notoriously difficult to get right and require careful reasoning to formally establish their correctness. We explore a solution to this conundrum based on batch parallelism, an approach for designing concurrent data structures via a simple insight: efficiently processing a batch of a priori known operations in parallel is easier than optimising performance for a stream of arbitrary asynchronous requests. Alas, batch-parallel structures have not seen wide practical adoption due to (i) the inconvenience of having to structure multi-threaded programs to explicitly group operations and (ii) the lack of a systematic methodology to implement batch-parallel structures as simply as lock-based ones. We present OBatcher-an OCaml library that streamlines the design, implementation, and usage of batch-parallel structures. It solves the first challenge (how to use) by suggesting a new lightweight implicit batching design that is built on top of generic asynchronous programming mechanisms. The second challenge (how to implement) is addressed by identifying a family of strategies for converting common sequential structures into efficient batch-parallel ones. We showcase OBatcher with a diverse set of benchmarks. Our evaluation of all the implementations on large asynchronous workloads shows that (a) they consistently outperform the corresponding coarse-grained lock-based implementations and that (b) their throughput scales reasonably with the number of processors.
Read more8/27/2024