More Text, Less Point: Towards 3D Data-Efficient Point-Language Understanding

0

Sign in to get full access
Overview
- This paper proposes a novel 3D point-language understanding approach called
MoreTextLessPoint(MTLP) that leverages language to efficiently learn representations of 3D point clouds. - The approach combines language and 3D point cloud data to learn joint representations, enabling data-efficient downstream tasks compared to purely visual methods.
- Key contributions include a new 3D-language alignment model and a self-supervised pre-training strategy that outperforms prior state-of-the-art methods on 3D understanding benchmarks.
Plain English Explanation
The paper introduces a new way to combine language and 3D point cloud data to improve how AI systems understand 3D environments. The key idea is to use language as a powerful signal to help the AI system learn efficient representations of 3D data, rather than relying solely on the 3D data itself.
By aligning the language descriptions with the corresponding 3D point clouds, the AI model can learn joint representations that capture both the visual and semantic aspects of the 3D data. This allows the model to perform 3D understanding tasks, like object detection or scene segmentation, in a more data-efficient way compared to previous approaches that only use 3D data.
The paper presents a specific model architecture and training strategy called MoreTextLessPoint (MTLP) that demonstrates the effectiveness of this language-guided 3D learning approach. MTLP outperforms prior state-of-the-art methods on standard 3D understanding benchmarks, showing the benefits of leveraging language to make 3D learning more efficient.
Technical Explanation
The paper introduces the MoreTextLessPoint (MTLP) approach for 3D point-language understanding. MTLP consists of two key components:
-
3D-Language Alignment Model: This module learns to align language descriptions with their corresponding 3D point cloud representations. By learning this cross-modal alignment, the model can capture the semantic information in the language and use it to enhance the learning of 3D representations.
-
Self-Supervised Pre-Training Strategy: The authors propose a novel pre-training strategy that leverages both 3D point cloud data and language descriptions. This pre-training phase allows the model to learn rich, transferable representations that can then be fine-tuned for various downstream 3D understanding tasks.
The paper evaluates MTLP on several 3D benchmarks, including object detection, semantic segmentation, and 3D scene understanding. The results show that MTLP outperforms prior state-of-the-art methods, particularly in data-efficient settings where only limited 3D training data is available. This highlights the power of the language-guided learning approach to make 3D understanding more sample-efficient.
Critical Analysis
The paper presents a promising approach for leveraging language to improve 3D understanding, but there are a few potential limitations and areas for further research:
-
Generalization to Diverse Language: The experiments in the paper focus on relatively simple language descriptions, and it's unclear how well the approach would generalize to more complex, open-ended language. Further research is needed to understand the limits of the language-guided learning approach.
-
Interpretability and Explainability: While the language-guided learning approach leads to improved performance, the paper does not provide much insight into how the language information is actually used by the model to enhance 3D understanding. More work is needed to understand the internal mechanisms and make the models more interpretable.
-
Scalability to Large-Scale 3D Data: The experiments in the paper are conducted on relatively small-scale 3D datasets. It would be important to evaluate the approach on larger, more diverse 3D datasets to understand its scalability and robustness.
-
Real-World Applicability: The paper focuses on academic benchmarks, and more research is needed to understand how the approach would perform in real-world 3D understanding scenarios, such as robotics or augmented reality applications.
Despite these potential limitations, the paper presents a compelling direction for integrating language and 3D data to improve AI's 3D understanding capabilities in a more data-efficient manner.
Conclusion
This paper introduces the MoreTextLessPoint (MTLP) approach, which leverages language descriptions to learn more efficient representations of 3D point cloud data. By aligning language and 3D information, MTLP can outperform prior state-of-the-art methods on 3D understanding tasks, especially in data-constrained settings.
The language-guided learning approach shown in this paper represents an important step towards developing AI systems that can better understand and reason about the 3D world around us. As AI continues to advance, integrating language and 3D data will likely become increasingly crucial for building intelligent systems that can interact with and comprehend the rich, multimodal nature of the physical environment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
More Text, Less Point: Towards 3D Data-Efficient Point-Language Understanding
Yuan Tang, Xu Han, Xianzhi Li, Qiao Yu, Jinfeng Xu, Yixue Hao, Long Hu, Min Chen
Enabling Large Language Models (LLMs) to comprehend the 3D physical world remains a significant challenge. Due to the lack of large-scale 3D-text pair datasets, the success of LLMs has yet to be replicated in 3D understanding. In this paper, we rethink this issue and propose a new task: 3D Data-Efficient Point-Language Understanding. The goal is to enable LLMs to achieve robust 3D object understanding with minimal 3D point cloud and text data pairs. To address this task, we introduce GreenPLM, which leverages more text data to compensate for the lack of 3D data. First, inspired by using CLIP to align images and text, we utilize a pre-trained point cloud-text encoder to map the 3D point cloud space to the text space. This mapping leaves us to seamlessly connect the text space with LLMs. Once the point-text-LLM connection is established, we further enhance text-LLM alignment by expanding the intermediate text space, thereby reducing the reliance on 3D point cloud data. Specifically, we generate 6M free-text descriptions of 3D objects, and design a three-stage training strategy to help LLMs better explore the intrinsic connections between different modalities. To achieve efficient modality alignment, we design a zero-parameter cross-attention module for token pooling. Extensive experimental results show that GreenPLM requires only 12% of the 3D training data used by existing state-of-the-art models to achieve superior 3D understanding. Remarkably, GreenPLM also achieves competitive performance using text-only data. The code and weights are available at: https://github.com/TangYuan96/GreenPLM.
Read more9/6/2024
💬
0
PointLLM: Empowering Large Language Models to Understand Point Clouds
Runsen Xu, Xiaolong Wang, Tai Wang, Yilun Chen, Jiangmiao Pang, Dahua Lin
The unprecedented advancements in Large Language Models (LLMs) have shown a profound impact on natural language processing but are yet to fully embrace the realm of 3D understanding. This paper introduces PointLLM, a preliminary effort to fill this gap, enabling LLMs to understand point clouds and offering a new avenue beyond 2D visual data. PointLLM understands colored object point clouds with human instructions and generates contextually appropriate responses, illustrating its grasp of point clouds and common sense. Specifically, it leverages a point cloud encoder with a powerful LLM to effectively fuse geometric, appearance, and linguistic information. We collect a novel dataset comprising 660K simple and 70K complex point-text instruction pairs to enable a two-stage training strategy: aligning latent spaces and subsequently instruction-tuning the unified model. To rigorously evaluate the perceptual and generalization capabilities of PointLLM, we establish two benchmarks: Generative 3D Object Classification and 3D Object Captioning, assessed through three different methods, including human evaluation, GPT-4/ChatGPT evaluation, and traditional metrics. Experimental results reveal PointLLM's superior performance over existing 2D and 3D baselines, with a notable achievement in human-evaluated object captioning tasks where it surpasses human annotators in over 50% of the samples. Codes, datasets, and benchmarks are available at https://github.com/OpenRobotLab/PointLLM .
Read more9/10/2024
💬
0
MiniGPT-3D: Efficiently Aligning 3D Point Clouds with Large Language Models using 2D Priors
Yuan Tang, Xu Han, Xianzhi Li, Qiao Yu, Yixue Hao, Long Hu, Min Chen
Large 2D vision-language models (2D-LLMs) have gained significant attention by bridging Large Language Models (LLMs) with images using a simple projector. Inspired by their success, large 3D point cloud-language models (3D-LLMs) also integrate point clouds into LLMs. However, directly aligning point clouds with LLM requires expensive training costs, typically in hundreds of GPU-hours on A100, which hinders the development of 3D-LLMs. In this paper, we introduce MiniGPT-3D, an efficient and powerful 3D-LLM that achieves multiple SOTA results while training for only 27 hours on one RTX 3090. Specifically, we propose to align 3D point clouds with LLMs using 2D priors from 2D-LLMs, which can leverage the similarity between 2D and 3D visual information. We introduce a novel four-stage training strategy for modality alignment in a cascaded way, and a mixture of query experts module to adaptively aggregate features with high efficiency. Moreover, we utilize parameter-efficient fine-tuning methods LoRA and Norm fine-tuning, resulting in only 47.8M learnable parameters, which is up to 260x fewer than existing methods. Extensive experiments show that MiniGPT-3D achieves SOTA on 3D object classification and captioning tasks, with significantly cheaper training costs. Notably, MiniGPT-3D gains an 8.12 increase on GPT-4 evaluation score for the challenging object captioning task compared to ShapeLLM-13B, while the latter costs 160 total GPU-hours on 8 A800. We are the first to explore the efficient 3D-LLM, offering new insights to the community. Code and weights are available at https://github.com/TangYuan96/MiniGPT-3D.
Read more5/3/2024
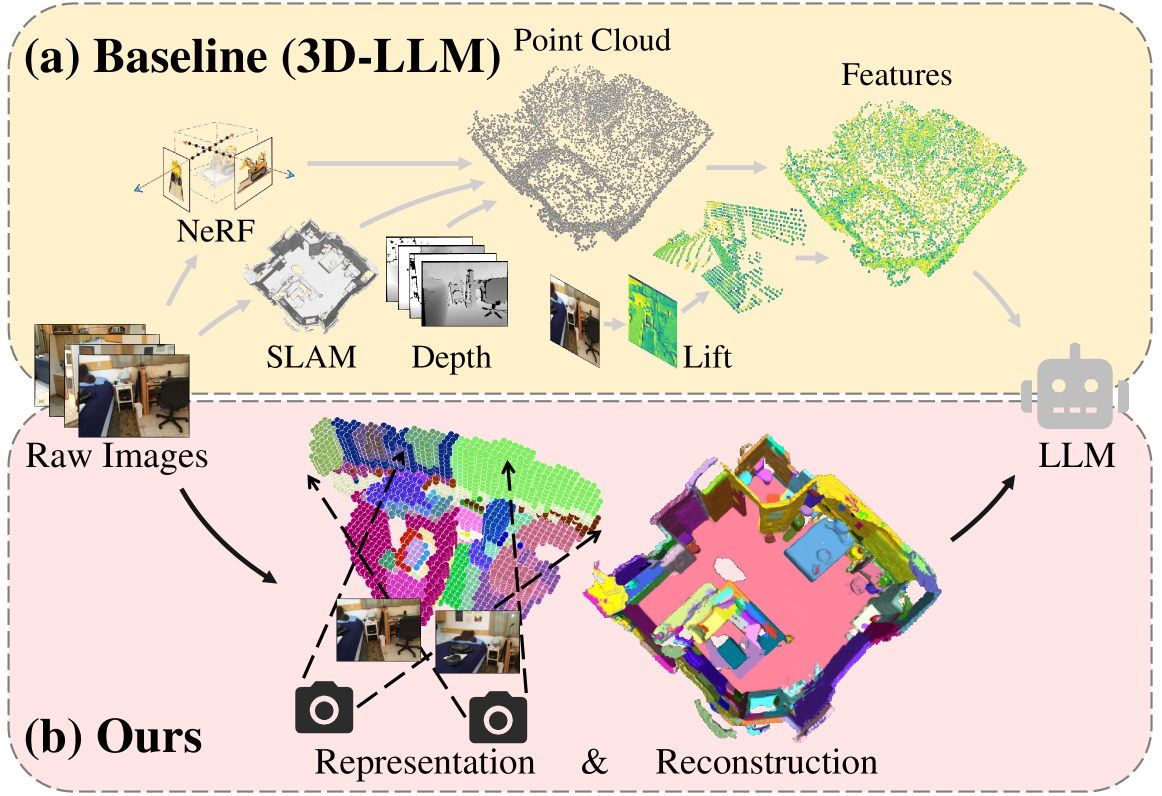
0
Unified Scene Representation and Reconstruction for 3D Large Language Models
Tao Chu, Pan Zhang, Xiaoyi Dong, Yuhang Zang, Qiong Liu, Jiaqi Wang
Enabling Large Language Models (LLMs) to interact with 3D environments is challenging. Existing approaches extract point clouds either from ground truth (GT) geometry or 3D scenes reconstructed by auxiliary models. Text-image aligned 2D features from CLIP are then lifted to point clouds, which serve as inputs for LLMs. However, this solution lacks the establishment of 3D point-to-point connections, leading to a deficiency of spatial structure information. Concurrently, the absence of integration and unification between the geometric and semantic representations of the scene culminates in a diminished level of 3D scene understanding. In this paper, we demonstrate the importance of having a unified scene representation and reconstruction framework, which is essential for LLMs in 3D scenes. Specifically, we introduce Uni3DR^2 extracts 3D geometric and semantic aware representation features via the frozen pre-trained 2D foundation models (e.g., CLIP and SAM) and a multi-scale aggregate 3D decoder. Our learned 3D representations not only contribute to the reconstruction process but also provide valuable knowledge for LLMs. Experimental results validate that our Uni3DR^2 yields convincing gains over the baseline on the 3D reconstruction dataset ScanNet (increasing F-Score by +1.8%). When applied to LLMs, our Uni3DR^2-LLM exhibits superior performance over the baseline on the 3D vision-language understanding dataset ScanQA (increasing BLEU-1 by +4.0% and +4.2% on the val set and test set, respectively). Furthermore, it outperforms the state-of-the-art method that uses additional GT point clouds on both ScanQA and 3DMV-VQA.
Read more4/22/2024