Morphable Diffusion: 3D-Consistent Diffusion for Single-image Avatar Creation
2401.04728
0
1
🤿
Abstract
Recent advances in generative diffusion models have enabled the previously unfeasible capability of generating 3D assets from a single input image or a text prompt. In this work, we aim to enhance the quality and functionality of these models for the task of creating controllable, photorealistic human avatars. We achieve this by integrating a 3D morphable model into the state-of-the-art multi-view-consistent diffusion approach. We demonstrate that accurate conditioning of a generative pipeline on the articulated 3D model enhances the baseline model performance on the task of novel view synthesis from a single image. More importantly, this integration facilitates a seamless and accurate incorporation of facial expression and body pose control into the generation process. To the best of our knowledge, our proposed framework is the first diffusion model to enable the creation of fully 3D-consistent, animatable, and photorealistic human avatars from a single image of an unseen subject; extensive quantitative and qualitative evaluations demonstrate the advantages of our approach over existing state-of-the-art avatar creation models on both novel view and novel expression synthesis tasks. The code for our project is publicly available.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Researchers have developed a new method to generate high-quality, controllable 3D human avatars from a single input image or text prompt.
- The approach integrates a 3D morphable model into a state-of-the-art diffusion-based generation framework, enabling accurate control over facial expressions and body poses.
- This is the first diffusion model capable of creating fully 3D-consistent, animatable, and photorealistic human avatars from a single image of an unseen subject.
Plain English Explanation
Generating realistic 3D human avatars has been a long-standing challenge in computer graphics and animation. Traditional methods often required extensive manual work or specialized equipment to capture and reconstruct 3D models.
This new research explores using diffusion models, a type of advanced AI algorithm, to streamline the avatar creation process. Diffusion models can generate novel images by learning from a large dataset of existing images. The researchers have found a way to incorporate a 3D morphable model into this diffusion-based framework, allowing the system to generate 3D avatars that are not only visually convincing, but also fully articulated and animatable.
This means the generated avatars can be posed, animated, and have their facial expressions changed - all starting from a single input image or even just a text description. The key innovation is that the 3D structural information is tightly integrated into the generation process, ensuring the final avatars are fully 3D-consistent and lifelike.
This technology could have applications in areas like video games, virtual reality, and even digital humans for films and advertising. By simplifying the avatar creation process, it could make it easier for a wider range of creators to build immersive 3D worlds and characters.
Technical Explanation
The core of the researchers' approach is the integration of a 3D morphable model into a state-of-the-art multi-view-consistent diffusion model. The 3D morphable model provides a compact parametric representation of the 3D facial and body structure, which the diffusion model can then use to generate photorealistic avatars with accurate 3D geometry.
Specifically, the researchers condition the diffusion model on the 3D morphable model parameters, allowing it to generate images that are consistently aligned with the underlying 3D structure. This enables the model to synthesize novel views of the avatar from a single input image, as well as seamlessly incorporate controls for facial expressions and body poses.
The researchers evaluated their framework on a variety of tasks, including novel view synthesis and novel expression synthesis. They demonstrated significant improvements over existing avatar creation methods, producing avatars that are not only visually realistic, but also fully 3D-consistent and animatable.
Critical Analysis
The researchers acknowledge that their current framework is limited to generating avatars of a single person from a single input image. Extending this to handle multiple individuals or generating avatars from textual descriptions alone remains an area for future work.
Additionally, while the generated avatars are highly photorealistic, there may still be room for improvement in terms of capturing subtle nuances of human appearance and motion. The researchers note that further advancements in 3D morphable modeling and diffusion-based generation could help address these challenges.
It would also be valuable to explore the ethical implications of this technology, particularly around issues of privacy, consent, and the potential for misuse. As these avatar generation capabilities become more sophisticated, it will be important to consider appropriate guidelines and safeguards.
Overall, this research represents a significant advancement in the field of 3D avatar creation, with the potential to greatly simplify and streamline the process of building immersive virtual environments and characters. As the technology continues to evolve, it will be interesting to see how it is applied and what new possibilities it unlocks for creators and users alike.
Conclusion
This novel approach to 3D avatar generation leverages the power of diffusion models and 3D morphable models to enable the creation of highly realistic, animatable human avatars from a single input image or text prompt. By tightly integrating the 3D structural information into the generation process, the researchers have overcome key limitations of previous avatar creation methods, paving the way for more accessible and versatile 3D content creation.
While there are still areas for improvement and ethical considerations to address, this research represents an exciting step forward in the field of computer graphics and virtual reality. As the technology continues to advance, it could open up new avenues for more immersive and personalized digital experiences across a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Generating Images with 3D Annotations Using Diffusion Models
Wufei Ma, Qihao Liu, Jiahao Wang, Angtian Wang, Xiaoding Yuan, Yi Zhang, Zihao Xiao, Guofeng Zhang, Beijia Lu, Ruxiao Duan, Yongrui Qi, Adam Kortylewski, Yaoyao Liu, Alan Yuille
0
0
Diffusion models have emerged as a powerful generative method, capable of producing stunning photo-realistic images from natural language descriptions. However, these models lack explicit control over the 3D structure in the generated images. Consequently, this hinders our ability to obtain detailed 3D annotations for the generated images or to craft instances with specific poses and distances. In this paper, we propose 3D Diffusion Style Transfer (3D-DST), which incorporates 3D geometry control into diffusion models. Our method exploits ControlNet, which extends diffusion models by using visual prompts in addition to text prompts. We generate images of the 3D objects taken from 3D shape repositories (e.g., ShapeNet and Objaverse), render them from a variety of poses and viewing directions, compute the edge maps of the rendered images, and use these edge maps as visual prompts to generate realistic images. With explicit 3D geometry control, we can easily change the 3D structures of the objects in the generated images and obtain ground-truth 3D annotations automatically. This allows us to improve a wide range of vision tasks, e.g., classification and 3D pose estimation, in both in-distribution (ID) and out-of-distribution (OOD) settings. We demonstrate the effectiveness of our method through extensive experiments on ImageNet-100/200, ImageNet-R, PASCAL3D+, ObjectNet3D, and OOD-CV. The results show that our method significantly outperforms existing methods, e.g., 3.8 percentage points on ImageNet-100 using DeiT-B.
4/5/2024
📈
4D Facial Expression Diffusion Model
Kaifeng Zou, Sylvain Faisan, Boyang Yu, S'ebastien Valette, Hyewon Seo
0
0
Facial expression generation is one of the most challenging and long-sought aspects of character animation, with many interesting applications. The challenging task, traditionally having relied heavily on digital craftspersons, remains yet to be explored. In this paper, we introduce a generative framework for generating 3D facial expression sequences (i.e. 4D faces) that can be conditioned on different inputs to animate an arbitrary 3D face mesh. It is composed of two tasks: (1) Learning the generative model that is trained over a set of 3D landmark sequences, and (2) Generating 3D mesh sequences of an input facial mesh driven by the generated landmark sequences. The generative model is based on a Denoising Diffusion Probabilistic Model (DDPM), which has achieved remarkable success in generative tasks of other domains. While it can be trained unconditionally, its reverse process can still be conditioned by various condition signals. This allows us to efficiently develop several downstream tasks involving various conditional generation, by using expression labels, text, partial sequences, or simply a facial geometry. To obtain the full mesh deformation, we then develop a landmark-guided encoder-decoder to apply the geometrical deformation embedded in landmarks on a given facial mesh. Experiments show that our model has learned to generate realistic, quality expressions solely from the dataset of relatively small size, improving over the state-of-the-art methods. Videos and qualitative comparisons with other methods can be found at url{https://github.com/ZOUKaifeng/4DFM}.
4/16/2024
ShapeFusion: A 3D diffusion model for localized shape editing
Rolandos Alexandros Potamias, Michail Tarasiou, Stylianos Ploumpis, Stefanos Zafeiriou
0
0
In the realm of 3D computer vision, parametric models have emerged as a ground-breaking methodology for the creation of realistic and expressive 3D avatars. Traditionally, they rely on Principal Component Analysis (PCA), given its ability to decompose data to an orthonormal space that maximally captures shape variations. However, due to the orthogonality constraints and the global nature of PCA's decomposition, these models struggle to perform localized and disentangled editing of 3D shapes, which severely affects their use in applications requiring fine control such as face sculpting. In this paper, we leverage diffusion models to enable diverse and fully localized edits on 3D meshes, while completely preserving the un-edited regions. We propose an effective diffusion masking training strategy that, by design, facilitates localized manipulation of any shape region, without being limited to predefined regions or to sparse sets of predefined control vertices. Following our framework, a user can explicitly set their manipulation region of choice and define an arbitrary set of vertices as handles to edit a 3D mesh. Compared to the current state-of-the-art our method leads to more interpretable shape manipulations than methods relying on latent code state, greater localization and generation diversity while offering faster inference than optimization based approaches. Project page: https://rolpotamias.github.io/Shapefusion/
4/5/2024
DiffusionGAN3D: Boosting Text-guided 3D Generation and Domain Adaptation by Combining 3D GANs and Diffusion Priors
Biwen Lei, Kai Yu, Mengyang Feng, Miaomiao Cui, Xuansong Xie
0
0
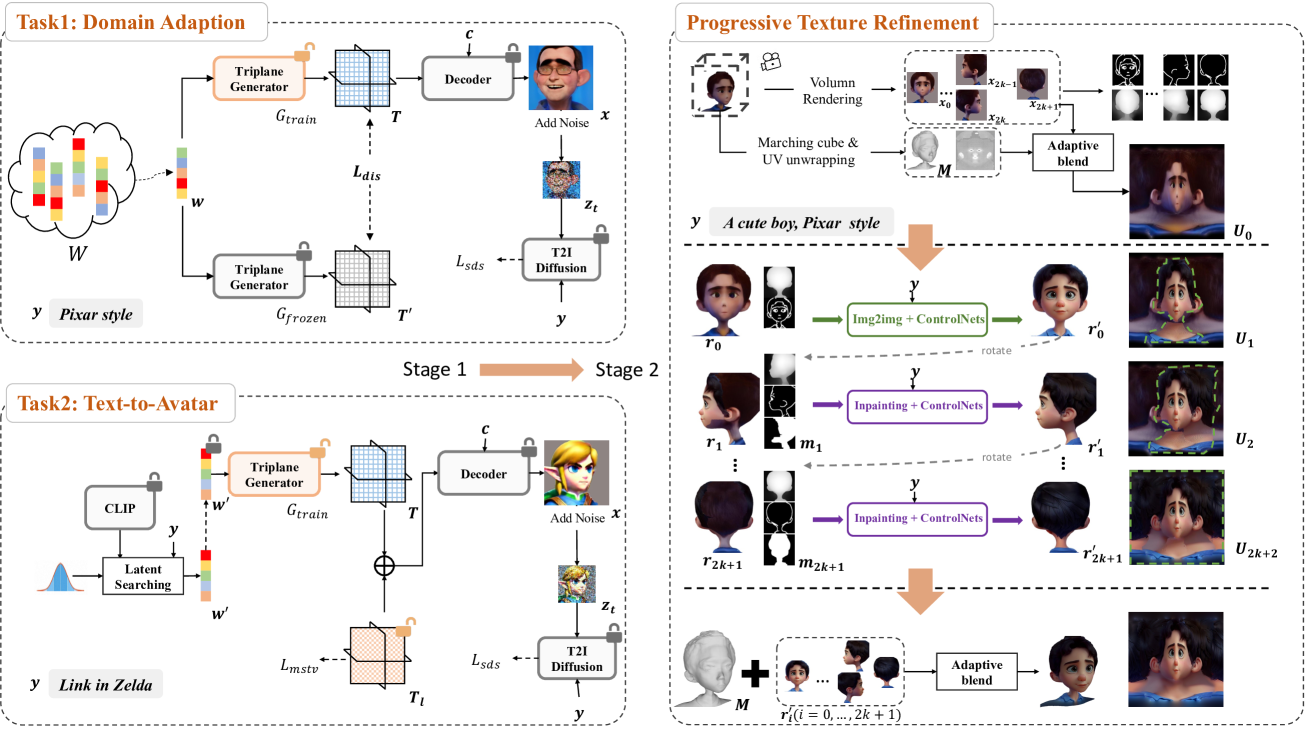
Text-guided domain adaptation and generation of 3D-aware portraits find many applications in various fields. However, due to the lack of training data and the challenges in handling the high variety of geometry and appearance, the existing methods for these tasks suffer from issues like inflexibility, instability, and low fidelity. In this paper, we propose a novel framework DiffusionGAN3D, which boosts text-guided 3D domain adaptation and generation by combining 3D GANs and diffusion priors. Specifically, we integrate the pre-trained 3D generative models (e.g., EG3D) and text-to-image diffusion models. The former provides a strong foundation for stable and high-quality avatar generation from text. And the diffusion models in turn offer powerful priors and guide the 3D generator finetuning with informative direction to achieve flexible and efficient text-guided domain adaptation. To enhance the diversity in domain adaptation and the generation capability in text-to-avatar, we introduce the relative distance loss and case-specific learnable triplane respectively. Besides, we design a progressive texture refinement module to improve the texture quality for both tasks above. Extensive experiments demonstrate that the proposed framework achieves excellent results in both domain adaptation and text-to-avatar tasks, outperforming existing methods in terms of generation quality and efficiency. The project homepage is at https://younglbw.github.io/DiffusionGAN3D-homepage/.
4/15/2024