Generating Images with 3D Annotations Using Diffusion Models
2306.08103
0
0

Abstract
Diffusion models have emerged as a powerful generative method, capable of producing stunning photo-realistic images from natural language descriptions. However, these models lack explicit control over the 3D structure in the generated images. Consequently, this hinders our ability to obtain detailed 3D annotations for the generated images or to craft instances with specific poses and distances. In this paper, we propose 3D Diffusion Style Transfer (3D-DST), which incorporates 3D geometry control into diffusion models. Our method exploits ControlNet, which extends diffusion models by using visual prompts in addition to text prompts. We generate images of the 3D objects taken from 3D shape repositories (e.g., ShapeNet and Objaverse), render them from a variety of poses and viewing directions, compute the edge maps of the rendered images, and use these edge maps as visual prompts to generate realistic images. With explicit 3D geometry control, we can easily change the 3D structures of the objects in the generated images and obtain ground-truth 3D annotations automatically. This allows us to improve a wide range of vision tasks, e.g., classification and 3D pose estimation, in both in-distribution (ID) and out-of-distribution (OOD) settings. We demonstrate the effectiveness of our method through extensive experiments on ImageNet-100/200, ImageNet-R, PASCAL3D+, ObjectNet3D, and OOD-CV. The results show that our method significantly outperforms existing methods, e.g., 3.8 percentage points on ImageNet-100 using DeiT-B.
Create account to get full access
Overview
- This paper proposes a method to give diffusion models the ability to control the 3D geometry of generated images.
- The key idea is to incorporate 3D shape information into the diffusion model training process, allowing the model to generate images with specific 3D structures.
- The authors evaluate their approach on various 3D object datasets and demonstrate improvements in 3D shape control compared to previous diffusion models.
Plain English Explanation
Diffusion models are a type of machine learning algorithm that can be used to generate new images. These models work by slowly adding "noise" to an image, and then learning how to reverse that process to generate new images.
The challenge is that diffusion models don't have a way to explicitly control the 3D shape or geometry of the objects in the generated images. This paper presents a solution to that problem. The key insight is to incorporate 3D information about the shapes of objects directly into the training of the diffusion model.
This allows the model to "understand" the 3D structure of objects, and then generate new images where the objects have specific 3D shapes that the user wants. For example, the model could generate images of chairs with particular seat heights or table tops with specific curvatures.
The authors test their approach on a few different datasets of 3D objects, and show that it outperforms previous diffusion models in terms of the ability to control the 3D geometry of the generated images. This could be very useful for applications like 3D modeling, product design, and virtual reality, where the precise 3D shape of objects is important.
Technical Explanation
The key technical contribution of this paper is a method to incorporate 3D shape information into diffusion models. Specifically, the authors propose a new diffusion model architecture that takes as input not just 2D images, but also 3D shape representations of the objects in those images.
The 3D shape information is encoded using a neural network that predicts a 3D voxel grid representation of the object. This 3D shape encoding is then combined with the 2D image features inside the diffusion model, allowing the model to learn the relationship between the 2D appearance and 3D structure of the objects.
During training, the model is optimized to not just generate realistic-looking images, but also to accurately predict the 3D shape of the objects in those images. This shape-aware training process enables the model to subsequently generate new images where the 3D geometry of the objects can be explicitly controlled.
The authors evaluate this approach on several datasets of 3D objects, including ShapeNet and Pix3D. They show that their 3D-aware diffusion model outperforms standard diffusion models in terms of metrics like 3D shape similarity, while still maintaining high-quality 2D image generation.
Critical Analysis
A key strength of this work is that it directly addresses an important limitation of standard diffusion models - their inability to control the 3D geometry of generated content. By incorporating 3D shape information into the model, the authors have demonstrated a clear path forward for making diffusion models more useful in applications that require precise 3D shape control.
However, one potential limitation is the computational cost and complexity introduced by the additional 3D shape encoding and prediction components. Incorporating 3D data into the model likely increases training time and model size, which could be a barrier to real-world deployment.
Additionally, the evaluation in this paper is focused on relatively simple 3D object datasets. It would be valuable to see how well the approach generalizes to more complex, real-world 3D scenes and geometries. The authors acknowledge this as an area for future work.
Another open question is how well this 3D shape control integrates with other desired attributes of the generated images, such as photorealism, semantic consistency, and coherence. Balancing these various objectives may require further innovations in diffusion model architectures and training procedures.
Conclusion
Overall, this paper presents a promising step forward in enhancing the capabilities of diffusion models. By giving these models the ability to explicitly control the 3D geometry of generated content, it opens up new avenues for applying them in domains like 3D modeling, product design, and virtual reality - areas where precise 3D shape is paramount.
While there are still some technical challenges to address, this work demonstrates the value of incorporating 3D information into generative models. As diffusion models continue to evolve, we can expect to see increasingly sophisticated ways of controlling the 3D properties of the content they generate.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
Morphable Diffusion: 3D-Consistent Diffusion for Single-image Avatar Creation
Xiyi Chen, Marko Mihajlovic, Shaofei Wang, Sergey Prokudin, Siyu Tang
0
0
Recent advances in generative diffusion models have enabled the previously unfeasible capability of generating 3D assets from a single input image or a text prompt. In this work, we aim to enhance the quality and functionality of these models for the task of creating controllable, photorealistic human avatars. We achieve this by integrating a 3D morphable model into the state-of-the-art multi-view-consistent diffusion approach. We demonstrate that accurate conditioning of a generative pipeline on the articulated 3D model enhances the baseline model performance on the task of novel view synthesis from a single image. More importantly, this integration facilitates a seamless and accurate incorporation of facial expression and body pose control into the generation process. To the best of our knowledge, our proposed framework is the first diffusion model to enable the creation of fully 3D-consistent, animatable, and photorealistic human avatars from a single image of an unseen subject; extensive quantitative and qualitative evaluations demonstrate the advantages of our approach over existing state-of-the-art avatar creation models on both novel view and novel expression synthesis tasks. The code for our project is publicly available.
4/3/2024
🖼️
GeoDiffuser: Geometry-Based Image Editing with Diffusion Models
Rahul Sajnani, Jeroen Vanbaar, Jie Min, Kapil Katyal, Srinath Sridhar
0
0
The success of image generative models has enabled us to build methods that can edit images based on text or other user input. However, these methods are bespoke, imprecise, require additional information, or are limited to only 2D image edits. We present GeoDiffuser, a zero-shot optimization-based method that unifies common 2D and 3D image-based object editing capabilities into a single method. Our key insight is to view image editing operations as geometric transformations. We show that these transformations can be directly incorporated into the attention layers in diffusion models to implicitly perform editing operations. Our training-free optimization method uses an objective function that seeks to preserve object style but generate plausible images, for instance with accurate lighting and shadows. It also inpaints disoccluded parts of the image where the object was originally located. Given a natural image and user input, we segment the foreground object using SAM and estimate a corresponding transform which is used by our optimization approach for editing. GeoDiffuser can perform common 2D and 3D edits like object translation, 3D rotation, and removal. We present quantitative results, including a perceptual study, that shows how our approach is better than existing methods. Visit https://ivl.cs.brown.edu/research/geodiffuser.html for more information.
4/23/2024
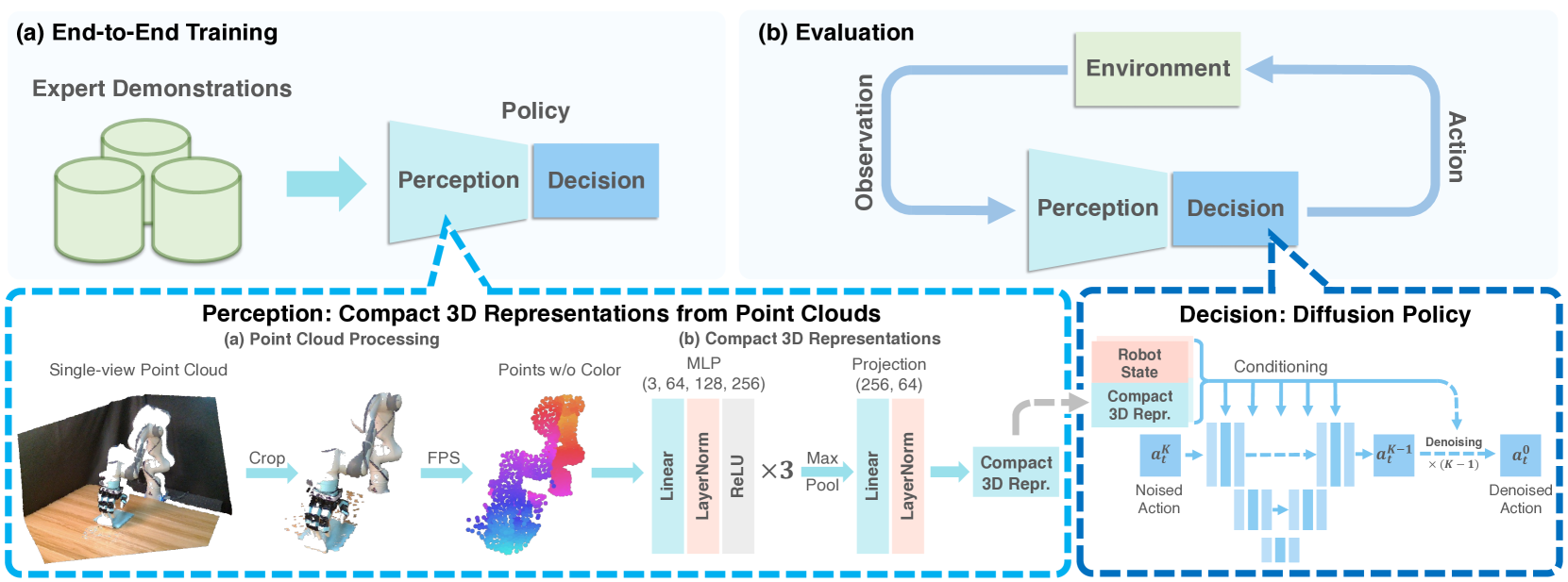
3D Diffusion Policy: Generalizable Visuomotor Policy Learning via Simple 3D Representations
Yanjie Ze, Gu Zhang, Kangning Zhang, Chenyuan Hu, Muhan Wang, Huazhe Xu
0
0
Imitation learning provides an efficient way to teach robots dexterous skills; however, learning complex skills robustly and generalizablely usually consumes large amounts of human demonstrations. To tackle this challenging problem, we present 3D Diffusion Policy (DP3), a novel visual imitation learning approach that incorporates the power of 3D visual representations into diffusion policies, a class of conditional action generative models. The core design of DP3 is the utilization of a compact 3D visual representation, extracted from sparse point clouds with an efficient point encoder. In our experiments involving 72 simulation tasks, DP3 successfully handles most tasks with just 10 demonstrations and surpasses baselines with a 24.2% relative improvement. In 4 real robot tasks, DP3 demonstrates precise control with a high success rate of 85%, given only 40 demonstrations of each task, and shows excellent generalization abilities in diverse aspects, including space, viewpoint, appearance, and instance. Interestingly, in real robot experiments, DP3 rarely violates safety requirements, in contrast to baseline methods which frequently do, necessitating human intervention. Our extensive evaluation highlights the critical importance of 3D representations in real-world robot learning. Videos, code, and data are available on https://3d-diffusion-policy.github.io .
5/29/2024
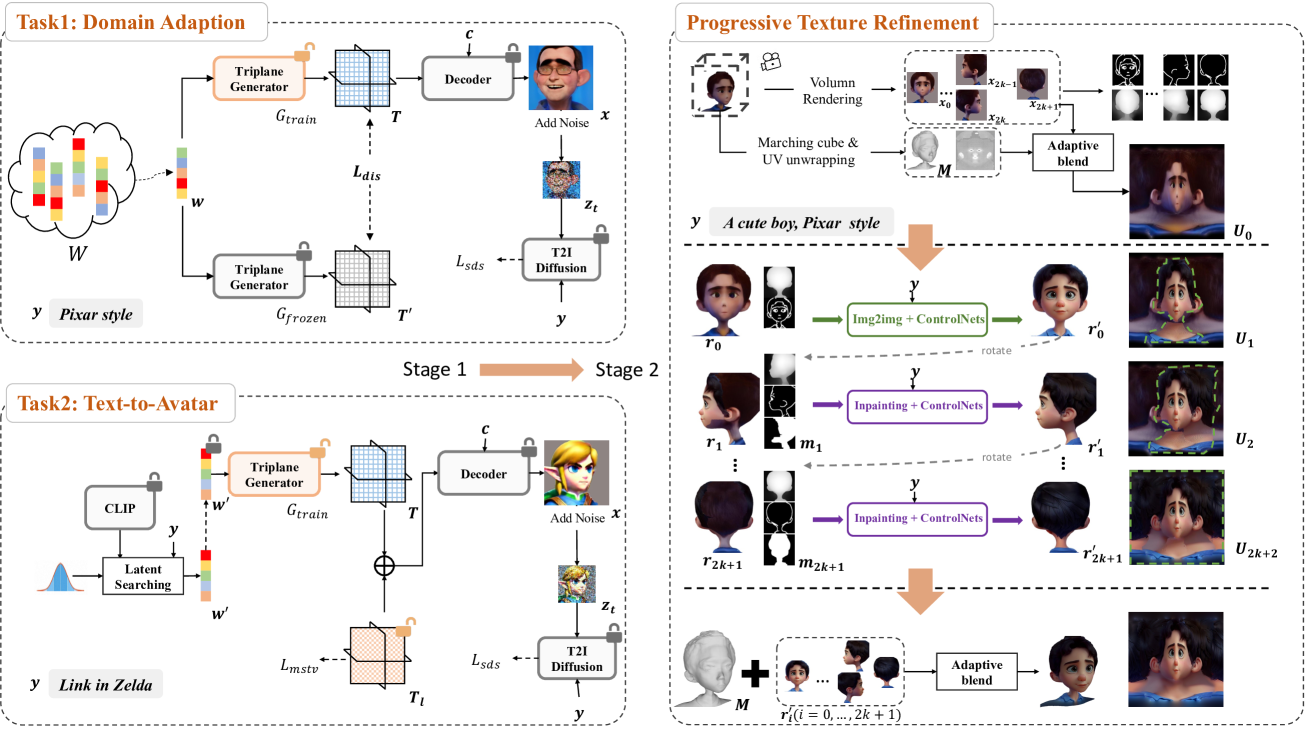
DiffusionGAN3D: Boosting Text-guided 3D Generation and Domain Adaptation by Combining 3D GANs and Diffusion Priors
Biwen Lei, Kai Yu, Mengyang Feng, Miaomiao Cui, Xuansong Xie
0
0
Text-guided domain adaptation and generation of 3D-aware portraits find many applications in various fields. However, due to the lack of training data and the challenges in handling the high variety of geometry and appearance, the existing methods for these tasks suffer from issues like inflexibility, instability, and low fidelity. In this paper, we propose a novel framework DiffusionGAN3D, which boosts text-guided 3D domain adaptation and generation by combining 3D GANs and diffusion priors. Specifically, we integrate the pre-trained 3D generative models (e.g., EG3D) and text-to-image diffusion models. The former provides a strong foundation for stable and high-quality avatar generation from text. And the diffusion models in turn offer powerful priors and guide the 3D generator finetuning with informative direction to achieve flexible and efficient text-guided domain adaptation. To enhance the diversity in domain adaptation and the generation capability in text-to-avatar, we introduce the relative distance loss and case-specific learnable triplane respectively. Besides, we design a progressive texture refinement module to improve the texture quality for both tasks above. Extensive experiments demonstrate that the proposed framework achieves excellent results in both domain adaptation and text-to-avatar tasks, outperforming existing methods in terms of generation quality and efficiency. The project homepage is at https://younglbw.github.io/DiffusionGAN3D-homepage/.
4/15/2024