Motion Inversion for Video Customization
2403.20193
0
0
Abstract
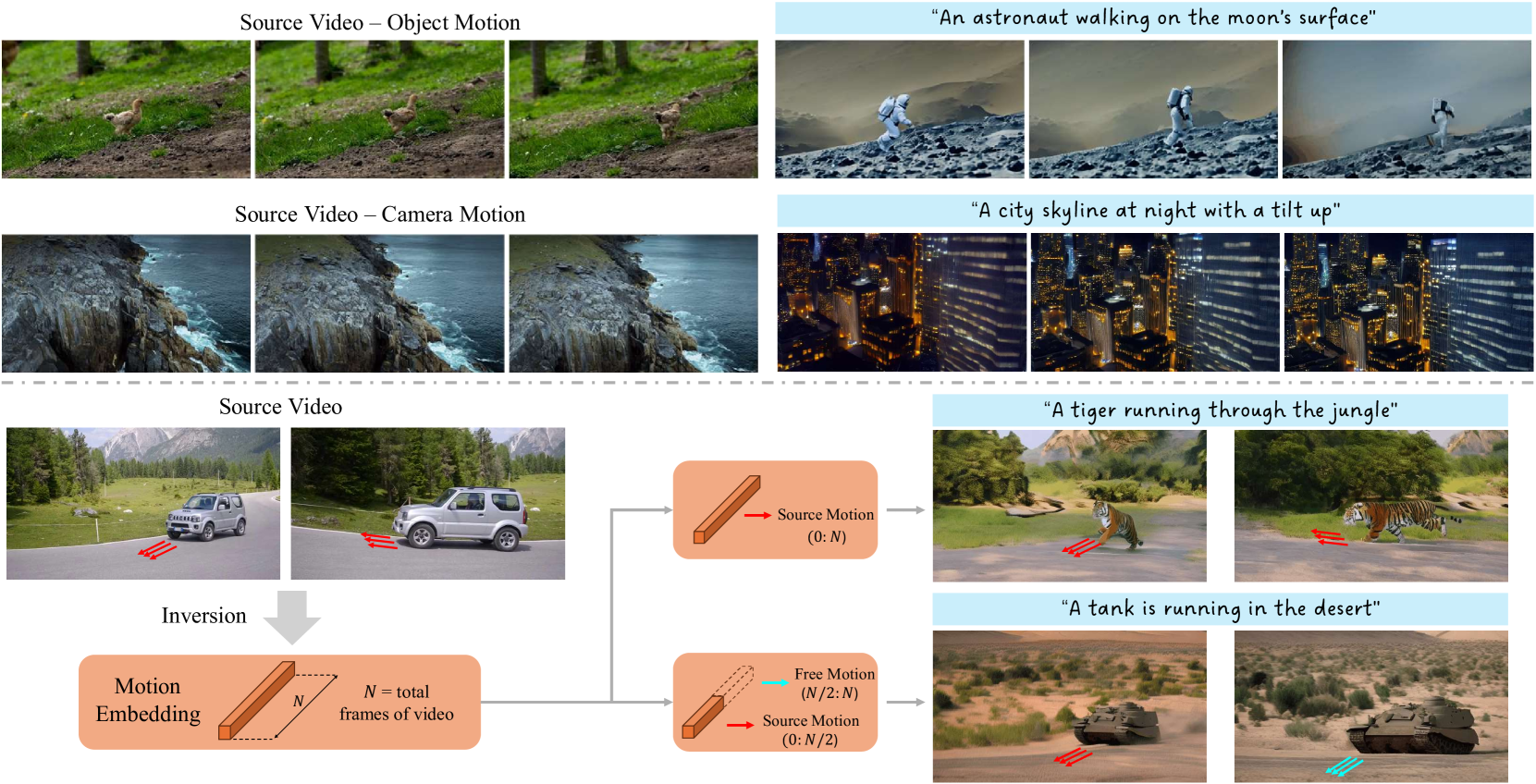
In this research, we present a novel approach to motion customization in video generation, addressing the widespread gap in the thorough exploration of motion representation within video generative models. Recognizing the unique challenges posed by video's spatiotemporal nature, our method introduces Motion Embeddings, a set of explicit, temporally coherent one-dimensional embeddings derived from a given video. These embeddings are designed to integrate seamlessly with the temporal transformer modules of video diffusion models, modulating self-attention computations across frames without compromising spatial integrity. Our approach offers a compact and efficient solution to motion representation and enables complex manipulations of motion characteristics through vector arithmetic in the embedding space. Furthermore, we identify the Temporal Discrepancy in video generative models, which refers to variations in how different motion modules process temporal relationships between frames. We leverage this understanding to optimize the integration of our motion embeddings. Our contributions include the introduction of a tailored motion embedding for customization tasks, insights into the temporal processing differences in video models, and a demonstration of the practical advantages and effectiveness of our method through extensive experiments.
Create account to get full access
Overview
- This paper presents a method for customizing the motion in videos using a diffusion-based generative model.
- The key idea is to "invert" the motion of a reference video and apply it to a target video, allowing for diverse motion customization.
- The authors demonstrate how this technique can be used to create compelling visual effects, such as changing the motion of a person in a video.
Plain English Explanation
The researchers have developed a new way to customize the motion in videos. The core concept is to take a reference video, analyze the motion in that video, and then apply that same motion to a different target video.
Imagine you have a video of someone dancing. You could use this method to take the dance moves from that video and apply them to a different person, essentially making that person dance the same way. Or you could take the motion from a video of a person walking and apply it to a car, making the car move like a person.
The key innovation is the use of a diffusion-based generative model. This is a type of artificial intelligence that can create new images or videos by learning from examples. In this case, the model learns the patterns of motion from the reference video and then applies that motion to the target video.
This approach allows for a wide range of creative possibilities. Users could take footage of professional dancers or athletes and apply their movements to amateur videos, instantly elevating the production value. Filmmakers could experiment with surreal visual effects by transferring motion between completely different subjects.
Overall, this work demonstrates a powerful new tool for video customization and visual effects, with applications in entertainment, art, and beyond.
Technical Explanation
The core of this approach is a diffusion-based generative model that can learn and invert the motion patterns in a video. The authors train this model on a large dataset of videos, allowing it to capture a diverse range of motion dynamics.
To customize a video, the user provides a reference video containing the desired motion, as well as a target video with the subject they want to apply that motion to. The model first extracts the motion information from the reference video through an "inversion" process. It then applies that motion to the target video, generating a new video with the customized motion.
Key innovations include:
- Motion Extraction: The model uses a self-supervised approach to learn representations of video motion that can be effectively inverted and applied to new footage.
- Motion Transfer: A novel "motion transfer" module allows the extracted motion to be seamlessly applied to the target video, preserving the visual fidelity of the original.
- Generalization: The diffusion-based architecture enables the model to generalize beyond the specific motion patterns seen during training, allowing for diverse customization possibilities.
The authors demonstrate the capabilities of their approach through a range of qualitative and quantitative experiments, showcasing compelling visual effects and the versatility of the technique.
Critical Analysis
The paper presents a promising new approach for video customization, with clear creative and technical merits. However, a few caveats are worth noting:
-
Artifact Mitigation: The authors acknowledge that their method can sometimes introduce visual artifacts, particularly when transferring motion between very different subjects. Further research is needed to improve the visual quality and seamlessness of the motion transfer.
-
Ethical Considerations: While the technology enables exciting new forms of artistic expression, there are also potential misuse cases, such as the creation of deceptive "deepfake" videos. The authors do not deeply address these ethical implications.
-
Dataset Limitations: The experiments are conducted on a relatively small and curated dataset of videos. It remains to be seen how well the approach will scale and generalize to more diverse, real-world video inputs.
-
User Experience: The paper focuses primarily on the technical aspects of the model, with limited discussion of the user experience and interface design considerations for video customization tools built upon this technology.
Overall, this work represents a significant advancement in video manipulation capabilities, opening up new creative possibilities. However, future research should also carefully consider the societal impact and responsible development of such technologies.
Conclusion
This paper introduces a novel diffusion-based approach for customizing the motion in videos. By extracting and inverting the motion patterns from a reference video, the model can seamlessly apply that motion to a target video, enabling a wide range of creative visual effects.
The technical innovations, including the motion extraction and transfer modules, demonstrate the power of generative models for video manipulation. While some limitations and ethical concerns remain, this work represents an important step forward in the field of video customization, with exciting implications for entertainment, art, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Diving Deep into the Motion Representation of Video-Text Models
Chinmaya Devaraj, Cornelia Fermuller, Yiannis Aloimonos
0
0
Videos are more informative than images because they capture the dynamics of the scene. By representing motion in videos, we can capture dynamic activities. In this work, we introduce GPT-4 generated motion descriptions that capture fine-grained motion descriptions of activities and apply them to three action datasets. We evaluated several video-text models on the task of retrieval of motion descriptions. We found that they fall far behind human expert performance on two action datasets, raising the question of whether video-text models understand motion in videos. To address it, we introduce a method of improving motion understanding in video-text models by utilizing motion descriptions. This method proves to be effective on two action datasets for the motion description retrieval task. The results draw attention to the need for quality captions involving fine-grained motion information in existing datasets and demonstrate the effectiveness of the proposed pipeline in understanding fine-grained motion during video-text retrieval.
6/10/2024
📈
ReVideo: Remake a Video with Motion and Content Control
Chong Mou, Mingdeng Cao, Xintao Wang, Zhaoyang Zhang, Ying Shan, Jian Zhang
0
0
Despite significant advancements in video generation and editing using diffusion models, achieving accurate and localized video editing remains a substantial challenge. Additionally, most existing video editing methods primarily focus on altering visual content, with limited research dedicated to motion editing. In this paper, we present a novel attempt to Remake a Video (ReVideo) which stands out from existing methods by allowing precise video editing in specific areas through the specification of both content and motion. Content editing is facilitated by modifying the first frame, while the trajectory-based motion control offers an intuitive user interaction experience. ReVideo addresses a new task involving the coupling and training imbalance between content and motion control. To tackle this, we develop a three-stage training strategy that progressively decouples these two aspects from coarse to fine. Furthermore, we propose a spatiotemporal adaptive fusion module to integrate content and motion control across various sampling steps and spatial locations. Extensive experiments demonstrate that our ReVideo has promising performance on several accurate video editing applications, i.e., (1) locally changing video content while keeping the motion constant, (2) keeping content unchanged and customizing new motion trajectories, (3) modifying both content and motion trajectories. Our method can also seamlessly extend these applications to multi-area editing without specific training, demonstrating its flexibility and robustness.
5/24/2024

New!MimicMotion: High-Quality Human Motion Video Generation with Confidence-aware Pose Guidance
Yuang Zhang, Jiaxi Gu, Li-Wen Wang, Han Wang, Junqi Cheng, Yuefeng Zhu, Fangyuan Zou
0
0
In recent years, generative artificial intelligence has achieved significant advancements in the field of image generation, spawning a variety of applications. However, video generation still faces considerable challenges in various aspects, such as controllability, video length, and richness of details, which hinder the application and popularization of this technology. In this work, we propose a controllable video generation framework, dubbed MimicMotion, which can generate high-quality videos of arbitrary length mimicking specific motion guidance. Compared with previous methods, our approach has several highlights. Firstly, we introduce confidence-aware pose guidance that ensures high frame quality and temporal smoothness. Secondly, we introduce regional loss amplification based on pose confidence, which significantly reduces image distortion. Lastly, for generating long and smooth videos, we propose a progressive latent fusion strategy. By this means, we can produce videos of arbitrary length with acceptable resource consumption. With extensive experiments and user studies, MimicMotion demonstrates significant improvements over previous approaches in various aspects. Detailed results and comparisons are available on our project page: https://tencent.github.io/MimicMotion .
7/1/2024
🏋️
Video Diffusion Models are Training-free Motion Interpreter and Controller
Zeqi Xiao, Yifan Zhou, Shuai Yang, Xingang Pan
0
0
Video generation primarily aims to model authentic and customized motion across frames, making understanding and controlling the motion a crucial topic. Most diffusion-based studies on video motion focus on motion customization with training-based paradigms, which, however, demands substantial training resources and necessitates retraining for diverse models. Crucially, these approaches do not explore how video diffusion models encode cross-frame motion information in their features, lacking interpretability and transparency in their effectiveness. To answer this question, this paper introduces a novel perspective to understand, localize, and manipulate motion-aware features in video diffusion models. Through analysis using Principal Component Analysis (PCA), our work discloses that robust motion-aware feature already exists in video diffusion models. We present a new MOtion FeaTure (MOFT) by eliminating content correlation information and filtering motion channels. MOFT provides a distinct set of benefits, including the ability to encode comprehensive motion information with clear interpretability, extraction without the need for training, and generalizability across diverse architectures. Leveraging MOFT, we propose a novel training-free video motion control framework. Our method demonstrates competitive performance in generating natural and faithful motion, providing architecture-agnostic insights and applicability in a variety of downstream tasks.
5/24/2024