Video Diffusion Models are Training-free Motion Interpreter and Controller
2405.14864
0
0
🏋️
Abstract
Video generation primarily aims to model authentic and customized motion across frames, making understanding and controlling the motion a crucial topic. Most diffusion-based studies on video motion focus on motion customization with training-based paradigms, which, however, demands substantial training resources and necessitates retraining for diverse models. Crucially, these approaches do not explore how video diffusion models encode cross-frame motion information in their features, lacking interpretability and transparency in their effectiveness. To answer this question, this paper introduces a novel perspective to understand, localize, and manipulate motion-aware features in video diffusion models. Through analysis using Principal Component Analysis (PCA), our work discloses that robust motion-aware feature already exists in video diffusion models. We present a new MOtion FeaTure (MOFT) by eliminating content correlation information and filtering motion channels. MOFT provides a distinct set of benefits, including the ability to encode comprehensive motion information with clear interpretability, extraction without the need for training, and generalizability across diverse architectures. Leveraging MOFT, we propose a novel training-free video motion control framework. Our method demonstrates competitive performance in generating natural and faithful motion, providing architecture-agnostic insights and applicability in a variety of downstream tasks.
Create account to get full access
Overview
- Video generation aims to model authentic and customized motion across frames
- Understanding and controlling motion is a crucial topic in this field
- Most diffusion-based studies on video motion focus on motion customization with training-based approaches
- These approaches require substantial training resources and necessitate retraining for diverse models
- They also lack interpretability and transparency in how video diffusion models encode cross-frame motion information
Plain English Explanation
Creating realistic and customized videos is an important goal in the field of video generation. Being able to understand and control the motion of objects and characters in a video is a key part of this challenge. Most recent studies using diffusion models, a type of machine learning technique, have focused on customizing the motion in videos during the training process. However, these training-based approaches require a lot of computing power and need to be retrained from scratch if you want to apply them to different types of videos.
Crucially, these existing methods don't really explain how the diffusion models are able to capture and represent the motion information in the videos they're trained on. This makes it hard to understand why they work the way they do and how they could be improved.
To address this, the paper introduces a new way to understand, locate, and manipulate the motion-related features learned by video diffusion models. By analyzing the models using a technique called Principal Component Analysis, the researchers were able to identify a distinct set of "motion-aware" features that encode the cross-frame motion information. This MOFT (MOtion FeaTure) can be extracted without any additional training, and works across different diffusion model architectures.
Technical Explanation
The paper takes a novel analytical approach to understand how video diffusion models represent and encode motion information in their internal features. Through Principal Component Analysis (PCA), the researchers identify a distinct set of "motion-aware" features that capture the cross-frame motion patterns, separate from the content-related features.
This new MOtion FeaTure (MOFT) can be extracted without any additional training, and is shown to be generalizable across different diffusion model architectures. By isolating and manipulating the MOFT, the authors demonstrate a training-free video motion control framework that can generate natural and faithful motion, outperforming prior training-based approaches.
The insights from this analysis provide a new interpretable and transparent perspective on how video diffusion models work, going beyond the "black box" nature of many deep learning techniques. This lays the groundwork for more principled ways to control and edit video motion using diffusion models, with potential applications in areas like motion style transfer and general-purpose video generation.
Critical Analysis
The paper provides a valuable new perspective on understanding the inner workings of video diffusion models, but there are a few potential limitations and areas for further research:
- The analysis is focused on a specific set of diffusion models and architectures - it's not clear how generalizable the MOFT concept would be to radically different model designs.
- The experiments demonstrate the usefulness of MOFT for motion control, but don't fully explore its potential applications in other video generation tasks.
- While the training-free nature of the motion control framework is a strength, it may have limitations compared to more sophisticated training-based approaches in terms of the range and quality of motions it can produce.
Overall, this paper takes an important step towards making video diffusion models more interpretable and controllable. Further research could explore how these insights can be extended and applied more broadly across different video generation domains and architectures.
Conclusion
This paper introduces a novel analytical approach to understanding how video diffusion models encode and represent motion information in their internal features. By identifying a distinct "motion-aware" feature set (MOFT) through Principal Component Analysis, the researchers provide a new interpretable and transparent perspective on these models.
Leveraging MOFT, the authors demonstrate a training-free video motion control framework that generates natural and faithful motion, outperforming prior training-based methods. These insights lay the groundwork for more principled ways to control and edit video motion using diffusion models, with potential applications in areas like motion style transfer and general-purpose video generation.
Overall, this work represents an important step towards making video diffusion models more understandable and customizable, which could have significant implications for the field of video generation and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
MotionMaster: Training-free Camera Motion Transfer For Video Generation
Teng Hu, Jiangning Zhang, Ran Yi, Yating Wang, Hongrui Huang, Jieyu Weng, Yabiao Wang, Lizhuang Ma
0
0
The emergence of diffusion models has greatly propelled the progress in image and video generation. Recently, some efforts have been made in controllable video generation, including text-to-video generation and video motion control, among which camera motion control is an important topic. However, existing camera motion control methods rely on training a temporal camera module, and necessitate substantial computation resources due to the large amount of parameters in video generation models. Moreover, existing methods pre-define camera motion types during training, which limits their flexibility in camera control. Therefore, to reduce training costs and achieve flexible camera control, we propose COMD, a novel training-free video motion transfer model, which disentangles camera motions and object motions in source videos and transfers the extracted camera motions to new videos. We first propose a one-shot camera motion disentanglement method to extract camera motion from a single source video, which separates the moving objects from the background and estimates the camera motion in the moving objects region based on the motion in the background by solving a Poisson equation. Furthermore, we propose a few-shot camera motion disentanglement method to extract the common camera motion from multiple videos with similar camera motions, which employs a window-based clustering technique to extract the common features in temporal attention maps of multiple videos. Finally, we propose a motion combination method to combine different types of camera motions together, enabling our model a more controllable and flexible camera control. Extensive experiments demonstrate that our training-free approach can effectively decouple camera-object motion and apply the decoupled camera motion to a wide range of controllable video generation tasks, achieving flexible and diverse camera motion control.
5/2/2024

ZeroSmooth: Training-free Diffuser Adaptation for High Frame Rate Video Generation
Shaoshu Yang, Yong Zhang, Xiaodong Cun, Ying Shan, Ran He
0
0
Video generation has made remarkable progress in recent years, especially since the advent of the video diffusion models. Many video generation models can produce plausible synthetic videos, e.g., Stable Video Diffusion (SVD). However, most video models can only generate low frame rate videos due to the limited GPU memory as well as the difficulty of modeling a large set of frames. The training videos are always uniformly sampled at a specified interval for temporal compression. Previous methods promote the frame rate by either training a video interpolation model in pixel space as a postprocessing stage or training an interpolation model in latent space for a specific base video model. In this paper, we propose a training-free video interpolation method for generative video diffusion models, which is generalizable to different models in a plug-and-play manner. We investigate the non-linearity in the feature space of video diffusion models and transform a video model into a self-cascaded video diffusion model with incorporating the designed hidden state correction modules. The self-cascaded architecture and the correction module are proposed to retain the temporal consistency between key frames and the interpolated frames. Extensive evaluations are preformed on multiple popular video models to demonstrate the effectiveness of the propose method, especially that our training-free method is even comparable to trained interpolation models supported by huge compute resources and large-scale datasets.
6/4/2024
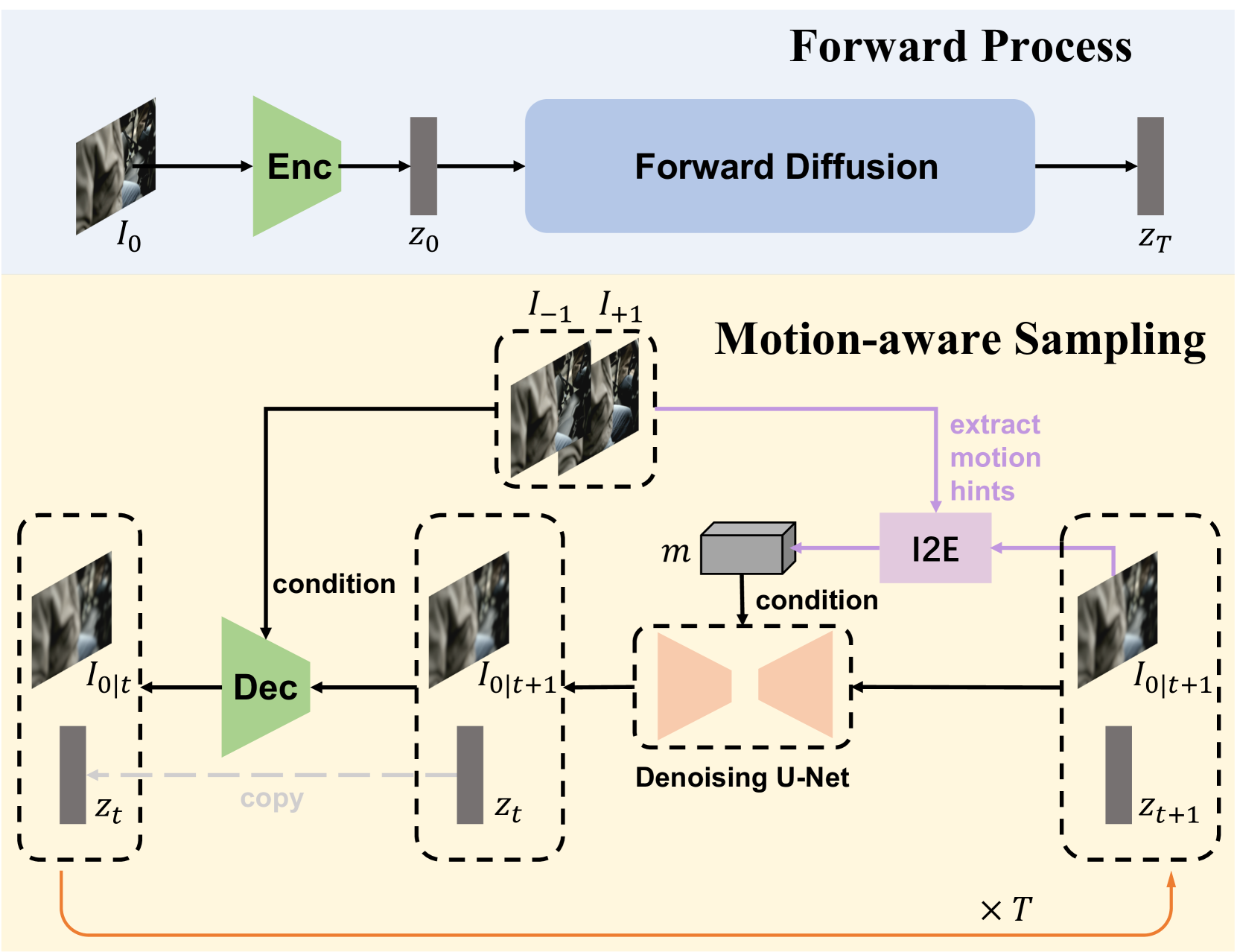
Motion-aware Latent Diffusion Models for Video Frame Interpolation
Zhilin Huang, Yijie Yu, Ling Yang, Chujun Qin, Bing Zheng, Xiawu Zheng, Zikun Zhou, Yaowei Wang, Wenming Yang
0
0
With the advancement of AIGC, video frame interpolation (VFI) has become a crucial component in existing video generation frameworks, attracting widespread research interest. For the VFI task, the motion estimation between neighboring frames plays a crucial role in avoiding motion ambiguity. However, existing VFI methods always struggle to accurately predict the motion information between consecutive frames, and this imprecise estimation leads to blurred and visually incoherent interpolated frames. In this paper, we propose a novel diffusion framework, motion-aware latent diffusion models (MADiff), which is specifically designed for the VFI task. By incorporating motion priors between the conditional neighboring frames with the target interpolated frame predicted throughout the diffusion sampling procedure, MADiff progressively refines the intermediate outcomes, culminating in generating both visually smooth and realistic results. Extensive experiments conducted on benchmark datasets demonstrate that our method achieves state-of-the-art performance significantly outperforming existing approaches, especially under challenging scenarios involving dynamic textures with complex motion.
6/5/2024

FreeTraj: Tuning-Free Trajectory Control in Video Diffusion Models
Haonan Qiu, Zhaoxi Chen, Zhouxia Wang, Yingqing He, Menghan Xia, Ziwei Liu
0
0
Diffusion model has demonstrated remarkable capability in video generation, which further sparks interest in introducing trajectory control into the generation process. While existing works mainly focus on training-based methods (e.g., conditional adapter), we argue that diffusion model itself allows decent control over the generated content without requiring any training. In this study, we introduce a tuning-free framework to achieve trajectory-controllable video generation, by imposing guidance on both noise construction and attention computation. Specifically, 1) we first show several instructive phenomenons and analyze how initial noises influence the motion trajectory of generated content. 2) Subsequently, we propose FreeTraj, a tuning-free approach that enables trajectory control by modifying noise sampling and attention mechanisms. 3) Furthermore, we extend FreeTraj to facilitate longer and larger video generation with controllable trajectories. Equipped with these designs, users have the flexibility to provide trajectories manually or opt for trajectories automatically generated by the LLM trajectory planner. Extensive experiments validate the efficacy of our approach in enhancing the trajectory controllability of video diffusion models.
6/26/2024