MPC-Minimized Secure LLM Inference

0
Sign in to get full access
Overview
- This paper presents a method for performing secure inference on large language models (LLMs) while minimizing the use of multi-party computation (MPC).
- The proposed approach aims to strike a balance between security and efficiency, reducing the computational overhead associated with MPC-based secure inference.
Plain English Explanation
The paper describes a technique for running secure inference on large language models, such as those used in chatbots and other AI assistants, in a more efficient way.
The key idea is to minimize the amount of multi-party computation (MPC) required during the inference process. MPC is a technique that allows multiple parties to jointly compute a function without revealing their individual inputs. While MPC is important for preserving privacy and security, it can also add significant computational overhead.
The researchers propose a method that carefully manages the use of MPC, only applying it to the most sensitive parts of the inference process. This helps to maintain a high level of security while reducing the overall computational cost and latency. The goal is to make secure inference on large language models more practical and efficient, which could enable wider adoption of these powerful AI technologies while preserving user privacy.
Technical Explanation
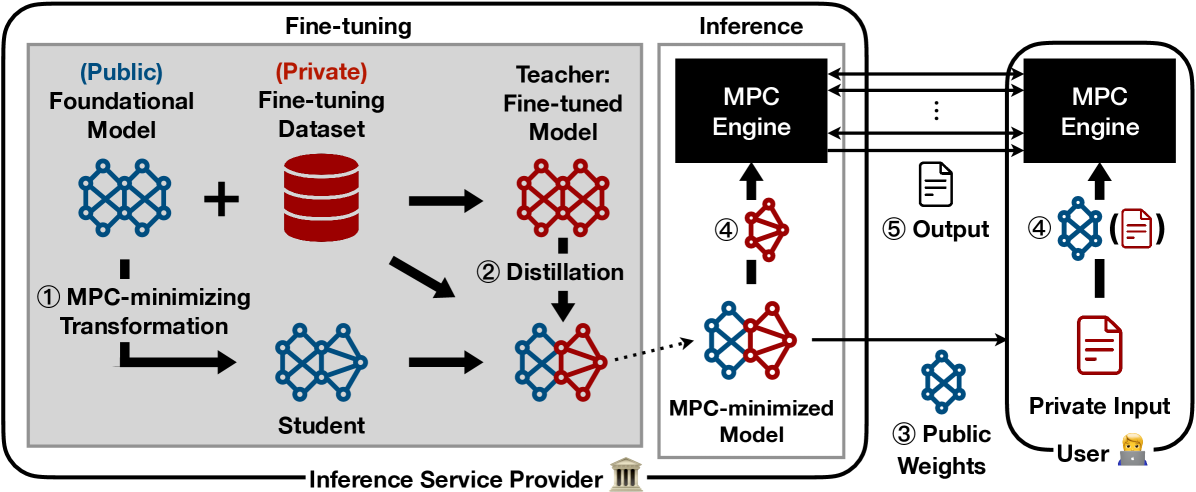
The paper presents a secure LLM inference framework that aims to minimize the use of multi-party computation (MPC). The approach involves:
-
Partitioning the LLM: The researchers divide the LLM into a public part and a private part. The public part can be executed without MPC, while the private part requires MPC-based secure computation.
-
Efficient MPC Protocols: The authors design specialized MPC protocols tailored to the specific operations in the private part of the LLM, reducing the overall MPC overhead.
-
Input Obfuscation: The framework includes an input obfuscation step, which further enhances the security of the system by hiding sensitive information from the model.
-
Secure Inference Pipeline: The paper outlines a secure inference pipeline that integrates the partitioned model, efficient MPC protocols, and input obfuscation to enable secure LLM inference with reduced computational costs.
The authors evaluate their approach on various LLM architectures and demonstrate significant reductions in MPC overhead compared to naïve MPC-based secure inference, while maintaining a high level of security and privacy.
Critical Analysis
The paper presents a well-designed approach to addressing the challenge of secure inference on large language models. The key strength of the proposed framework is its ability to strike a balance between security and efficiency by minimizing the use of MPC.
However, the paper does not fully address the potential limitations and practical challenges of the approach. For example, it is unclear how the partitioning of the LLM into public and private parts would affect the model's overall performance and accuracy. Additionally, the paper does not discuss the scalability of the approach as the size and complexity of the LLMs continue to grow.
Furthermore, the paper could have explored potential attacks or adversarial scenarios that the proposed framework might face, as well as any countermeasures that could be developed to mitigate such threats.
Conclusion
The paper presents a promising approach to enabling secure inference on large language models by minimizing the use of computationally expensive multi-party computation. This could significantly improve the practicality and efficiency of deploying powerful AI models in sensitive or privacy-conscious applications, such as medical diagnosis, financial planning, or personal assistants.
While the paper provides a solid technical foundation, further research is needed to address the potential limitations and practical challenges, as well as to explore the broader implications and societal impacts of this technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MPC-Minimized Secure LLM Inference
Deevashwer Rathee, Dacheng Li, Ion Stoica, Hao Zhang, Raluca Popa
Many inference services based on large language models (LLMs) pose a privacy concern, either revealing user prompts to the service or the proprietary weights to the user. Secure inference offers a solution to this problem through secure multi-party computation (MPC), however, it is still impractical for modern LLM workload due to the large overhead imposed by MPC. To address this overhead, we propose Marill, a framework that adapts LLM fine-tuning to minimize MPC usage during secure inference. Marill introduces high-level architectural changes during fine-tuning that significantly reduce the number of expensive operations needed within MPC during inference, by removing some and relocating others outside MPC without compromising security. As a result, Marill-generated models are more efficient across all secure inference protocols and our approach complements MPC-friendly approximations for such operations. Compared to standard fine-tuning, Marill results in 3.6-11.3x better runtime and 2.4-6.9x better communication during secure inference across various MPC settings, while typically preserving over 90% performance across downstream tasks.
Read more8/9/2024

0
Low-Latency Privacy-Preserving Deep Learning Design via Secure MPC
Ke Lin, Yasir Glani, Ping Luo
Secure multi-party computation (MPC) facilitates privacy-preserving computation between multiple parties without leaking private information. While most secure deep learning techniques utilize MPC operations to achieve feasible privacy-preserving machine learning on downstream tasks, the overhead of the computation and communication still hampers their practical application. This work proposes a low-latency secret-sharing-based MPC design that reduces unnecessary communication rounds during the execution of MPC protocols. We also present a method for improving the computation of commonly used nonlinear functions in deep learning by integrating multivariate multiplication and coalescing different packets into one to maximize network utilization. Our experimental results indicate that our method is effective in a variety of settings, with a speedup in communication latency of $10sim20%$.
Read more7/30/2024
0
Fast and Private Inference of Deep Neural Networks by Co-designing Activation Functions
Abdulrahman Diaa, Lucas Fenaux, Thomas Humphries, Marian Dietz, Faezeh Ebrahimianghazani, Bailey Kacsmar, Xinda Li, Nils Lukas, Rasoul Akhavan Mahdavi, Simon Oya, Ehsan Amjadian, Florian Kerschbaum
Machine Learning as a Service (MLaaS) is an increasingly popular design where a company with abundant computing resources trains a deep neural network and offers query access for tasks like image classification. The challenge with this design is that MLaaS requires the client to reveal their potentially sensitive queries to the company hosting the model. Multi-party computation (MPC) protects the client's data by allowing encrypted inferences. However, current approaches suffer from prohibitively large inference times. The inference time bottleneck in MPC is the evaluation of non-linear layers such as ReLU activation functions. Motivated by the success of previous work co-designing machine learning and MPC, we develop an activation function co-design. We replace all ReLUs with a polynomial approximation and evaluate them with single-round MPC protocols, which give state-of-the-art inference times in wide-area networks. Furthermore, to address the accuracy issues previously encountered with polynomial activations, we propose a novel training algorithm that gives accuracy competitive with plaintext models. Our evaluation shows between $3$ and $110times$ speedups in inference time on large models with up to $23$ million parameters while maintaining competitive inference accuracy.
Read more4/17/2024
🤯
0
MPC-Pipe: an Efficient Pipeline Scheme for Secure Multi-party Machine Learning Inference
Yongqin Wang, Rachit Rajat, Murali Annavaram
Multi-party computing (MPC) has been gaining popularity as a secure computing model over the past few years. However, prior works have demonstrated that MPC protocols still pay substantial performance penalties compared to plaintext, particularly when applied to ML algorithms. The overhead is due to added computation and communication costs. Prior studies, as well as our own analysis, found that most MPC protocols today sequentially perform communication and computation. The participating parties must compute on their shares first and then perform data communication to allow the distribution of new secret shares before proceeding to the next computation step. In this work, we show that serialization is unnecessary, particularly in the context of ML computations (both in Convolutional neural networks and in Transformer-based models). We demonstrate that it is possible to carefully orchestrate the computation and communication steps to overlap. We propose MPC-Pipe, an efficient MPC system for both training and inference of ML workloads, which pipelines computations and communications in an MPC protocol during the online phase. MPC-Pipe proposes three pipeline schemes to optimize the online phase of ML in the semi-honest majority adversary setting. We implement MPC-Pipe by augmenting a modified version of CrypTen, which separates online and offline phases. We evaluate the end-to-end system performance benefits of the online phase of MPC using deep neural networks (VGG16, ResNet50) and Transformers using different network settings. We show that MPC-Pipe can improve the throughput and latency of ML workloads.
Read more8/28/2024