MPT-PAR:Mix-Parameters Transformer for Panoramic Activity Recognition

0

Sign in to get full access
Overview
- The paper proposes MPT-PAR, a novel Mix-Parameters Transformer model for panoramic activity recognition.
- It aims to capture global and local spatial-temporal information to improve group activity understanding.
- The model utilizes a mix of global and local parameters to learn more robust and discriminative representations.
Plain English Explanation
The researchers developed a new deep learning model called MPT-PAR to better recognize human activities happening in wide, panoramic video scenes. Typical activity recognition models focus on a single person or small group, but this paper tackles the more challenging problem of understanding the collective activities of larger groups within a broad field of view.
The key innovation of MPT-PAR is the use of a "Mix-Parameters Transformer" architecture. This allows the model to learn a blend of global information about the entire scene as well as more localized details about specific groups or individuals. By capturing both coarse and fine-grained spatial-temporal patterns, the model can build a more comprehensive understanding of the complex group activities taking place.
Technical Explanation
The MPT-PAR model is built upon the Transformer architecture, which has shown strong performance on a variety of visual understanding tasks. The core innovation is the use of "mix parameters" - the model learns a set of global parameters to capture the overall scene context, as well as a set of local parameters to focus on details within sub-regions of the panoramic view.
This mix of global and local representations is fed into the Transformer layers, allowing the model to reason about both the high-level group activities and the lower-level individual actions and interactions. The authors demonstrate the effectiveness of this approach through experiments on challenging panoramic activity recognition benchmarks, where MPT-PAR outperforms previous state-of-the-art methods.
Critical Analysis
The paper provides a thorough evaluation of MPT-PAR, including comparisons to other leading panoramic activity recognition models. While the results are impressive, the authors acknowledge that the model still has room for improvement, particularly in handling complex, crowded scenes with many overlapping activities.
Additionally, the reliance on RGB video data means the model may struggle in scenarios with poor lighting or occlusions. Exploring the integration of additional modalities, such as depth or pose information, could further boost the model's robustness and generalization capabilities.
Overall, the MPT-PAR approach represents an important step forward in group activity understanding, with the mix-parameters Transformer architecture serving as a promising direction for future research in this domain.
Conclusion
This paper introduces MPT-PAR, a novel deep learning model for panoramic activity recognition. By leveraging a mix of global and local parameters within a Transformer-based architecture, the model is able to capture both high-level scene context and fine-grained details, leading to improved performance on challenging group activity recognition benchmarks.
The researchers have made a significant contribution to the field of human activity understanding, particularly in the area of collective, wide-angle activity recognition. The insights and techniques presented in this work could inspire further advancements in this important area of computer vision and AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MPT-PAR:Mix-Parameters Transformer for Panoramic Activity Recognition
Wenqing Gan, Yan Sun, Feiran Liu, Xiangfeng Luo
The objective of the panoramic activity recognition task is to identify behaviors at various granularities within crowded and complex environments, encompassing individual actions, social group activities, and global activities. Existing methods generally use either parameter-independent modules to capture task-specific features or parameter-sharing modules to obtain common features across all tasks. However, there is often a strong interrelatedness and complementary effect between tasks of different granularities that previous methods have yet to notice. In this paper, we propose a model called MPT-PAR that considers both the unique characteristics of each task and the synergies between different tasks simultaneously, thereby maximizing the utilization of features across multi-granularity activity recognition. Furthermore, we emphasize the significance of temporal and spatial information by introducing a spatio-temporal relation-enhanced module and a scene representation learning module, which integrate the the spatio-temporal context of action and global scene into the feature map of each granularity. Our method achieved an overall F1 score of 47.5% on the JRDB-PAR dataset, significantly outperforming all the state-of-the-art methods.
Read more8/2/2024
👁️
0
AdaFPP: Adapt-Focused Bi-Propagating Prototype Learning for Panoramic Activity Recognition
Meiqi Cao, Rui Yan, Xiangbo Shu, Guangzhao Dai, Yazhou Yao, Guo-Sen Xie
Panoramic Activity Recognition (PAR) aims to identify multi-granularity behaviors performed by multiple persons in panoramic scenes, including individual activities, group activities, and global activities. Previous methods 1) heavily rely on manually annotated detection boxes in training and inference, hindering further practical deployment; or 2) directly employ normal detectors to detect multiple persons with varying size and spatial occlusion in panoramic scenes, blocking the performance gain of PAR. To this end, we consider learning a detector adapting varying-size occluded persons, which is optimized along with the recognition module in the all-in-one framework. Therefore, we propose a novel Adapt-Focused bi-Propagating Prototype learning (AdaFPP) framework to jointly recognize individual, group, and global activities in panoramic activity scenes by learning an adapt-focused detector and multi-granularity prototypes as the pretext tasks in an end-to-end way. Specifically, to accommodate the varying sizes and spatial occlusion of multiple persons in crowed panoramic scenes, we introduce a panoramic adapt-focuser, achieving the size-adapting detection of individuals by comprehensively selecting and performing fine-grained detections on object-dense sub-regions identified through original detections. In addition, to mitigate information loss due to inaccurate individual localizations, we introduce a bi-propagation prototyper that promotes closed-loop interaction and informative consistency across different granularities by facilitating bidirectional information propagation among the individual, group, and global levels. Extensive experiments demonstrate the significant performance of AdaFPP and emphasize its powerful applicability for PAR.
Read more5/7/2024
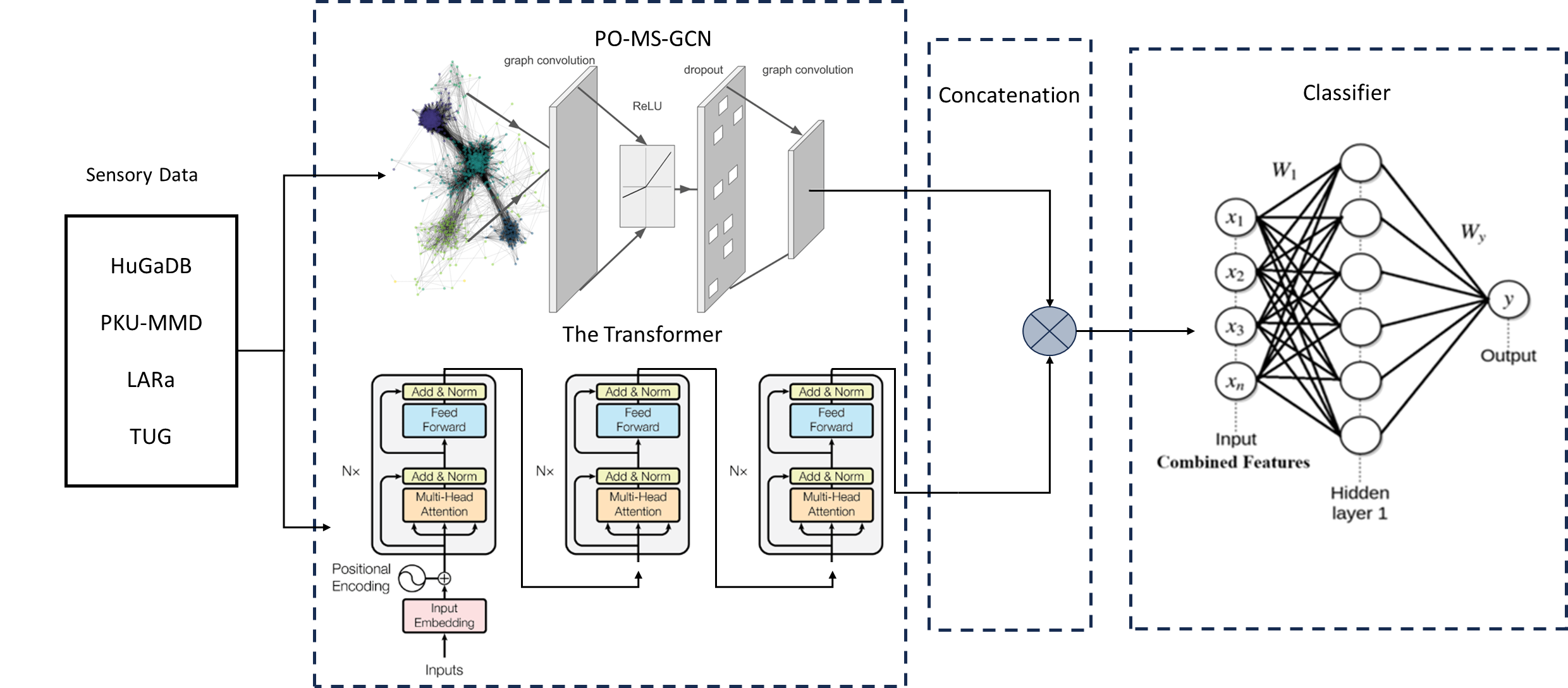
0
Feature Fusion for Human Activity Recognition using Parameter-Optimized Multi-Stage Graph Convolutional Network and Transformer Models
Mohammad Belal (Khalifa University of Science and Technology, Abu Dhabi, United Arab Emirates), Taimur Hassan (Abu Dhabi University, Abu Dhabi, United Arab Emirates), Abdelfatah Ahmed (Khalifa University of Science and Technology, Abu Dhabi, United Arab Emirates), Ahmad Aljarah (Khalifa University of Science and Technology, Abu Dhabi, United Arab Emirates), Nael Alsheikh (Khalifa University of Science and Technology, Abu Dhabi, United Arab Emirates), Irfan Hussain (Khalifa University of Science and Technology, Abu Dhabi, United Arab Emirates)
Human activity recognition (HAR) is a crucial area of research that involves understanding human movements using computer and machine vision technology. Deep learning has emerged as a powerful tool for this task, with models such as Convolutional Neural Networks (CNNs) and Transformers being employed to capture various aspects of human motion. One of the key contributions of this work is the demonstration of the effectiveness of feature fusion in improving HAR accuracy by capturing spatial and temporal features, which has important implications for the development of more accurate and robust activity recognition systems. The study uses sensory data from HuGaDB, PKU-MMD, LARa, and TUG datasets. Two model, the PO-MS-GCN and a Transformer were trained and evaluated, with PO-MS-GCN outperforming state-of-the-art models. HuGaDB and TUG achieved high accuracies and f1-scores, while LARa and PKU-MMD had lower scores. Feature fusion improved results across datasets.
Read more6/26/2024

0
Skeleton-based Group Activity Recognition via Spatial-Temporal Panoramic Graph
Zhengcen Li, Xinle Chang, Yueran Li, Jingyong Su
Group Activity Recognition aims to understand collective activities from videos. Existing solutions primarily rely on the RGB modality, which encounters challenges such as background variations, occlusions, motion blurs, and significant computational overhead. Meanwhile, current keypoint-based methods offer a lightweight and informative representation of human motions but necessitate accurate individual annotations and specialized interaction reasoning modules. To address these limitations, we design a panoramic graph that incorporates multi-person skeletons and objects to encapsulate group activity, offering an effective alternative to RGB video. This panoramic graph enables Graph Convolutional Network (GCN) to unify intra-person, inter-person, and person-object interactive modeling through spatial-temporal graph convolutions. In practice, we develop a novel pipeline that extracts skeleton coordinates using pose estimation and tracking algorithms and employ Multi-person Panoramic GCN (MP-GCN) to predict group activities. Extensive experiments on Volleyball and NBA datasets demonstrate that the MP-GCN achieves state-of-the-art performance in both accuracy and efficiency. Notably, our method outperforms RGB-based approaches by using only estimated 2D keypoints as input. Code is available at https://github.com/mgiant/MP-GCN
Read more7/30/2024