MS2SL: Multimodal Spoken Data-Driven Continuous Sign Language Production

0
Sign in to get full access
Overview
• This paper introduces MS2SL, a novel system for generating continuous sign language from spoken language input using multimodal data.
• The key innovations include the use of large language models and diffusion models to produce high-quality, natural sign language from speech.
• The system addresses challenges in prior work, such as Sign-Stitching and Neural Sign Actors, to enable more fluid and expressive sign language production.
Plain English Explanation
The paper presents a new system called MS2SL that can automatically generate continuous sign language from spoken language input. This is a challenging task because sign language has its own complex grammar and structure that differs significantly from spoken languages.
MS2SL leverages large language models, which are AI systems trained on vast amounts of text data, to better understand the relationship between speech and sign language. It also uses diffusion models, a type of generative AI, to produce fluid and natural-looking sign language animations.
This approach aims to address limitations in previous work, like Sign-Stitching and Neural Sign Actors, which struggled to generate continuous, expressive sign language. The goal is to make it easier for deaf and hard-of-hearing individuals to access spoken content through more natural and accessible sign language translations.
Technical Explanation
The MS2SL system takes spoken language input and generates corresponding sign language output. It consists of several key components:
- Speech Encoder: This module processes the spoken input and extracts relevant features.
- Sign Language Generator: A diffusion model is used to generate realistic, continuous sign language animations from the speech features.
- Sign Language Refiner: An additional model is used to further refine and improve the generated sign language, ensuring it is expressive and natural-looking.
The system is trained on a large, multimodal dataset containing aligned speech and sign language data. This allows the AI models to learn the complex relationships between the two modalities.
Compared to prior work like Sign-Stitching and Neural Sign Actors, the use of large language models and diffusion models enables MS2SL to generate more fluid, continuous, and expressive sign language that better matches the original speech.
Critical Analysis
The paper provides a comprehensive evaluation of the MS2SL system, demonstrating significant improvements over baseline methods. However, some potential limitations and areas for future research are worth noting:
- Generalization: While the system shows strong performance on the evaluated datasets, its ability to generalize to diverse real-world scenarios, accents, and sign language styles remains to be tested.
- Computational Efficiency: The use of large language models and diffusion models may incur significant computational costs, which could hinder practical deployment in real-time applications.
- Ethical Considerations: As with any AI system that generates content, there are important ethical questions around bias, privacy, and the potential misuse of the technology that should be carefully considered.
Overall, the MS2SL approach represents an important step forward in the field of sign language generation, but continued research and development will be necessary to address these challenges and bring the technology to practical, real-world applications.
Conclusion
The MS2SL system presented in this paper demonstrates a novel approach to generating continuous, expressive sign language from spoken language input. By leveraging large language models and diffusion models, the system can produce more fluid and natural-looking sign language animations compared to previous methods.
This technology has the potential to significantly improve accessibility for deaf and hard-of-hearing individuals, allowing them to access spoken content more easily through high-quality sign language translations. As the research in this area continues to evolve, we can expect to see further advancements that bring us closer to seamless multimodal communication.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MS2SL: Multimodal Spoken Data-Driven Continuous Sign Language Production
Jian Ma, Wenguan Wang, Yi Yang, Feng Zheng
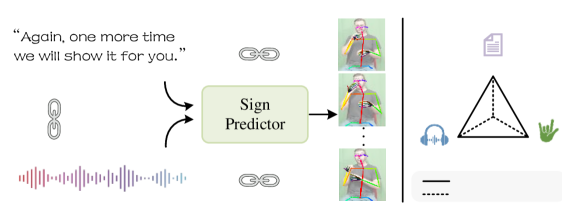
Sign language understanding has made significant strides; however, there is still no viable solution for generating sign sequences directly from entire spoken content, e.g., text or speech. In this paper, we propose a unified framework for continuous sign language production, easing communication between sign and non-sign language users. In particular, a sequence diffusion model, utilizing embeddings extracted from text or speech, is crafted to generate sign predictions step by step. Moreover, by creating a joint embedding space for text, audio, and sign, we bind these modalities and leverage the semantic consistency among them to provide informative feedback for the model training. This embedding-consistency learning strategy minimizes the reliance on sign triplets and ensures continuous model refinement, even with a missing audio modality. Experiments on How2Sign and PHOENIX14T datasets demonstrate that our model achieves competitive performance in sign language production.
Read more7/19/2024

0
SignLLM: Sign Languages Production Large Language Models
Sen Fang, Lei Wang, Ce Zheng, Yapeng Tian, Chen Chen
In this paper, we introduce the first comprehensive multilingual sign language dataset named Prompt2Sign, which builds from public data including American Sign Language (ASL) and seven others. Our dataset transforms a vast array of videos into a streamlined, model-friendly format, optimized for training with translation models like seq2seq and text2text. Building on this new dataset, we propose SignLLM, the first multilingual Sign Language Production (SLP) model, which includes two novel multilingual SLP modes that allow for the generation of sign language gestures from input text or prompt. Both of the modes can use a new loss and a module based on reinforcement learning, which accelerates the training by enhancing the model's capability to autonomously sample high-quality data. We present benchmark results of SignLLM, which demonstrate that our model achieves state-of-the-art performance on SLP tasks across eight sign languages.
Read more5/20/2024

0
Neural Sign Actors: A diffusion model for 3D sign language production from text
Vasileios Baltatzis, Rolandos Alexandros Potamias, Evangelos Ververas, Guanxiong Sun, Jiankang Deng, Stefanos Zafeiriou
Sign Languages (SL) serve as the primary mode of communication for the Deaf and Hard of Hearing communities. Deep learning methods for SL recognition and translation have achieved promising results. However, Sign Language Production (SLP) poses a challenge as the generated motions must be realistic and have precise semantic meaning. Most SLP methods rely on 2D data, which hinders their realism. In this work, a diffusion-based SLP model is trained on a curated large-scale dataset of 4D signing avatars and their corresponding text transcripts. The proposed method can generate dynamic sequences of 3D avatars from an unconstrained domain of discourse using a diffusion process formed on a novel and anatomically informed graph neural network defined on the SMPL-X body skeleton. Through quantitative and qualitative experiments, we show that the proposed method considerably outperforms previous methods of SLP. This work makes an important step towards realistic neural sign avatars, bridging the communication gap between Deaf and hearing communities.
Read more4/8/2024
0
A Tale of Two Languages: Large-Vocabulary Continuous Sign Language Recognition from Spoken Language Supervision
Charles Raude, K R Prajwal, Liliane Momeni, Hannah Bull, Samuel Albanie, Andrew Zisserman, Gul Varol
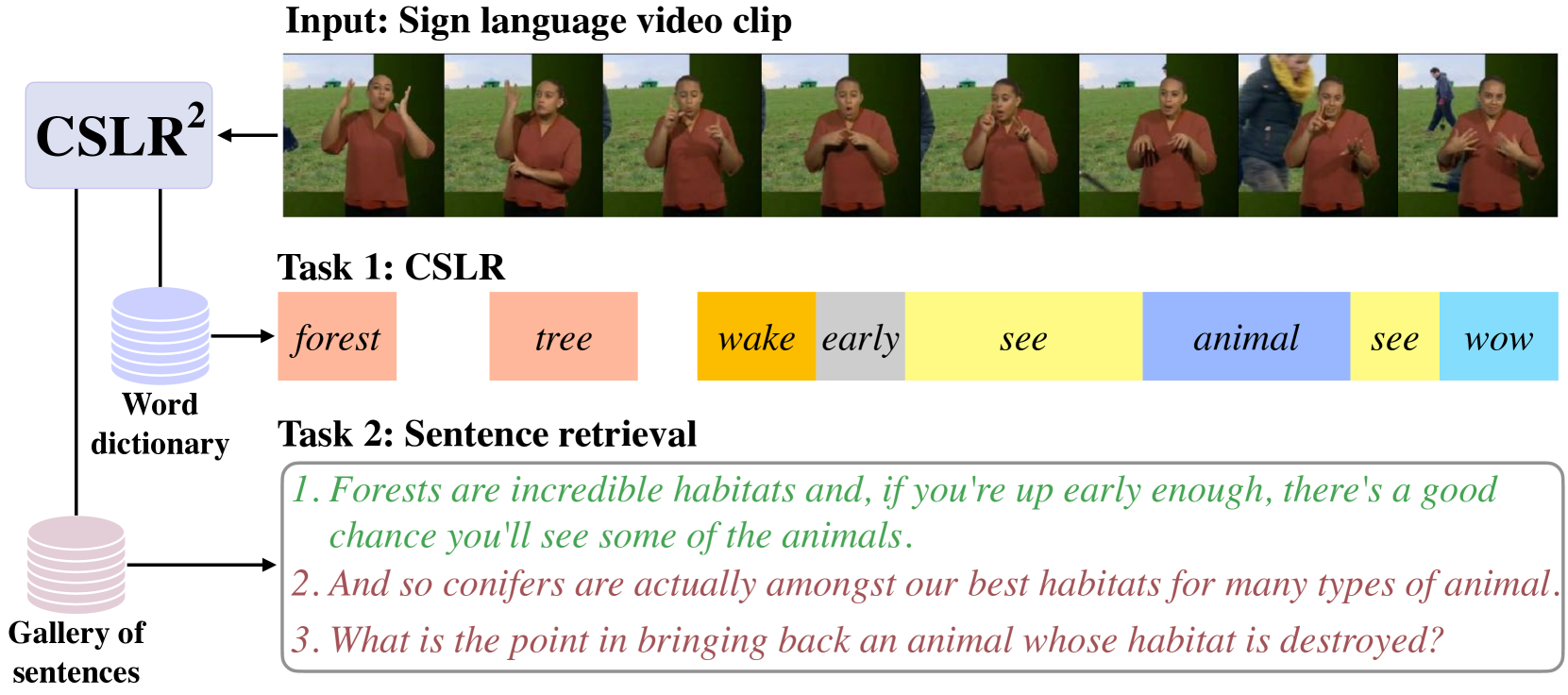
In this work, our goals are two fold: large-vocabulary continuous sign language recognition (CSLR), and sign language retrieval. To this end, we introduce a multi-task Transformer model, CSLR2, that is able to ingest a signing sequence and output in a joint embedding space between signed language and spoken language text. To enable CSLR evaluation in the large-vocabulary setting, we introduce new dataset annotations that have been manually collected. These provide continuous sign-level annotations for six hours of test videos, and will be made publicly available. We demonstrate that by a careful choice of loss functions, training the model for both the CSLR and retrieval tasks is mutually beneficial in terms of performance -- retrieval improves CSLR performance by providing context, while CSLR improves retrieval with more fine-grained supervision. We further show the benefits of leveraging weak and noisy supervision from large-vocabulary datasets such as BOBSL, namely sign-level pseudo-labels, and English subtitles. Our model significantly outperforms the previous state of the art on both tasks.
Read more5/17/2024