MSLIQA: Enhancing Learning Representations for Image Quality Assessment through Multi-Scale Learning

0

Sign in to get full access
Overview
- MSLIQA is a method for enhancing learning representations for image quality assessment (IQA) through multi-scale learning.
- It aims to improve the performance of no-reference IQA models by capturing information at different image scales.
- The key idea is to leverage multi-scale feature representations to better capture quality-relevant information.
Plain English Explanation
MSLIQA: Enhancing Learning Representations for Image Quality Assessment through Multi-Scale Learning is a new approach for assessing the quality of images without having a reference image. The researchers behind this method believe that looking at images at different scales, from small details to the overall picture, can help improve the accuracy of quality assessment.
Typically, no-reference IQA models rely on features extracted from a single scale of the image. MSLIQA instead uses a multi-scale approach, extracting features at multiple resolutions and combining them to get a more comprehensive understanding of image quality. The intuition is that quality-relevant information may be present at different scales, and capturing this can lead to better performance.
By considering the image at various levels of detail, the MSLIQA model can potentially identify subtle distortions or artifacts that might be missed by single-scale approaches. This could make the quality assessment more robust and accurate, benefiting applications like image compression, enhancement, and restoration.
Technical Explanation
The MSLIQA method involves using a multi-scale convolutional neural network architecture to extract features at multiple resolutions. Specifically, it takes an input image and passes it through a series of convolutional, pooling, and activation layers at different scales.
The features learned at each scale are then concatenated and fed into a final set of fully connected layers to predict the image quality score. This allows the model to capture quality-relevant information across scales, rather than relying solely on a single-scale representation.
The researchers evaluate MSLIQA on several no-reference IQA datasets and compare its performance to state-of-the-art single-scale IQA models. Their results demonstrate that the multi-scale learning approach can indeed lead to significant improvements in IQA accuracy, highlighting the importance of considering multi-scale information for this task.
Critical Analysis
The MSLIQA paper presents a well-designed and thorough evaluation of the proposed method. However, a few potential limitations or areas for further research are worth noting:
-
The paper does not explore the impact of different multi-scale architectures or feature fusion techniques. Investigating alternative ways of combining multi-scale representations could potentially lead to even greater performance gains.
-
The experiments are conducted on standard IQA datasets, but the researchers do not discuss the generalization of MSLIQA to real-world, diverse image quality scenarios. Evaluating the method's robustness in more realistic settings would be valuable.
-
While the multi-scale approach shows promise, the computational overhead of the model is not extensively discussed. Exploring ways to balance accuracy and efficiency would be an important consideration for practical applications.
Overall, the MSLIQA method presents a compelling approach to enhancing learning representations for image quality assessment. The critical analysis suggests that further research into the multi-scale learning paradigm, as well as its real-world applicability, could lead to even more impactful developments in this field.
Conclusion
MSLIQA is a novel method that leverages multi-scale learning to improve the performance of no-reference image quality assessment models. By capturing quality-relevant information at different scales, the approach can better understand the nuances of image quality and make more accurate predictions.
The results reported in the paper demonstrate the effectiveness of this multi-scale learning strategy, opening up new avenues for enhancing IQA capabilities. While the research has some limitations, the core idea of considering multi-scale representations holds significant promise for advancing the state of the art in this important computer vision task.
As image-based applications continue to proliferate, developing robust and accurate IQA models will become increasingly crucial. Techniques like MSLIQA, which can better extract relevant quality-related features, could have far-reaching implications for a wide range of image processing and analysis domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MSLIQA: Enhancing Learning Representations for Image Quality Assessment through Multi-Scale Learning
Nasim Jamshidi Avanaki, Abhijay Ghildyal, Nabajeet Barman, Saman Zadtootaghaj
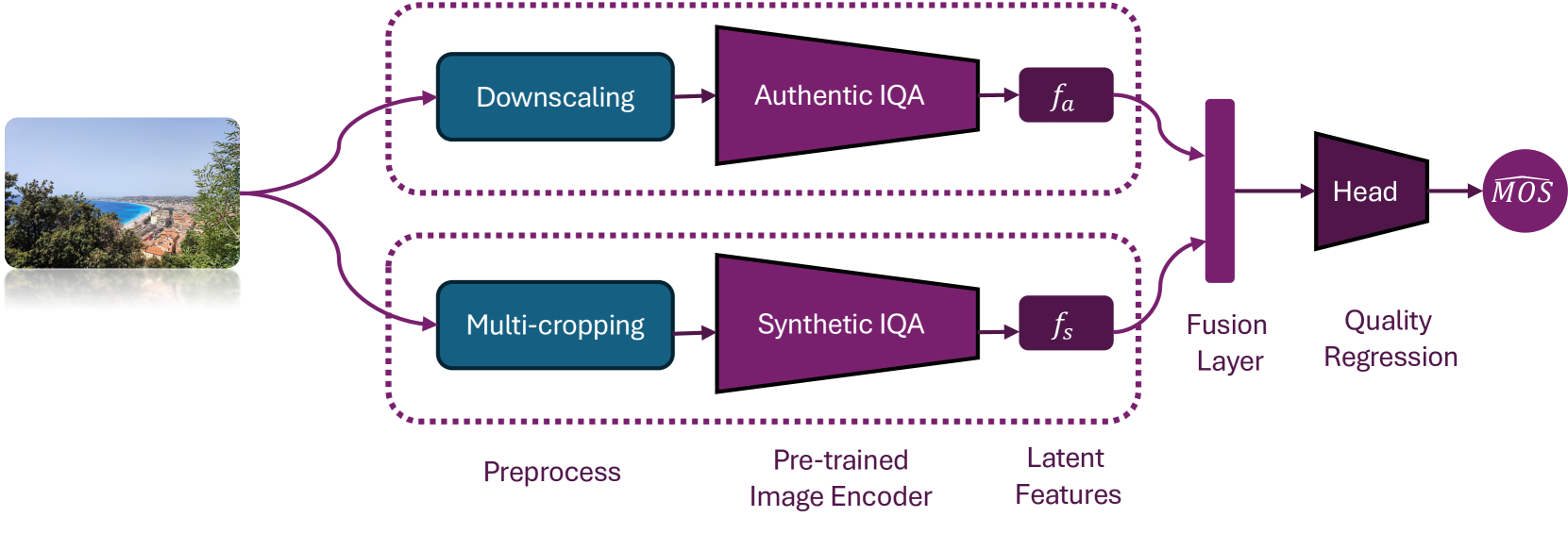
No-Reference Image Quality Assessment (NR-IQA) remains a challenging task due to the diversity of distortions and the lack of large annotated datasets. Many studies have attempted to tackle these challenges by developing more accurate NR-IQA models, often employing complex and computationally expensive networks, or by bridging the domain gap between various distortions to enhance performance on test datasets. In our work, we improve the performance of a generic lightweight NR-IQA model by introducing a novel augmentation strategy that boosts its performance by almost 28%. This augmentation strategy enables the network to better discriminate between different distortions in various parts of the image by zooming in and out. Additionally, the inclusion of test-time augmentation further enhances performance, making our lightweight network's results comparable to the current state-of-the-art models, simply through the use of augmentations.
Read more9/9/2024
0
LAR-IQA: A Lightweight, Accurate, and Robust No-Reference Image Quality Assessment Model
Nasim Jamshidi Avanaki, Abhijay Ghildyal, Nabajeet Barman, Saman Zadtootaghaj
Recent advancements in the field of No-Reference Image Quality Assessment (NR-IQA) using deep learning techniques demonstrate high performance across multiple open-source datasets. However, such models are typically very large and complex making them not so suitable for real-world deployment, especially on resource- and battery-constrained mobile devices. To address this limitation, we propose a compact, lightweight NR-IQA model that achieves state-of-the-art (SOTA) performance on ECCV AIM UHD-IQA challenge validation and test datasets while being also nearly 5.7 times faster than the fastest SOTA model. Our model features a dual-branch architecture, with each branch separately trained on synthetically and authentically distorted images which enhances the model's generalizability across different distortion types. To improve robustness under diverse real-world visual conditions, we additionally incorporate multiple color spaces during the training process. We also demonstrate the higher accuracy of recently proposed Kolmogorov-Arnold Networks (KANs) for final quality regression as compared to the conventional Multi-Layer Perceptrons (MLPs). Our evaluation considering various open-source datasets highlights the practical, high-accuracy, and robust performance of our proposed lightweight model. Code: https://github.com/nasimjamshidi/LAR-IQA.
Read more9/9/2024

0
MobileIQA: Exploiting Mobile-level Diverse Opinion Network For No-Reference Image Quality Assessment Using Knowledge Distillation
Zewen Chen, Sunhan Xu, Yun Zeng, Haochen Guo, Jian Guo, Shuai Liu, Juan Wang, Bing Li, Weiming Hu, Dehua Liu, Hesong Li
With the rising demand for high-resolution (HR) images, No-Reference Image Quality Assessment (NR-IQA) gains more attention, as it can ecaluate image quality in real-time on mobile devices and enhance user experience. However, existing NR-IQA methods often resize or crop the HR images into small resolution, which leads to a loss of important details. And most of them are of high computational complexity, which hinders their application on mobile devices due to limited computational resources. To address these challenges, we propose MobileIQA, a novel approach that utilizes lightweight backbones to efficiently assess image quality while preserving image details through high-resolution input. MobileIQA employs the proposed multi-view attention learning (MAL) module to capture diverse opinions, simulating subjective opinions provided by different annotators during the dataset annotation process. The model uses a teacher model to guide the learning of a student model through knowledge distillation. This method significantly reduces computational complexity while maintaining high performance. Experiments demonstrate that MobileIQA outperforms novel IQA methods on evaluation metrics and computational efficiency. The code is available at https://github.com/chencn2020/MobileIQA.
Read more9/4/2024
🤷
0
Cross-IQA: Unsupervised Learning for Image Quality Assessment
Zhen Zhang
Automatic perception of image quality is a challenging problem that impacts billions of Internet and social media users daily. To advance research in this field, we propose a no-reference image quality assessment (NR-IQA) method termed Cross-IQA based on vision transformer(ViT) model. The proposed Cross-IQA method can learn image quality features from unlabeled image data. We construct the pretext task of synthesized image reconstruction to unsupervised extract the image quality information based ViT block. The pretrained encoder of Cross-IQA is used to fine-tune a linear regression model for score prediction. Experimental results show that Cross-IQA can achieve state-of-the-art performance in assessing the low-frequency degradation information (e.g., color change, blurring, etc.) of images compared with the classical full-reference IQA and NR-IQA under the same datasets.
Read more5/8/2024