Multi-branch Collaborative Learning Network for 3D Visual Grounding

0

Sign in to get full access
Overview
- This paper introduces a Multi-branch Collaborative Learning Network (MCLN) for 3D visual grounding, which aims to jointly train 3D referring expression comprehension and 3D referring expression segmentation.
- The proposed MCLN model leverages multiple branches to capture different aspects of the 3D scene, including visual, linguistic, and spatial information, and enables collaborative learning between the two tasks.
- The authors demonstrate the effectiveness of MCLN on several benchmark datasets, showing improved performance compared to previous state-of-the-art methods.
Plain English Explanation
The paper describes a new machine learning model called the Multi-branch Collaborative Learning Network (MCLN) that is designed to help computers better understand 3D scenes and the objects within them. The key idea is to train the model on two related tasks simultaneously: 1) identifying which object in a 3D scene a given text description refers to (referring expression comprehension), and 2) segmenting the object that the text description refers to (referring expression segmentation).
By training the model on these two tasks together, the authors found that the model was able to learn more effectively than if it was trained on each task separately. The model has multiple "branches" that focus on different aspects of the 3D scene, such as the visual appearance, the language used to describe it, and the spatial relationships between objects. These different branches work together to help the model develop a more complete understanding of the 3D scene.
The authors tested their MCLN model on several standard benchmark datasets for 3D visual grounding, and showed that it outperformed previous state-of-the-art methods. This suggests that their approach of joint training on related tasks and leveraging multiple information sources is a promising direction for improving computer vision and language understanding in 3D environments.
Technical Explanation
The authors propose a Multi-branch Collaborative Learning Network (MCLN) for 3D visual grounding, which jointly trains 3D referring expression comprehension and 3D referring expression segmentation. The MCLN model consists of multiple branches that capture different aspects of the 3D scene, including visual, linguistic, and spatial information.
The visual branch takes in the 3D point cloud and learns visual features. The linguistic branch encodes the referring expression text. The spatial branch models the spatial relationships between objects in the 3D scene. These three branches are connected through a collaborative learning module, which enables them to learn from each other during the joint training process.
The authors evaluate the MCLN model on several 3D referring expression comprehension and 3D referring expression segmentation benchmarks, including ScanRefer, Nr3D, and ReferIt3D. They demonstrate that the MCLN model outperforms previous state-of-the-art methods, highlighting the advantages of the proposed multi-branch collaborative learning approach.
Critical Analysis
The paper provides a novel and promising approach for 3D visual grounding by jointly training referring expression comprehension and segmentation tasks. The multi-branch architecture and collaborative learning mechanism are well-designed to capture the various aspects of the 3D scene and enable mutual information sharing between the tasks.
However, the paper does not discuss the computational complexity and training efficiency of the MCLN model, which could be an important consideration for real-world applications. Additionally, the authors only evaluate their model on a limited set of benchmark datasets, and it would be valuable to see how it performs on a wider range of 3D scene understanding tasks, such as 3D object detection or 3D scene reconstruction.
Further research could also explore ways to incorporate more advanced 3D scene representation and reasoning techniques into the MCLN framework, to enhance its ability to handle complex 3D environments and language interactions.
Conclusion
The Multi-branch Collaborative Learning Network (MCLN) presented in this paper is a promising approach for 3D visual grounding, demonstrating the benefits of jointly training related tasks and leveraging multi-modal information sources. The strong performance on benchmark datasets suggests that this method could be valuable for a range of 3D scene understanding applications, from augmented reality to robotic navigation. As the field of 3D computer vision and language understanding continues to advance, further research building on the insights from this work could lead to even more powerful and versatile models for interacting with and comprehending the 3D world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multi-branch Collaborative Learning Network for 3D Visual Grounding
Zhipeng Qian, Yiwei Ma, Zhekai Lin, Jiayi Ji, Xiawu Zheng, Xiaoshuai Sun, Rongrong Ji
3D referring expression comprehension (3DREC) and segmentation (3DRES) have overlapping objectives, indicating their potential for collaboration. However, existing collaborative approaches predominantly depend on the results of one task to make predictions for the other, limiting effective collaboration. We argue that employing separate branches for 3DREC and 3DRES tasks enhances the model's capacity to learn specific information for each task, enabling them to acquire complementary knowledge. Thus, we propose the MCLN framework, which includes independent branches for 3DREC and 3DRES tasks. This enables dedicated exploration of each task and effective coordination between the branches. Furthermore, to facilitate mutual reinforcement between these branches, we introduce a Relative Superpoint Aggregation (RSA) module and an Adaptive Soft Alignment (ASA) module. These modules significantly contribute to the precise alignment of prediction results from the two branches, directing the module to allocate increased attention to key positions. Comprehensive experimental evaluation demonstrates that our proposed method achieves state-of-the-art performance on both the 3DREC and 3DRES tasks, with an increase of 2.05% in [email protected] for 3DREC and 3.96% in mIoU for 3DRES.
Read more7/11/2024

0
3D-GRES: Generalized 3D Referring Expression Segmentation
Changli Wu, Yihang Liu, Jiayi Ji, Yiwei Ma, Haowei Wang, Gen Luo, Henghui Ding, Xiaoshuai Sun, Rongrong Ji
3D Referring Expression Segmentation (3D-RES) is dedicated to segmenting a specific instance within a 3D space based on a natural language description. However, current approaches are limited to segmenting a single target, restricting the versatility of the task. To overcome this limitation, we introduce Generalized 3D Referring Expression Segmentation (3D-GRES), which extends the capability to segment any number of instances based on natural language instructions. In addressing this broader task, we propose the Multi-Query Decoupled Interaction Network (MDIN), designed to break down multi-object segmentation tasks into simpler, individual segmentations. MDIN comprises two fundamental components: Text-driven Sparse Queries (TSQ) and Multi-object Decoupling Optimization (MDO). TSQ generates sparse point cloud features distributed over key targets as the initialization for queries. Meanwhile, MDO is tasked with assigning each target in multi-object scenarios to different queries while maintaining their semantic consistency. To adapt to this new task, we build a new dataset, namely Multi3DRes. Our comprehensive evaluations on this dataset demonstrate substantial enhancements over existing models, thus charting a new path for intricate multi-object 3D scene comprehension. The benchmark and code are available at https://github.com/sosppxo/MDIN.
Read more8/1/2024
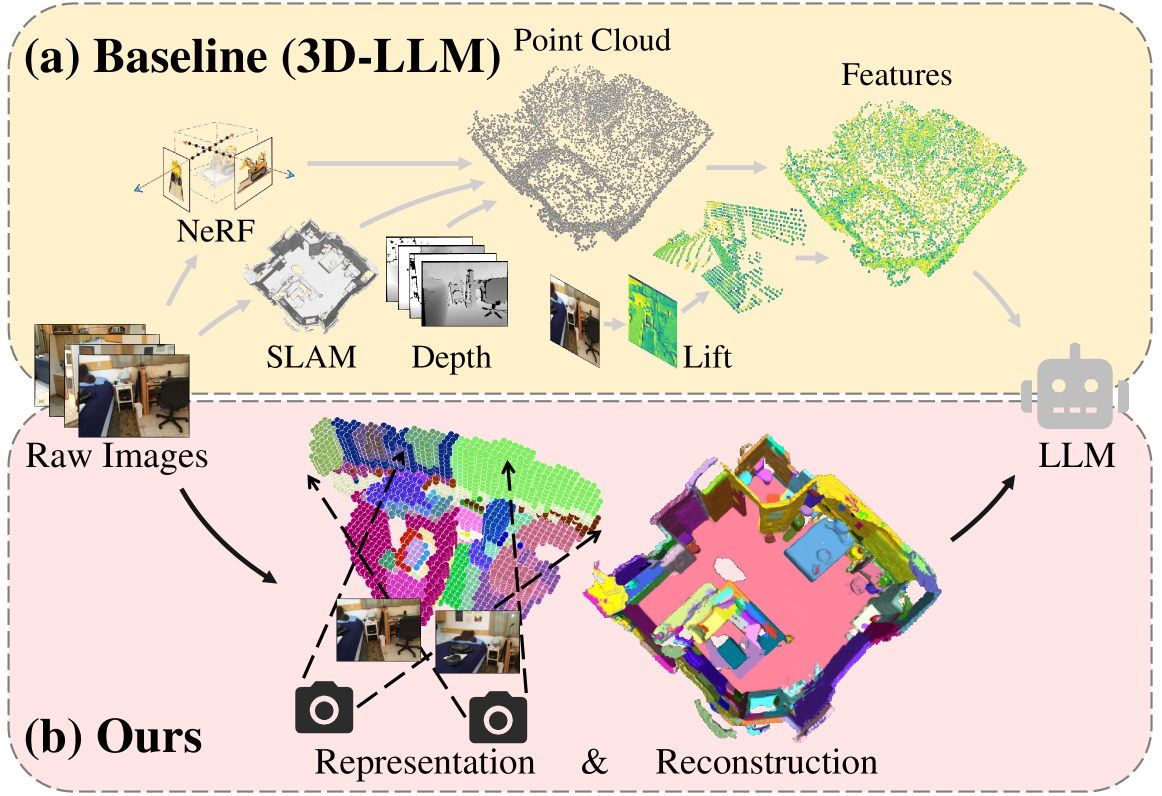
0
Unified Scene Representation and Reconstruction for 3D Large Language Models
Tao Chu, Pan Zhang, Xiaoyi Dong, Yuhang Zang, Qiong Liu, Jiaqi Wang
Enabling Large Language Models (LLMs) to interact with 3D environments is challenging. Existing approaches extract point clouds either from ground truth (GT) geometry or 3D scenes reconstructed by auxiliary models. Text-image aligned 2D features from CLIP are then lifted to point clouds, which serve as inputs for LLMs. However, this solution lacks the establishment of 3D point-to-point connections, leading to a deficiency of spatial structure information. Concurrently, the absence of integration and unification between the geometric and semantic representations of the scene culminates in a diminished level of 3D scene understanding. In this paper, we demonstrate the importance of having a unified scene representation and reconstruction framework, which is essential for LLMs in 3D scenes. Specifically, we introduce Uni3DR^2 extracts 3D geometric and semantic aware representation features via the frozen pre-trained 2D foundation models (e.g., CLIP and SAM) and a multi-scale aggregate 3D decoder. Our learned 3D representations not only contribute to the reconstruction process but also provide valuable knowledge for LLMs. Experimental results validate that our Uni3DR^2 yields convincing gains over the baseline on the 3D reconstruction dataset ScanNet (increasing F-Score by +1.8%). When applied to LLMs, our Uni3DR^2-LLM exhibits superior performance over the baseline on the 3D vision-language understanding dataset ScanQA (increasing BLEU-1 by +4.0% and +4.2% on the val set and test set, respectively). Furthermore, it outperforms the state-of-the-art method that uses additional GT point clouds on both ScanQA and 3DMV-VQA.
Read more4/22/2024

0
Dual Attribute-Spatial Relation Alignment for 3D Visual Grounding
Yue Xu, Kaizhi Yang, Jiebo Luo, Xuejin Chen
3D visual grounding is an emerging research area dedicated to making connections between the 3D physical world and natural language, which is crucial for achieving embodied intelligence. In this paper, we propose DASANet, a Dual Attribute-Spatial relation Alignment Network that separately models and aligns object attributes and spatial relation features between language and 3D vision modalities. We decompose both the language and 3D point cloud input into two separate parts and design a dual-branch attention module to separately model the decomposed inputs while preserving global context in attribute-spatial feature fusion by cross attentions. Our DASANet achieves the highest grounding accuracy 65.1% on the Nr3D dataset, 1.3% higher than the best competitor. Besides, the visualization of the two branches proves that our method is efficient and highly interpretable.
Read more6/14/2024