Multi-granular Adversarial Attacks against Black-box Neural Ranking Models
2404.01574
0
0

Abstract
Adversarial ranking attacks have gained increasing attention due to their success in probing vulnerabilities, and, hence, enhancing the robustness, of neural ranking models. Conventional attack methods employ perturbations at a single granularity, e.g., word or sentence level, to target documents. However, limiting perturbations to a single level of granularity may reduce the flexibility of adversarial examples, thereby diminishing the potential threat of the attack. Therefore, we focus on generating high-quality adversarial examples by incorporating multi-granular perturbations. Achieving this objective involves tackling a combinatorial explosion problem, which requires identifying an optimal combination of perturbations across all possible levels of granularity, positions, and textual pieces. To address this challenge, we transform the multi-granular adversarial attack into a sequential decision-making process, where perturbations in the next attack step build on the perturbed document in the current attack step. Since the attack process can only access the final state without direct intermediate signals, we use reinforcement learning to perform multi-granular attacks. During the reinforcement learning process, two agents work cooperatively to identify multi-granular vulnerabilities as attack targets and organize perturbation candidates into a final perturbation sequence. Experimental results show that our attack method surpasses prevailing baselines in both attack effectiveness and imperceptibility.
Create account to get full access
Overview
- This paper explores the development of multi-granular adversarial attacks against black-box neural ranking models, which are machine learning models used to rank and recommend content.
- The researchers propose a novel technique that can generate adversarial examples - slightly modified inputs that can trick the ranking model into making incorrect predictions.
- These attacks are designed to be effective even when the internal workings of the ranking model are unknown, making them applicable in real-world scenarios.
Plain English Explanation
Neural ranking models are a type of machine learning algorithm used to sort and recommend content, such as search results or product listings. These models are trained on large datasets to learn patterns and make accurate predictions about which items are most relevant to a user's query.
However, researchers have found that these models can be vulnerable to adversarial attacks. An adversarial attack involves making small, targeted changes to an input (like a piece of text) that cause the model to misclassify or misjudge it, even though the changes are imperceptible to a human. This can be a significant security and reliability issue for real-world applications of neural ranking models.
In this paper, the researchers develop a new type of adversarial attack called a "multi-granular" attack. This attack works at multiple levels of the input text - from individual words to whole sentences - to find the most effective combination of changes that will fool the ranking model. Importantly, this attack can be carried out even when the internal workings of the ranking model are unknown, making it applicable in realistic settings where the model is treated as a black box.
The researchers conduct extensive experiments to demonstrate the effectiveness of their multi-granular attack approach against several state-of-the-art neural ranking models. Their results show that this attack can significantly degrade the performance of the models, highlighting the need for improved robustness and security in real-world applications of these technologies.
Technical Explanation
The paper introduces a novel technique called "multi-granular adversarial attacks" against black-box neural ranking models. These models are used in a variety of applications, such as web search and product recommendation, to sort and present content to users.
The key innovation of this work is the development of an adversarial attack that operates at multiple levels of granularity within the input text. Specifically, the attack can make targeted changes to individual words, phrases, or even entire sentences to generate an adversarial example that fools the ranking model into making incorrect predictions.
Importantly, this multi-granular attack is designed to be effective even when the internal architecture and parameters of the ranking model are unknown, treating it as a black box. This makes the attack more practical for real-world scenarios where the model details may not be accessible.
The researchers formulate the attack as a reinforcement learning problem, where the goal is to learn a policy that generates the most effective adversarial perturbations. They conduct experiments on several state-of-the-art neural ranking models, including BERT-based and transformer-based architectures, and demonstrate that their multi-granular attack can significantly degrade the performance of these models.
The results highlight the vulnerability of current neural ranking models to targeted adversarial attacks, even when the models are treated as black boxes. This underscores the need for improved robustness and security measures in the deployment of these technologies, an important area for future research and development.
Critical Analysis
The paper makes a valuable contribution by addressing the security and reliability concerns surrounding the use of black-box neural ranking models in real-world applications. The proposed multi-granular adversarial attack is a novel and effective approach that exploits the vulnerabilities of these models at multiple levels of the input text.
One potential limitation of the research is the reliance on surrogate models for the black-box attack, which may not fully capture the complexity of real-world ranking models. Additionally, the paper does not explore potential defense mechanisms or strategies for improving the robustness of these models against adversarial attacks.
Further research could investigate the transferability of the multi-granular attack to other types of neural ranking models, as well as the development of adaptive defenses that can detect and mitigate such attacks. Exploring the potential real-world implications and applications of this research would also be a valuable direction for future work.
Overall, this paper highlights the importance of addressing the security and reliability of neural ranking models, which are increasingly being deployed in high-stakes applications. The multi-granular adversarial attack approach developed in this research represents an important step towards understanding and addressing these challenges.
Conclusion
This paper presents a novel technique for conducting multi-granular adversarial attacks against black-box neural ranking models, which are widely used in applications such as web search and product recommendation. The researchers demonstrate the effectiveness of their approach in significantly degrading the performance of state-of-the-art ranking models, even when their internal workings are unknown.
The findings of this study underscore the need for improved robustness and security measures in the deployment of neural ranking models, as they can be vulnerable to targeted adversarial attacks. Further research in this area could lead to the development of more secure and reliable ranking algorithms, ultimately benefiting users and organizations that rely on these technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔮
Position Paper: Beyond Robustness Against Single Attack Types
Sihui Dai, Chong Xiang, Tong Wu, Prateek Mittal
0
0
Current research on defending against adversarial examples focuses primarily on achieving robustness against a single attack type such as $ell_2$ or $ell_{infty}$-bounded attacks. However, the space of possible perturbations is much larger and currently cannot be modeled by a single attack type. The discrepancy between the focus of current defenses and the space of attacks of interest calls to question the practicality of existing defenses and the reliability of their evaluation. In this position paper, we argue that the research community should look beyond single attack robustness, and we draw attention to three potential directions involving robustness against multiple attacks: simultaneous multiattack robustness, unforeseen attack robustness, and a newly defined problem setting which we call continual adaptive robustness. We provide a unified framework which rigorously defines these problem settings, synthesize existing research in these fields, and outline open directions. We hope that our position paper inspires more research in simultaneous multiattack, unforeseen attack, and continual adaptive robustness.
5/3/2024
🌿
Transferability Ranking of Adversarial Examples
Mosh Levy, Guy Amit, Yuval Elovici, Yisroel Mirsky
0
0
Adversarial transferability in black-box scenarios presents a unique challenge: while attackers can employ surrogate models to craft adversarial examples, they lack assurance on whether these examples will successfully compromise the target model. Until now, the prevalent method to ascertain success has been trial and error-testing crafted samples directly on the victim model. This approach, however, risks detection with every attempt, forcing attackers to either perfect their first try or face exposure. Our paper introduces a ranking strategy that refines the transfer attack process, enabling the attacker to estimate the likelihood of success without repeated trials on the victim's system. By leveraging a set of diverse surrogate models, our method can predict transferability of adversarial examples. This strategy can be used to either select the best sample to use in an attack or the best perturbation to apply to a specific sample. Using our strategy, we were able to raise the transferability of adversarial examples from a mere 20% - akin to random selection-up to near upper-bound levels, with some scenarios even witnessing a 100% success rate. This substantial improvement not only sheds light on the shared susceptibilities across diverse architectures but also demonstrates that attackers can forego the detectable trial-and-error tactics raising increasing the threat of surrogate-based attacks.
4/19/2024

Adversarial Attacks and Dimensionality in Text Classifiers
Nandish Chattopadhyay, Atreya Goswami, Anupam Chattopadhyay
0
0
Adversarial attacks on machine learning algorithms have been a key deterrent to the adoption of AI in many real-world use cases. They significantly undermine the ability of high-performance neural networks by forcing misclassifications. These attacks introduce minute and structured perturbations or alterations in the test samples, imperceptible to human annotators in general, but trained neural networks and other models are sensitive to it. Historically, adversarial attacks have been first identified and studied in the domain of image processing. In this paper, we study adversarial examples in the field of natural language processing, specifically text classification tasks. We investigate the reasons for adversarial vulnerability, particularly in relation to the inherent dimensionality of the model. Our key finding is that there is a very strong correlation between the embedding dimensionality of the adversarial samples and their effectiveness on models tuned with input samples with same embedding dimension. We utilize this sensitivity to design an adversarial defense mechanism. We use ensemble models of varying inherent dimensionality to thwart the attacks. This is tested on multiple datasets for its efficacy in providing robustness. We also study the problem of measuring adversarial perturbation using different distance metrics. For all of the aforementioned studies, we have run tests on multiple models with varying dimensionality and used a word-vector level adversarial attack to substantiate the findings.
4/4/2024
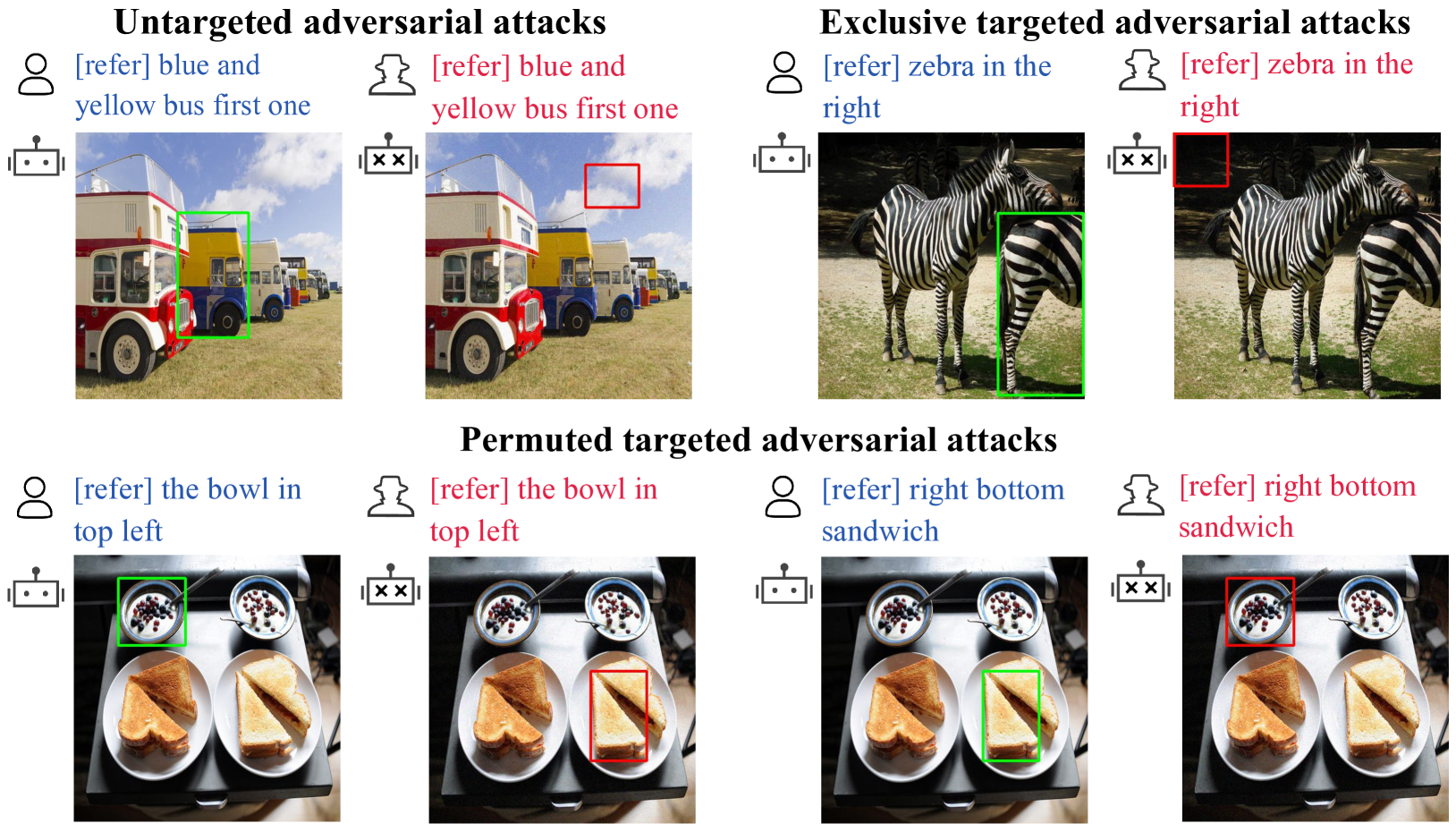
Adversarial Robustness for Visual Grounding of Multimodal Large Language Models
Kuofeng Gao, Yang Bai, Jiawang Bai, Yong Yang, Shu-Tao Xia
0
0
Multi-modal Large Language Models (MLLMs) have recently achieved enhanced performance across various vision-language tasks including visual grounding capabilities. However, the adversarial robustness of visual grounding remains unexplored in MLLMs. To fill this gap, we use referring expression comprehension (REC) as an example task in visual grounding and propose three adversarial attack paradigms as follows. Firstly, untargeted adversarial attacks induce MLLMs to generate incorrect bounding boxes for each object. Besides, exclusive targeted adversarial attacks cause all generated outputs to the same target bounding box. In addition, permuted targeted adversarial attacks aim to permute all bounding boxes among different objects within a single image. Extensive experiments demonstrate that the proposed methods can successfully attack visual grounding capabilities of MLLMs. Our methods not only provide a new perspective for designing novel attacks but also serve as a strong baseline for improving the adversarial robustness for visual grounding of MLLMs.
5/17/2024