Multi-modal Generative Models in Recommendation System

0

Sign in to get full access
Overview
- Multimodal recommendation systems leverage multiple data sources, such as images, text, and audio, to provide more personalized and accurate recommendations.
- Generative models like Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs) can be used to model the complex relationships between different data modalities in recommendation systems.
- This paper explores the use of multimodal generative models in recommendation systems, discussing the benefits, challenges, and recent advancements in this field.
Plain English Explanation
Recommendation systems are designed to suggest products, services, or content that users might be interested in. Traditionally, these systems have relied on a single data source, such as a user's past purchases or ratings. However, multimodal recommendation systems aim to leverage multiple types of data, like images, text, and audio, to provide more personalized and accurate recommendations.
Generative models, such as Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs), can be particularly useful in this context. These models can learn the complex relationships between different data modalities, allowing recommendation systems to make more informed and relevant suggestions.
For example, a multimodal recommendation system might use a user's past purchases, the images and descriptions of products, and even audio reviews to better understand the user's preferences and interests. This can lead to more accurate and personalized recommendations, helping users discover new products or services they're likely to enjoy.
Technical Explanation
The paper explores the use of multimodal generative models in recommendation systems. These models can learn the underlying patterns and relationships between different data modalities, such as images, text, and audio, to provide more accurate and personalized recommendations.
The authors discuss the benefits of using multimodal generative models in recommendation systems, including:
- Improved personalization by leveraging diverse data sources
- Enhanced user experience through more relevant and engaging recommendations
- Increased understanding of user preferences and interests
- Potential to uncover hidden patterns and insights in the data
The paper also covers the challenges and recent advancements in this field, such as:
- Addressing the complexity of modeling the interactions between multiple data modalities
- Developing efficient and scalable multimodal generative model architectures
- Incorporating domain-specific knowledge and constraints into the models
- Ensuring privacy and fairness in multimodal recommendation systems
Critical Analysis
The paper provides a comprehensive overview of the use of multimodal generative models in recommendation systems, highlighting both the benefits and challenges of this approach. The authors acknowledge that while multimodal recommendation systems have the potential to greatly improve the user experience, there are still several open research questions and limitations that need to be addressed.
One potential limitation mentioned is the complexity of modeling the intricate relationships between multiple data modalities, which can be computationally intensive and may require specialized architectures and training techniques. Additionally, the paper notes that incorporating domain-specific knowledge and constraints into the models can be a significant challenge, as it requires a deep understanding of the recommendation domain and careful design of the model architecture.
The authors also emphasize the importance of ensuring privacy and fairness in multimodal recommendation systems, as the use of diverse data sources may introduce new ethical and legal concerns. This is an area that warrants further research and the development of robust guidelines and best practices.
Overall, the paper provides a valuable contribution to the field of recommendation systems by highlighting the potential of multimodal generative models and the key research challenges that need to be addressed to realize their full potential.
Conclusion
This paper presents an in-depth exploration of the use of multimodal generative models in recommendation systems. Multimodal recommendation systems leverage diverse data sources, such as images, text, and audio, to provide more personalized and accurate recommendations. Generative models, like VAEs and GANs, can be particularly useful in this context, as they can learn the complex relationships between different data modalities.
The paper discusses the benefits of using multimodal generative models in recommendation systems, including improved personalization, enhanced user experience, and a deeper understanding of user preferences. It also covers the challenges and recent advancements in this field, such as addressing the complexity of modeling multimodal interactions, developing efficient model architectures, and ensuring privacy and fairness.
The critical analysis highlights the potential limitations of this approach, including the computational complexity of modeling multimodal relationships and the need to incorporate domain-specific knowledge and constraints. The authors also emphasize the importance of addressing ethical and legal concerns related to privacy and fairness in multimodal recommendation systems.
Overall, this paper provides a valuable contribution to the field of recommendation systems by exploring the promising applications of multimodal generative models and the key research directions that could further advance this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multi-modal Generative Models in Recommendation System
Arnau Ramisa, Rene Vidal, Yashar Deldjoo, Zhankui He, Julian McAuley, Anton Korikov, Scott Sanner, Mahesh Sathiamoorthy, Atoosa Kasrizadeh, Silvia Milano, Francesco Ricci
Many recommendation systems limit user inputs to text strings or behavior signals such as clicks and purchases, and system outputs to a list of products sorted by relevance. With the advent of generative AI, users have come to expect richer levels of interactions. In visual search, for example, a user may provide a picture of their desired product along with a natural language modification of the content of the picture (e.g., a dress like the one shown in the picture but in red color). Moreover, users may want to better understand the recommendations they receive by visualizing how the product fits their use case, e.g., with a representation of how a garment might look on them, or how a furniture item might look in their room. Such advanced levels of interaction require recommendation systems that are able to discover both shared and complementary information about the product across modalities, and visualize the product in a realistic and informative way. However, existing systems often treat multiple modalities independently: text search is usually done by comparing the user query to product titles and descriptions, while visual search is typically done by comparing an image provided by the customer to product images. We argue that future recommendation systems will benefit from a multi-modal understanding of the products that leverages the rich information retailers have about both customers and products to come up with the best recommendations. In this chapter we review recommendation systems that use multiple data modalities simultaneously.
Read more9/18/2024
0
Multimodal Pretraining, Adaptation, and Generation for Recommendation: A Survey
Qijiong Liu, Jieming Zhu, Yanting Yang, Quanyu Dai, Zhaocheng Du, Xiao-Ming Wu, Zhou Zhao, Rui Zhang, Zhenhua Dong
Personalized recommendation serves as a ubiquitous channel for users to discover information tailored to their interests. However, traditional recommendation models primarily rely on unique IDs and categorical features for user-item matching, potentially overlooking the nuanced essence of raw item contents across multiple modalities such as text, image, audio, and video. This underutilization of multimodal data poses a limitation to recommender systems, especially in multimedia services like news, music, and short-video platforms. The recent advancements in large multimodal models offer new opportunities and challenges in developing content-aware recommender systems. This survey seeks to provide a comprehensive exploration of the latest advancements and future trajectories in multimodal pretraining, adaptation, and generation techniques, as well as their applications in enhancing recommender systems. Furthermore, we discuss current open challenges and opportunities for future research in this dynamic domain. We believe that this survey, alongside the curated resources, will provide valuable insights to inspire further advancements in this evolving landscape.
Read more7/4/2024
🛸
0
Multimodal Pretraining and Generation for Recommendation: A Tutorial
Jieming Zhu, Chuhan Wu, Rui Zhang, Zhenhua Dong
Personalized recommendation stands as a ubiquitous channel for users to explore information or items aligned with their interests. Nevertheless, prevailing recommendation models predominantly rely on unique IDs and categorical features for user-item matching. While this ID-centric approach has witnessed considerable success, it falls short in comprehensively grasping the essence of raw item contents across diverse modalities, such as text, image, audio, and video. This underutilization of multimodal data poses a limitation to recommender systems, particularly in the realm of multimedia services like news, music, and short-video platforms. The recent surge in pretraining and generation techniques presents both opportunities and challenges in the development of multimodal recommender systems. This tutorial seeks to provide a thorough exploration of the latest advancements and future trajectories in multimodal pretraining and generation techniques within the realm of recommender systems. The tutorial comprises three parts: multimodal pretraining, multimodal generation, and industrial applications and open challenges in the field of recommendation. Our target audience encompasses scholars, practitioners, and other parties interested in this domain. By providing a succinct overview of the field, we aspire to facilitate a swift understanding of multimodal recommendation and foster meaningful discussions on the future development of this evolving landscape.
Read more5/14/2024
0
Dataset and Models for Item Recommendation Using Multi-Modal User Interactions
Simone Borg Bruun, Krisztian Balog, Maria Maistro
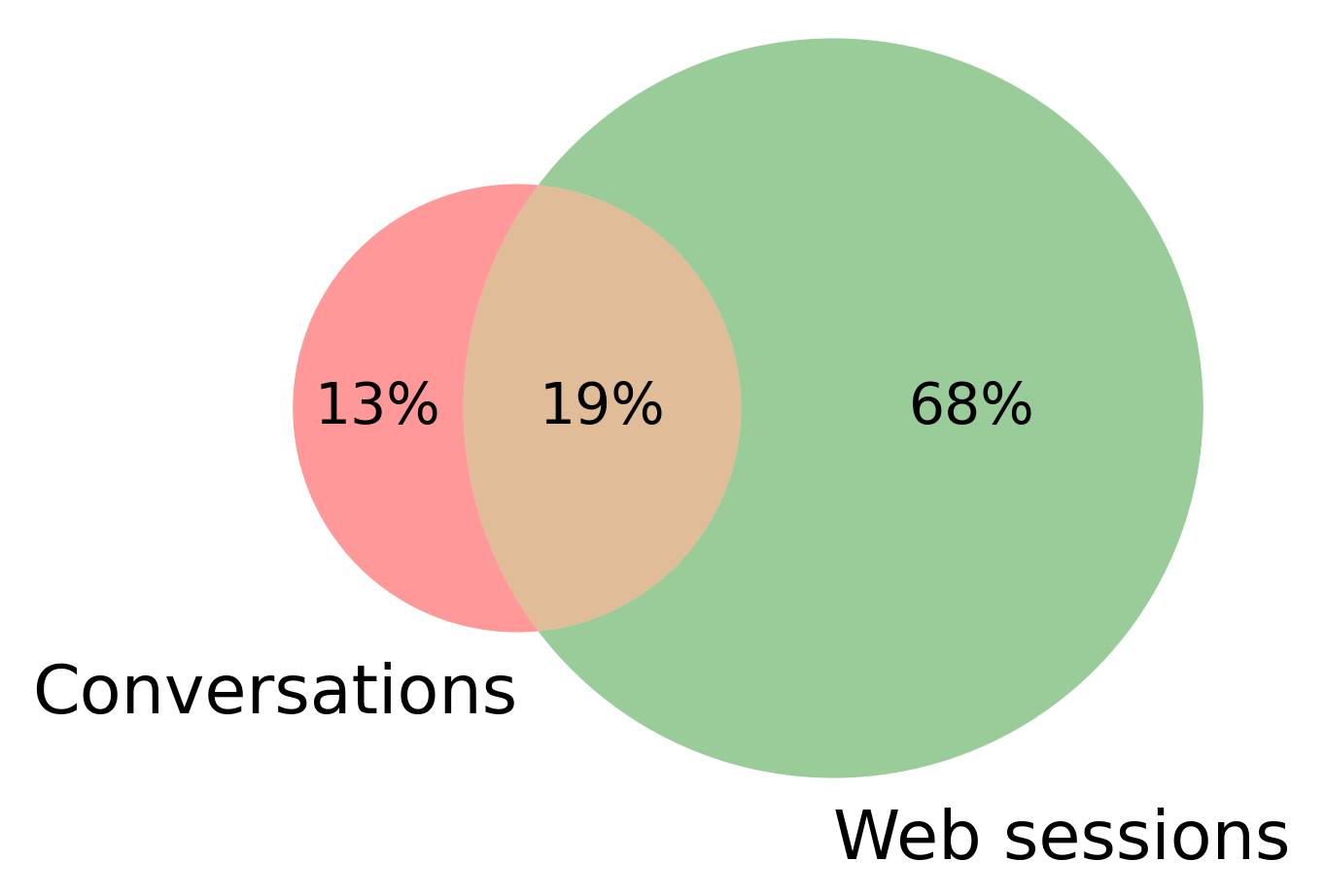
While recommender systems with multi-modal item representations (image, audio, and text), have been widely explored, learning recommendations from multi-modal user interactions (e.g., clicks and speech) remains an open problem. We study the case of multi-modal user interactions in a setting where users engage with a service provider through multiple channels (website and call center). In such cases, incomplete modalities naturally occur, since not all users interact through all the available channels. To address these challenges, we publish a real-world dataset that allows progress in this under-researched area. We further present and benchmark various methods for leveraging multi-modal user interactions for item recommendations, and propose a novel approach that specifically deals with missing modalities by mapping user interactions to a common feature space. Our analysis reveals important interactions between the different modalities and that a frequently occurring modality can enhance learning from a less frequent one.
Read more5/8/2024