Multi-Resolution Diffusion for Privacy-Sensitive Recommender Systems
2311.03488
0
0
✨
Abstract
While recommender systems have become an integral component of the Web experience, their heavy reliance on user data raises privacy and security concerns. Substituting user data with synthetic data can address these concerns, but accurately replicating these real-world datasets has been a notoriously challenging problem. Recent advancements in generative AI have demonstrated the impressive capabilities of diffusion models in generating realistic data across various domains. In this work we introduce a Score-based Diffusion Recommendation Module (SDRM), which captures the intricate patterns of real-world datasets required for training highly accurate recommender systems. SDRM allows for the generation of synthetic data that can replace existing datasets to preserve user privacy, or augment existing datasets to address excessive data sparsity. Our method outperforms competing baselines such as generative adversarial networks, variational autoencoders, and recently proposed diffusion models in synthesizing various datasets to replace or augment the original data by an average improvement of 4.30% in Recall@k and 4.65% in NDCG@k.
Create account to get full access
Overview
- Recommender systems are an integral part of the web experience, but they rely heavily on user data, raising privacy and security concerns.
- Synthetic data can address these concerns, but accurately replicating real-world datasets has been challenging.
- Recent advancements in generative AI, like diffusion models, have shown impressive capabilities in generating realistic data.
- This paper introduces the Score-based Diffusion Recommendation Module (SDRM), which can generate synthetic data to replace or augment existing datasets for recommender systems.
Plain English Explanation
Recommender systems are like personal shopping assistants that suggest products or content you might like, based on your past preferences and behaviors. These systems are widely used on websites and apps, but they rely heavily on collecting and analyzing your personal data. This raises concerns about your privacy and the security of your information.
One way to address these concerns is to use synthetic data instead of real user data. Synthetic data is artificial information that is generated to resemble the real-world dataset, but without using any actual user data. However, accurately creating synthetic data that can effectively replace or supplement the original dataset has proven to be a difficult challenge.
Recent advancements in a type of artificial intelligence called "diffusion models" have shown impressive results in generating realistic data across various domains. Building on this, the researchers in this paper developed a new model called the Score-based Diffusion Recommendation Module (SDRM). This model is designed to capture the complex patterns and relationships within real-world datasets used for training recommender systems.
The SDRM allows for the generation of synthetic data that can either replace existing datasets to preserve user privacy, or be used to augment existing datasets to address issues with sparse or incomplete data. The researchers found that their method outperformed other state-of-the-art approaches, such as generative adversarial networks and variational autoencoders, in synthesizing various datasets.
Technical Explanation
The paper introduces the Score-based Diffusion Recommendation Module (SDRM), a new generative model based on the principles of diffusion models. Diffusion models work by gradually adding noise to the data and then learning to reverse the process to generate new, realistic samples.
The SDRM is designed to capture the complex patterns and relationships within real-world datasets used for training recommender systems. This allows the model to generate synthetic data that can either replace the original dataset to preserve user privacy, or be used to augment the existing dataset to address issues with data sparsity.
The researchers evaluate their method on several benchmark datasets and compare it to other state-of-the-art generative models, such as generative adversarial networks (GANs), variational autoencoders (VAEs), and recently proposed diffusion models. The results show that the SDRM outperforms these baselines by an average of 4.30% in Recall@k and 4.65% in NDCG@k, which are standard metrics used to evaluate the quality of recommender systems.
Critical Analysis
The paper presents a promising approach to addressing the privacy and data sparsity issues in recommender systems through the use of synthetic data. The researchers have demonstrated the effectiveness of their Score-based Diffusion Recommendation Module (SDRM) in generating high-quality synthetic data that can replace or augment existing datasets.
However, the paper does not address the potential limitations of using synthetic data in real-world recommender systems. There may be concerns about the generalizability of the synthetic data, as well as the potential for biases or artifacts introduced during the data generation process. Additionally, the paper does not explore the implications of using synthetic data in terms of fairness and algorithmic bias, which are important considerations in the deployment of recommender systems.
Further research is needed to investigate the long-term impact of using synthetic data in recommender systems, including potential issues with differential privacy and the fairness of data generation. Nonetheless, the SDRM represents a promising step towards addressing the privacy and data sparsity challenges in recommender systems.
Conclusion
This paper introduces the Score-based Diffusion Recommendation Module (SDRM), a novel generative model that can effectively generate synthetic data to replace or augment existing datasets used in recommender systems. The SDRM leverages the impressive capabilities of diffusion models to capture the intricate patterns and relationships within real-world datasets, allowing for the creation of high-quality synthetic data.
The researchers have demonstrated that their SDRM outperforms other state-of-the-art generative models in synthesizing various datasets, addressing the privacy and data sparsity concerns that plague traditional recommender systems. While further research is needed to fully understand the long-term implications of using synthetic data, the SDRM represents a significant step forward in the quest to develop recommender systems that respect user privacy and maintain high performance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

RecDiff: Diffusion Model for Social Recommendation
Zongwei Li, Lianghao Xia, Chao Huang
0
0
Social recommendation has emerged as a powerful approach to enhance personalized recommendations by leveraging the social connections among users, such as following and friend relations observed in online social platforms. The fundamental assumption of social recommendation is that socially-connected users exhibit homophily in their preference patterns. This means that users connected by social ties tend to have similar tastes in user-item activities, such as rating and purchasing. However, this assumption is not always valid due to the presence of irrelevant and false social ties, which can contaminate user embeddings and adversely affect recommendation accuracy. To address this challenge, we propose a novel diffusion-based social denoising framework for recommendation (RecDiff). Our approach utilizes a simple yet effective hidden-space diffusion paradigm to alleivate the noisy effect in the compressed and dense representation space. By performing multi-step noise diffusion and removal, RecDiff possesses a robust ability to identify and eliminate noise from the encoded user representations, even when the noise levels vary. The diffusion module is optimized in a downstream task-aware manner, thereby maximizing its ability to enhance the recommendation process. We conducted extensive experiments to evaluate the efficacy of our framework, and the results demonstrate its superiority in terms of recommendation accuracy, training efficiency, and denoising effectiveness. The source code for the model implementation is publicly available at: https://github.com/HKUDS/RecDiff.
6/5/2024

Denoising Diffusion Recommender Model
Jujia Zhao, Wenjie Wang, Yiyan Xu, Teng Sun, Fuli Feng, Tat-Seng Chua
0
0
Recommender systems often grapple with noisy implicit feedback. Most studies alleviate the noise issues from data cleaning perspective such as data resampling and reweighting, but they are constrained by heuristic assumptions. Another denoising avenue is from model perspective, which proactively injects noises into user-item interactions and enhances the intrinsic denoising ability of models. However, this kind of denoising process poses significant challenges to the recommender model's representation capacity to capture noise patterns. To address this issue, we propose Denoising Diffusion Recommender Model (DDRM), which leverages multi-step denoising process of diffusion models to robustify user and item embeddings from any recommender models. DDRM injects controlled Gaussian noises in the forward process and iteratively removes noises in the reverse denoising process, thereby improving embedding robustness against noisy feedback. To achieve this target, the key lies in offering appropriate guidance to steer the reverse denoising process and providing a proper starting point to start the forward-reverse process during inference. In particular, we propose a dedicated denoising module that encodes collaborative information as denoising guidance. Besides, in the inference stage, DDRM utilizes the average embeddings of users' historically liked items as the starting point rather than using pure noise since pure noise lacks personalization, which increases the difficulty of the denoising process. Extensive experiments on three datasets with three representative backend recommender models demonstrate the effectiveness of DDRM.
6/18/2024

Diffusion Models, Image Super-Resolution And Everything: A Survey
Brian B. Moser, Arundhati S. Shanbhag, Federico Raue, Stanislav Frolov, Sebastian Palacio, Andreas Dengel
0
0
Diffusion Models (DMs) have disrupted the image Super-Resolution (SR) field and further closed the gap between image quality and human perceptual preferences. They are easy to train and can produce very high-quality samples that exceed the realism of those produced by previous generative methods. Despite their promising results, they also come with new challenges that need further research: high computational demands, comparability, lack of explainability, color shifts, and more. Unfortunately, entry into this field is overwhelming because of the abundance of publications. To address this, we provide a unified recount of the theoretical foundations underlying DMs applied to image SR and offer a detailed analysis that underscores the unique characteristics and methodologies within this domain, distinct from broader existing reviews in the field. This survey articulates a cohesive understanding of DM principles and explores current research avenues, including alternative input domains, conditioning techniques, guidance mechanisms, corruption spaces, and zero-shot learning approaches. By offering a detailed examination of the evolution and current trends in image SR through the lens of DMs, this survey sheds light on the existing challenges and charts potential future directions, aiming to inspire further innovation in this rapidly advancing area.
6/26/2024
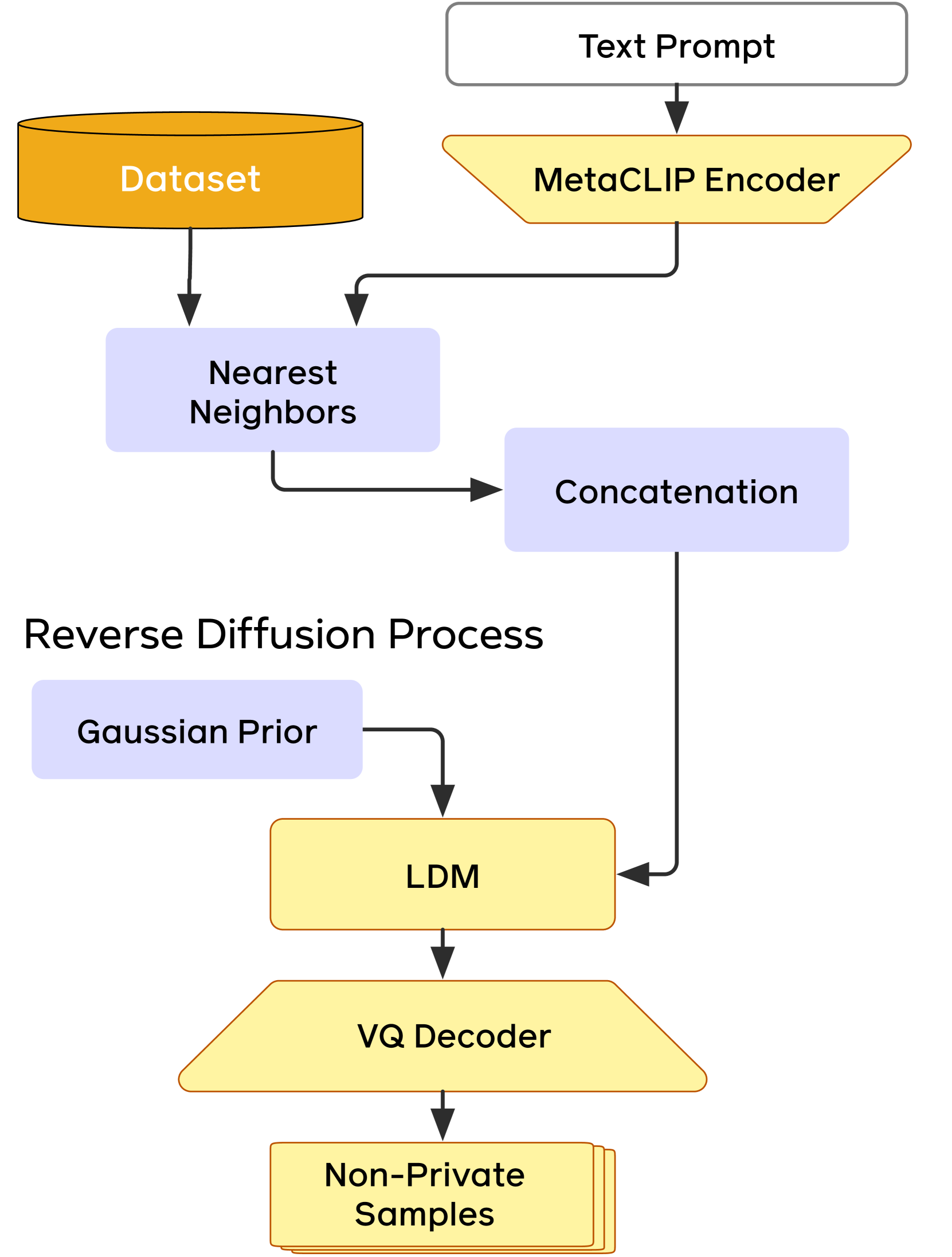
DP-RDM: Adapting Diffusion Models to Private Domains Without Fine-Tuning
Jonathan Lebensold, Maziar Sanjabi, Pietro Astolfi, Adriana Romero-Soriano, Kamalika Chaudhuri, Mike Rabbat, Chuan Guo
0
0
Text-to-image diffusion models have been shown to suffer from sample-level memorization, possibly reproducing near-perfect replica of images that they are trained on, which may be undesirable. To remedy this issue, we develop the first differentially private (DP) retrieval-augmented generation algorithm that is capable of generating high-quality image samples while providing provable privacy guarantees. Specifically, we assume access to a text-to-image diffusion model trained on a small amount of public data, and design a DP retrieval mechanism to augment the text prompt with samples retrieved from a private retrieval dataset. Our emph{differentially private retrieval-augmented diffusion model} (DP-RDM) requires no fine-tuning on the retrieval dataset to adapt to another domain, and can use state-of-the-art generative models to generate high-quality image samples while satisfying rigorous DP guarantees. For instance, when evaluated on MS-COCO, our DP-RDM can generate samples with a privacy budget of $epsilon=10$, while providing a $3.5$ point improvement in FID compared to public-only retrieval for up to $10,000$ queries.
5/14/2024