Fair Data Generation via Score-based Diffusion Model
2406.09495
0
0

Abstract
The fairness of AI decision-making has garnered increasing attention, leading to the proposal of numerous fairness algorithms. In this paper, we aim not to address this issue by directly introducing fair learning algorithms, but rather by generating entirely new, fair synthetic data from biased datasets for use in any downstream tasks. Additionally, the distribution of test data may differ from that of the training set, potentially impacting the performance of the generated synthetic data in downstream tasks. To address these two challenges, we propose a diffusion model-based framework, FADM: Fairness-Aware Diffusion with Meta-training. FADM introduces two types of gradient induction during the sampling phase of the diffusion model: one to ensure that the generated samples belong to the desired target categories, and another to make the sensitive attributes of the generated samples difficult to classify into any specific sensitive attribute category. To overcome data distribution shifts in the test environment, we train the diffusion model and the two classifiers used for induction within a meta-learning framework. Compared to other baselines, FADM allows for flexible control over the categories of the generated samples and exhibits superior generalization capability. Experiments on real datasets demonstrate that FADM achieves better accuracy and optimal fairness in downstream tasks.
Create account to get full access
Overview
- This paper proposes a fairness-aware data generation method using a score-based diffusion model.
- The goal is to generate synthetic data that maintains statistical parity between different demographic groups, while preserving the original data distribution.
- The authors introduce a novel "domain shift" technique to encourage the model to generate fair data, and demonstrate its effectiveness on several benchmark datasets.
Plain English Explanation
The paper discusses a way to generate new data that is fair and balanced, while still capturing the key characteristics of the original dataset. The researchers use a type of machine learning model called a "score-based diffusion model" to create this synthetic data.
The key innovation is a technique they call "domain shift," which helps ensure the generated data is statistically similar across different demographic groups, like gender or race. This is important because many machine learning models can pick up on and amplify biases present in real-world data. By generating fair synthetic data, the researchers aim to create a level playing field for training more equitable AI systems.
This builds on prior work on using diffusion models for data generation and fairness-aware learning.
Overall, the goal is to develop methods that can produce diverse, representative data while mitigating problematic biases - a crucial step towards building fairer and more inclusive AI technologies. This relates to other recent research on using diffusion for deepfake detection, dataset generation for downstream tasks, tabular data synthesis, and distribution-aware data expansion.
Technical Explanation
The authors propose a fairness-aware data generation method based on a score-based diffusion model. Diffusion models are a type of generative AI that learn to gradually transform noise into realistic-looking samples by modeling the "reverse" diffusion process.
To encourage fairness, the researchers introduce a "domain shift" technique that applies a fairness penalty during training. This incentivizes the model to generate samples that maintain statistical parity between different demographic groups, while still matching the overall data distribution.
Experiments on several benchmark datasets show this approach can produce fair synthetic data that closely matches the original data characteristics. The authors analyze the trade-offs between fairness, sample quality, and diversity, and discuss potential limitations and future research directions.
Critical Analysis
The paper presents a novel and promising approach for generating fair synthetic data using diffusion models. The domain shift technique is a clever way to incorporate fairness considerations directly into the generative process.
That said, the authors acknowledge several caveats and limitations. For example, the fairness metric used may not fully capture all nuances of bias, and the approach relies on having access to demographic labels in the training data. There are also open questions around scalability to high-dimensional or tabular data.
Additionally, while the experiments demonstrate the viability of the approach, more work is needed to fully characterize its real-world performance and robustness. Potential edge cases or unintended consequences should be carefully explored.
Overall, this research represents an important step towards developing fairness-aware generative models. However, continued scrutiny and further advancements will be crucial as these techniques are applied to sensitive domains. Readers are encouraged to think critically about the societal implications and potential pitfalls of such data generation methods.
Conclusion
This paper introduces a novel fairness-aware data generation approach based on score-based diffusion models. By incorporating a "domain shift" technique, the model is able to produce synthetic data that maintains statistical parity between demographic groups, while still preserving the overall characteristics of the original dataset.
The results demonstrate the potential of this method to support the development of fairer AI systems, by providing diverse and representative training data that mitigates problematic biases. As the use of generative models becomes more widespread, techniques like this will be increasingly important for ensuring the responsible and equitable deployment of these powerful technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Balancing Act: Distribution-Guided Debiasing in Diffusion Models
Rishubh Parihar, Abhijnya Bhat, Abhipsa Basu, Saswat Mallick, Jogendra Nath Kundu, R. Venkatesh Babu
0
0
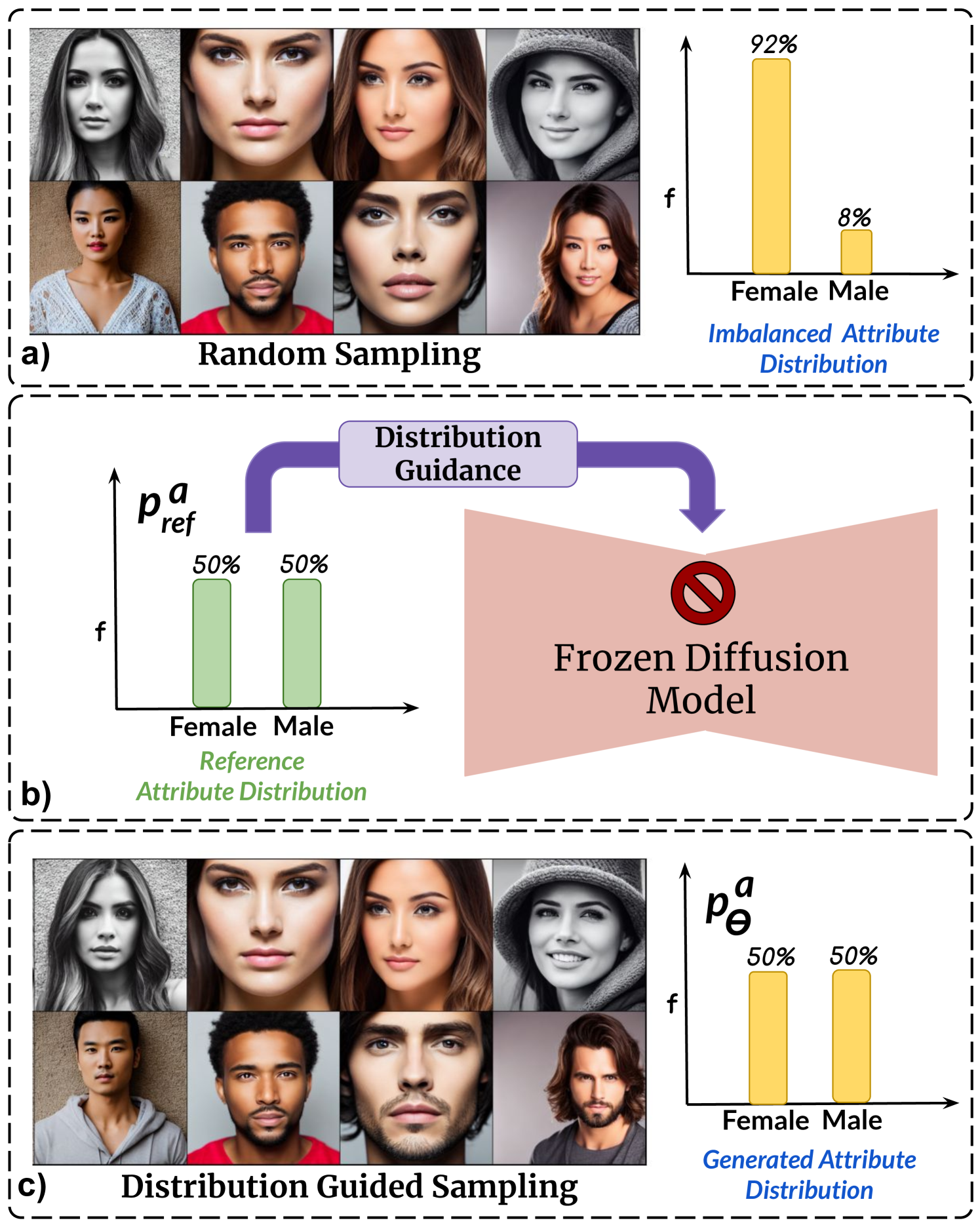
Diffusion Models (DMs) have emerged as powerful generative models with unprecedented image generation capability. These models are widely used for data augmentation and creative applications. However, DMs reflect the biases present in the training datasets. This is especially concerning in the context of faces, where the DM prefers one demographic subgroup vs others (eg. female vs male). In this work, we present a method for debiasing DMs without relying on additional data or model retraining. Specifically, we propose Distribution Guidance, which enforces the generated images to follow the prescribed attribute distribution. To realize this, we build on the key insight that the latent features of denoising UNet hold rich demographic semantics, and the same can be leveraged to guide debiased generation. We train Attribute Distribution Predictor (ADP) - a small mlp that maps the latent features to the distribution of attributes. ADP is trained with pseudo labels generated from existing attribute classifiers. The proposed Distribution Guidance with ADP enables us to do fair generation. Our method reduces bias across single/multiple attributes and outperforms the baseline by a significant margin for unconditional and text-conditional diffusion models. Further, we present a downstream task of training a fair attribute classifier by rebalancing the training set with our generated data.
5/30/2024

Deceptive Diffusion: Generating Synthetic Adversarial Examples
Lucas Beerens, Catherine F. Higham, Desmond J. Higham
0
0
We introduce the concept of deceptive diffusion -- training a generative AI model to produce adversarial images. Whereas a traditional adversarial attack algorithm aims to perturb an existing image to induce a misclassificaton, the deceptive diffusion model can create an arbitrary number of new, misclassified images that are not directly associated with training or test images. Deceptive diffusion offers the possibility of strengthening defence algorithms by providing adversarial training data at scale, including types of misclassification that are otherwise difficult to find. In our experiments, we also investigate the effect of training on a partially attacked data set. This highlights a new type of vulnerability for generative diffusion models: if an attacker is able to stealthily poison a portion of the training data, then the resulting diffusion model will generate a similar proportion of misleading outputs.
7/1/2024
🔄
Diffusion Deepfake
Chaitali Bhattacharyya, Hanxiao Wang, Feng Zhang, Sungho Kim, Xiatian Zhu
0
0
Recent progress in generative AI, primarily through diffusion models, presents significant challenges for real-world deepfake detection. The increased realism in image details, diverse content, and widespread accessibility to the general public complicates the identification of these sophisticated deepfakes. Acknowledging the urgency to address the vulnerability of current deepfake detectors to this evolving threat, our paper introduces two extensive deepfake datasets generated by state-of-the-art diffusion models as other datasets are less diverse and low in quality. Our extensive experiments also showed that our dataset is more challenging compared to the other face deepfake datasets. Our strategic dataset creation not only challenge the deepfake detectors but also sets a new benchmark for more evaluation. Our comprehensive evaluation reveals the struggle of existing detection methods, often optimized for specific image domains and manipulations, to effectively adapt to the intricate nature of diffusion deepfakes, limiting their practical utility. To address this critical issue, we investigate the impact of enhancing training data diversity on representative detection methods. This involves expanding the diversity of both manipulation techniques and image domains. Our findings underscore that increasing training data diversity results in improved generalizability. Moreover, we propose a novel momentum difficulty boosting strategy to tackle the additional challenge posed by training data heterogeneity. This strategy dynamically assigns appropriate sample weights based on learning difficulty, enhancing the model's adaptability to both easy and challenging samples. Extensive experiments on both existing and newly proposed benchmarks demonstrate that our model optimization approach surpasses prior alternatives significantly.
4/3/2024
Stable Diffusion Dataset Generation for Downstream Classification Tasks
Eugenio Lomurno, Matteo D'Oria, Matteo Matteucci
0
0
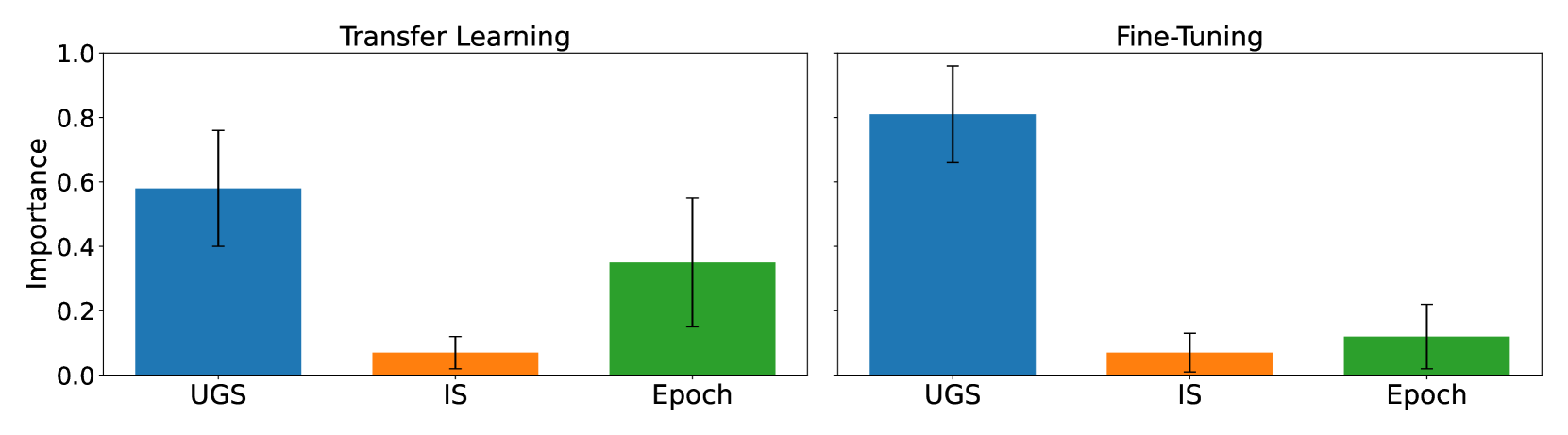
Recent advances in generative artificial intelligence have enabled the creation of high-quality synthetic data that closely mimics real-world data. This paper explores the adaptation of the Stable Diffusion 2.0 model for generating synthetic datasets, using Transfer Learning, Fine-Tuning and generation parameter optimisation techniques to improve the utility of the dataset for downstream classification tasks. We present a class-conditional version of the model that exploits a Class-Encoder and optimisation of key generation parameters. Our methodology led to synthetic datasets that, in a third of cases, produced models that outperformed those trained on real datasets.
5/7/2024