Multi-scale Attention Network for Single Image Super-Resolution
2209.14145
0
0
🌐
Abstract
ConvNets can compete with transformers in high-level tasks by exploiting larger receptive fields. To unleash the potential of ConvNet in super-resolution, we propose a multi-scale attention network (MAN), by coupling classical multi-scale mechanism with emerging large kernel attention. In particular, we proposed multi-scale large kernel attention (MLKA) and gated spatial attention unit (GSAU). Through our MLKA, we modify large kernel attention with multi-scale and gate schemes to obtain the abundant attention map at various granularity levels, thereby aggregating global and local information and avoiding potential blocking artifacts. In GSAU, we integrate gate mechanism and spatial attention to remove the unnecessary linear layer and aggregate informative spatial context. To confirm the effectiveness of our designs, we evaluate MAN with multiple complexities by simply stacking different numbers of MLKA and GSAU. Experimental results illustrate that our MAN can perform on par with SwinIR and achieve varied trade-offs between state-of-the-art performance and computations.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Convolutional neural networks (ConvNets) can compete with transformers in high-level tasks by leveraging larger receptive fields.
- To unlock the potential of ConvNets for super-resolution, the authors propose a multi-scale attention network (MAN).
- MAN combines classical multi-scale mechanisms with large kernel attention to capture global and local information effectively.
- Key components of MAN include multi-scale large kernel attention (MLKA) and a gated spatial attention unit (GSAU).
Plain English Explanation
The paper explores how convolutional neural networks (ConvNets) can compete with transformer models in high-level tasks. The key insight is that ConvNets can leverage their larger receptive fields to their advantage.
To harness the power of ConvNets for the task of super-resolution, the authors introduce a new model called the multi-scale attention network (MAN). MAN combines two key ideas: the classic multi-scale approach and the more recent large kernel attention mechanism.
The multi-scale aspect allows MAN to capture information at different levels of granularity, from global to local. The large kernel attention helps MAN aggregate this information effectively, avoiding potential blocking artifacts that can occur with traditional approaches.
MAN incorporates two novel components to achieve this. The first is multi-scale large kernel attention (MLKA), which modifies the large kernel attention with multi-scale and gating schemes. This allows MLKA to generate abundant attention maps at various levels of detail, enabling it to combine global and local information.
The second component is the gated spatial attention unit (GSAU), which integrates a gating mechanism and spatial attention. This helps GSAU remove unnecessary linear layers and better aggregate informative spatial context.
By stacking different numbers of MLKA and GSAU units, the authors can create MAN models with varying complexities, allowing for a range of performance and computational trade-offs. The experimental results show that MAN can perform on par with state-of-the-art models like SwinIR while offering flexible performance-cost options.
Technical Explanation
The key innovation of this work is the multi-scale attention network (MAN), which aims to leverage the strengths of ConvNets to compete with transformers in high-level tasks. The authors observe that ConvNets can exploit their larger receptive fields to their advantage, and they propose MAN to unleash the potential of ConvNets for the task of super-resolution.
MAN combines classical multi-scale mechanisms with the emerging large kernel attention approach. Specifically, the authors introduce two novel components:
-
Multi-scale Large Kernel Attention (MLKA): This module modifies the large kernel attention with multi-scale and gating schemes. This allows MLKA to generate abundant attention maps at various levels of granularity, enabling it to aggregate both global and local information while avoiding potential blocking artifacts.
-
Gated Spatial Attention Unit (GSAU): This unit integrates a gating mechanism and spatial attention to remove unnecessary linear layers and better aggregate informative spatial context.
By stacking different numbers of MLKA and GSAU units, the authors can create MAN models with varying complexities, allowing for a range of performance and computational trade-offs. The experimental results demonstrate that MAN can perform on par with state-of-the-art models like SwinIR and ESPCN while offering flexible performance-cost options.
Critical Analysis
The paper presents a well-designed approach to leveraging the strengths of ConvNets for high-level tasks, particularly in the domain of super-resolution. The authors' insights on exploiting larger receptive fields and combining multi-scale mechanisms with large kernel attention are compelling.
However, the paper does not address some potential limitations or areas for further research. For example, it would be interesting to understand how MAN compares to other recent transformer-based or hybrid approaches for super-resolution. Additionally, the paper could have explored the generalization of MAN to other high-level tasks beyond super-resolution.
Nevertheless, the authors have presented a novel and promising approach that demonstrates the potential of ConvNets to compete with transformers in complex computer vision tasks. Further research and refinement of MAN could lead to even more efficient and effective solutions for high-level vision problems.
Conclusion
This paper introduces the multi-scale attention network (MAN), a novel ConvNet-based architecture that can compete with transformer models in high-level tasks by leveraging larger receptive fields. MAN combines classical multi-scale mechanisms with large kernel attention to capture global and local information effectively, as demonstrated by its strong performance in super-resolution tasks.
The key innovations of MAN are the multi-scale large kernel attention (MLKA) module and the gated spatial attention unit (GSAU), which work together to enable flexible performance-cost trade-offs. By stacking these components, the authors can create MAN models with varying complexities to suit different application requirements.
The results show that MAN can achieve state-of-the-art performance in super-resolution while offering a range of computational budgets, highlighting the potential of ConvNets to excel in high-level computer vision tasks. This work contributes to the ongoing exploration of efficient and effective neural network architectures for complex visual understanding problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌐
Large coordinate kernel attention network for lightweight image super-resolution
Fangwei Hao, Jiesheng Wu, Haotian Lu, Ji Du, Jing Xu
0
0
The multi-scale receptive field and large kernel attention (LKA) module have been shown to significantly improve performance in the lightweight image super-resolution task. However, existing lightweight super-resolution (SR) methods seldom pay attention to designing efficient building block with multi-scale receptive field for local modeling, and their LKA modules face a quadratic increase in computational and memory footprints as the convolutional kernel size increases. To address the first issue, we propose the multi-scale blueprint separable convolutions (MBSConv) as highly efficient building block with multi-scale receptive field, it can focus on the learning for the multi-scale information which is a vital component of discriminative representation. As for the second issue, we revisit the key properties of LKA in which we find that the adjacent direct interaction of local information and long-distance dependencies is crucial to provide remarkable performance. Thus, taking this into account and in order to mitigate the complexity of LKA, we propose a large coordinate kernel attention (LCKA) module which decomposes the 2D convolutional kernels of the depth-wise convolutional layers in LKA into horizontal and vertical 1-D kernels. LCKA enables the adjacent direct interaction of local information and long-distance dependencies not only in the horizontal direction but also in the vertical. Besides, LCKA allows for the direct use of extremely large kernels in the depth-wise convolutional layers to capture more contextual information, which helps to significantly improve the reconstruction performance, and it incurs lower computational complexity and memory footprints. Integrating MBSConv and LCKA, we propose a large coordinate kernel attention network (LCAN).
5/16/2024
🌐
HMANet: Hybrid Multi-Axis Aggregation Network for Image Super-Resolution
Shu-Chuan Chu, Zhi-Chao Dou, Jeng-Shyang Pan, Shaowei Weng, Junbao Li
0
0
Transformer-based methods have demonstrated excellent performance on super-resolution visual tasks, surpassing conventional convolutional neural networks. However, existing work typically restricts self-attention computation to non-overlapping windows to save computational costs. This means that Transformer-based networks can only use input information from a limited spatial range. Therefore, a novel Hybrid Multi-Axis Aggregation network (HMA) is proposed in this paper to exploit feature potential information better. HMA is constructed by stacking Residual Hybrid Transformer Blocks(RHTB) and Grid Attention Blocks(GAB). On the one side, RHTB combines channel attention and self-attention to enhance non-local feature fusion and produce more attractive visual results. Conversely, GAB is used in cross-domain information interaction to jointly model similar features and obtain a larger perceptual field. For the super-resolution task in the training phase, a novel pre-training method is designed to enhance the model representation capabilities further and validate the proposed model's effectiveness through many experiments. The experimental results show that HMA outperforms the state-of-the-art methods on the benchmark dataset. We provide code and models at https://github.com/korouuuuu/HMA.
5/9/2024
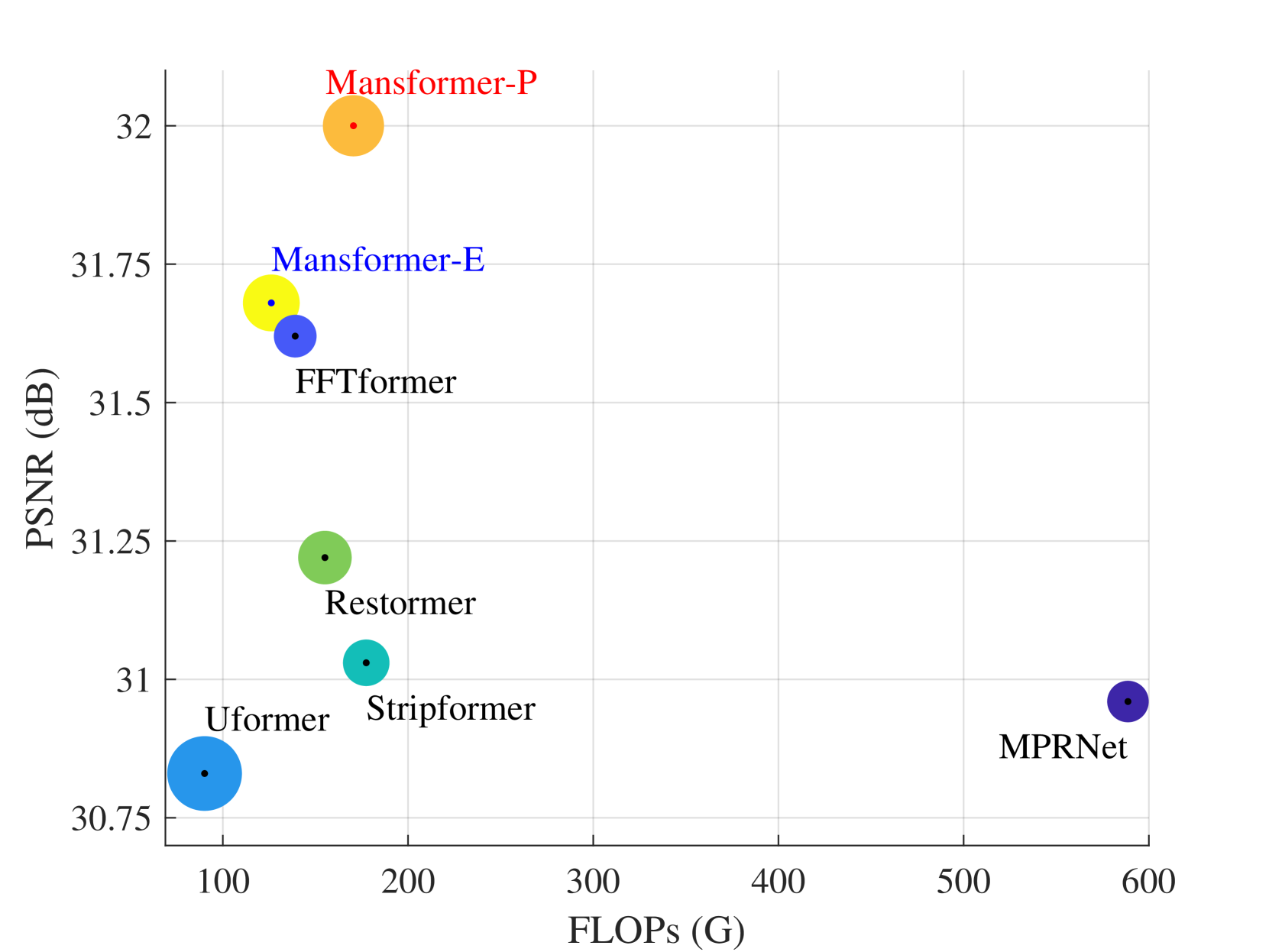
Mansformer: Efficient Transformer of Mixed Attention for Image Deblurring and Beyond
Pin-Hung Kuo, Jinshan Pan, Shao-Yi Chien, Ming-Hsuan Yang
0
0
Transformer has made an enormous success in natural language processing and high-level vision over the past few years. However, the complexity of self-attention is quadratic to the image size, which makes it infeasible for high-resolution vision tasks. In this paper, we propose the Mansformer, a Transformer of mixed attention that combines multiple self-attentions, gate, and multi-layer perceptions (MLPs), to explore and employ more possibilities of self-attention. Taking efficiency into account, we design four kinds of self-attention, whose complexities are all linear. By elaborate adjustment of the tensor shapes and dimensions for the dot product, we split the typical self-attention of quadratic complexity into four operations of linear complexity. To adaptively merge these different kinds of self-attention, we take advantage of an architecture similar to Squeeze-and-Excitation Networks. Furthermore, we make it to merge the two-staged Transformer design into one stage by the proposed gated-dconv MLP. Image deblurring is our main target, while extensive quantitative and qualitative evaluations show that this method performs favorably against the state-of-the-art methods far more than simply deblurring. The source codes and trained models will be made available to the public.
4/10/2024
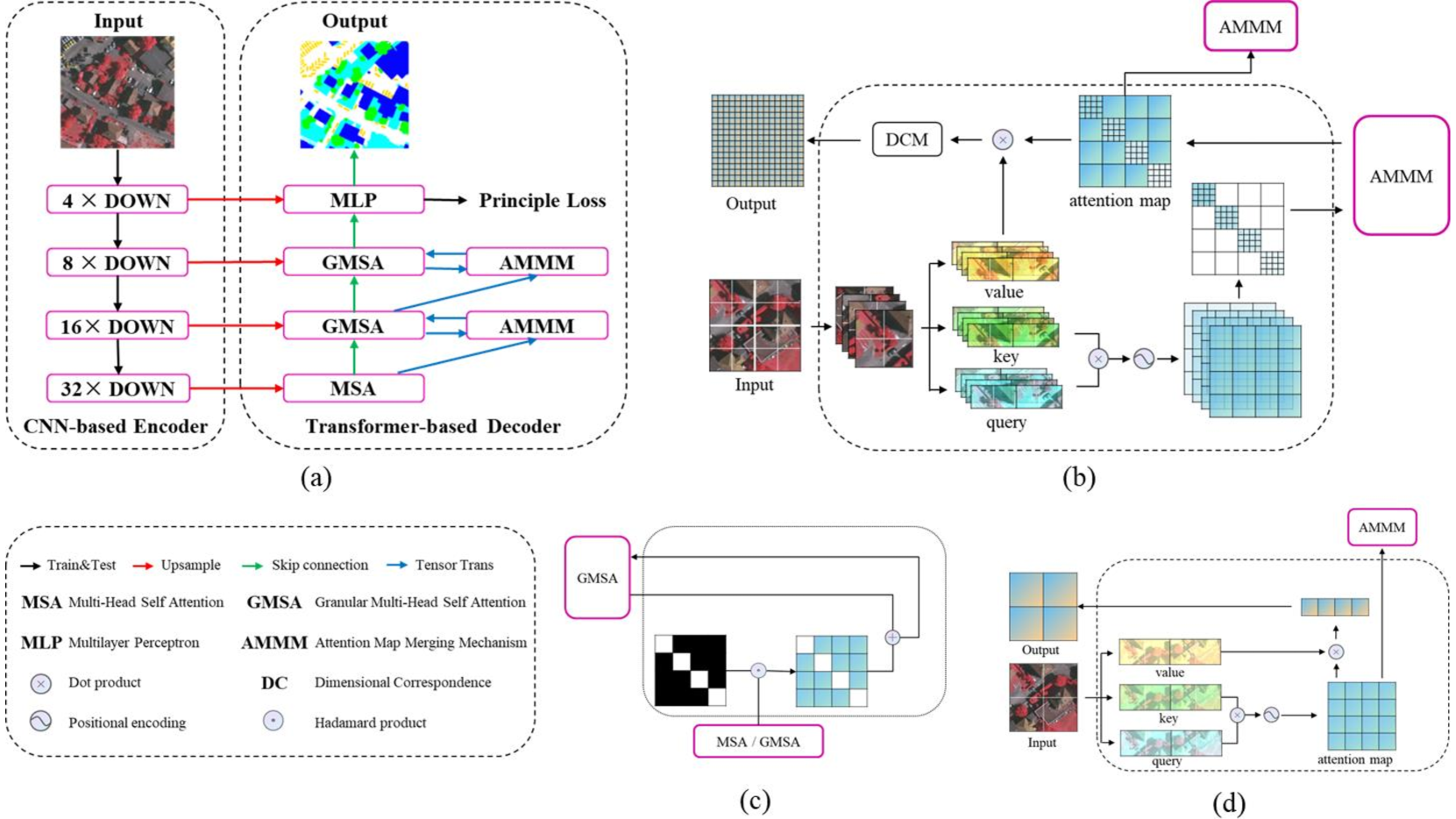
AMMUNet: Multi-Scale Attention Map Merging for Remote Sensing Image Segmentation
Yang Yang, Shunyi Zheng
0
0
The advancement of deep learning has driven notable progress in remote sensing semantic segmentation. Attention mechanisms, while enabling global modeling and utilizing contextual information, face challenges of high computational costs and require window-based operations that weaken capturing long-range dependencies, hindering their effectiveness for remote sensing image processing. In this letter, we propose AMMUNet, a UNet-based framework that employs multi-scale attention map merging, comprising two key innovations: the granular multi-head self-attention (GMSA) module and the attention map merging mechanism (AMMM). GMSA efficiently acquires global information while substantially mitigating computational costs in contrast to global multi-head self-attention mechanism. This is accomplished through the strategic utilization of dimension correspondence to align granularity and the reduction of relative position bias parameters, thereby optimizing computational efficiency. The proposed AMMM effectively combines multi-scale attention maps into a unified representation using a fixed mask template, enabling the modeling of global attention mechanism. Experimental evaluations highlight the superior performance of our approach, achieving remarkable mean intersection over union (mIoU) scores of 75.48% on the challenging Vaihingen dataset and an exceptional 77.90% on the Potsdam dataset, demonstrating the superiority of our method in precise remote sensing semantic segmentation. Codes are available at https://github.com/interpretty/AMMUNet.
4/23/2024