Mansformer: Efficient Transformer of Mixed Attention for Image Deblurring and Beyond
2404.06135
0
1
Abstract
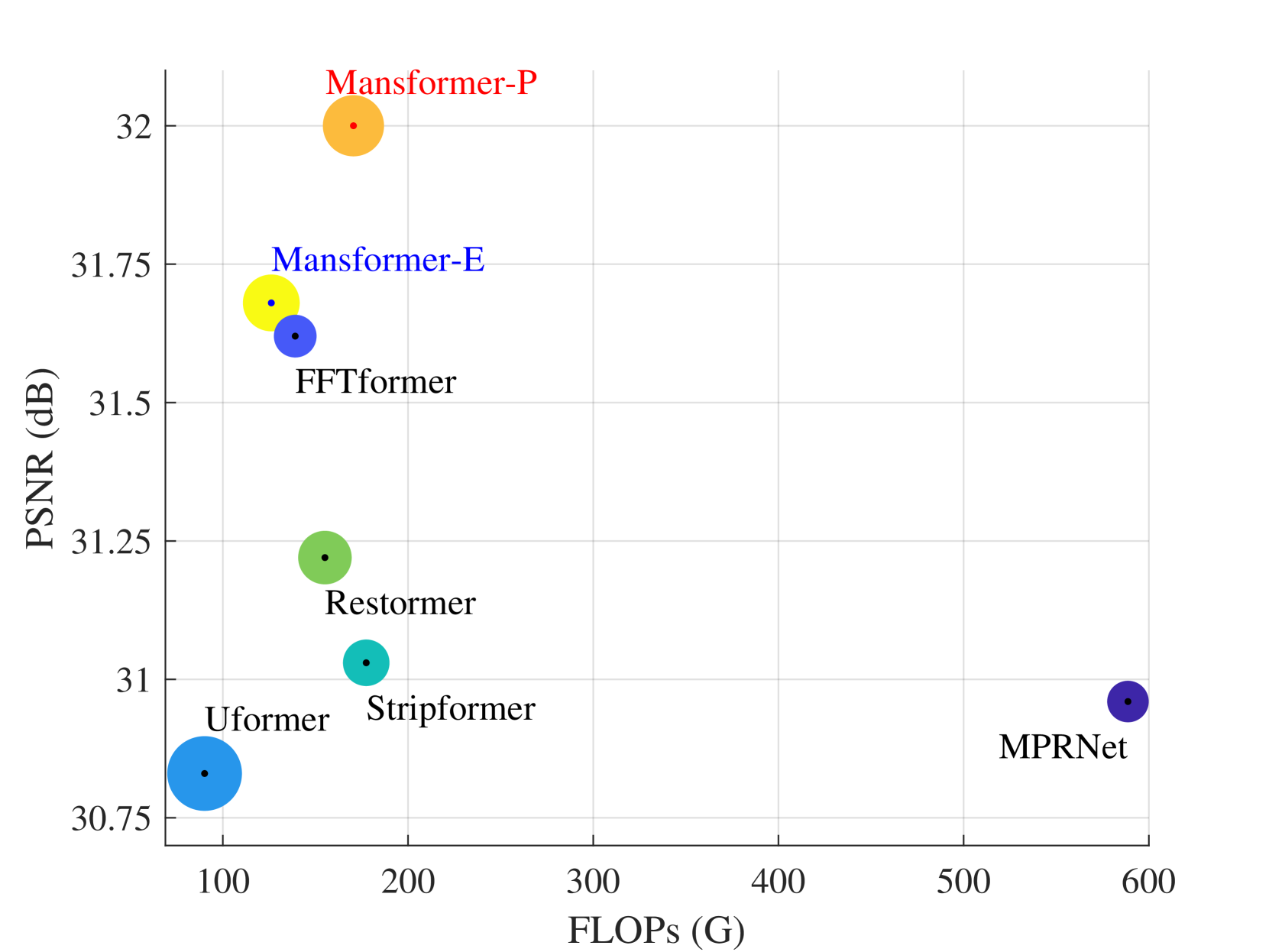
Transformer has made an enormous success in natural language processing and high-level vision over the past few years. However, the complexity of self-attention is quadratic to the image size, which makes it infeasible for high-resolution vision tasks. In this paper, we propose the Mansformer, a Transformer of mixed attention that combines multiple self-attentions, gate, and multi-layer perceptions (MLPs), to explore and employ more possibilities of self-attention. Taking efficiency into account, we design four kinds of self-attention, whose complexities are all linear. By elaborate adjustment of the tensor shapes and dimensions for the dot product, we split the typical self-attention of quadratic complexity into four operations of linear complexity. To adaptively merge these different kinds of self-attention, we take advantage of an architecture similar to Squeeze-and-Excitation Networks. Furthermore, we make it to merge the two-staged Transformer design into one stage by the proposed gated-dconv MLP. Image deblurring is our main target, while extensive quantitative and qualitative evaluations show that this method performs favorably against the state-of-the-art methods far more than simply deblurring. The source codes and trained models will be made available to the public.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper introduces Mansformer, an efficient transformer model for image deblurring and other tasks.
- It combines multiple attention mechanisms, including mixed attention and multi-axis attention, to improve performance and efficiency.
- The model is evaluated on image deblurring and other vision tasks, demonstrating state-of-the-art results.
Plain English Explanation
The Mansformer model is a type of transformer that is designed to be more efficient and effective for image-related tasks like deblurring. Transformers are a popular type of neural network that have shown great success in various domains, including computer vision.
One of the key innovations of Mansformer is its use of "mixed attention" and "multi-axis attention". These attention mechanisms allow the model to focus on different parts of the image in a more targeted and efficient way, compared to standard transformers. This helps the model better understand the content and structure of the image, leading to improved performance on tasks like deblurring.
The paper demonstrates that Mansformer outperforms other state-of-the-art models on image deblurring and other vision tasks, while also being more efficient in terms of computational resources. This makes it a promising approach for real-world applications that require fast and accurate image processing, such as medical image analysis or computational photography.
Technical Explanation
The Mansformer architecture combines several key innovations to improve the efficiency and effectiveness of transformer models for image-related tasks:
-
Mixed Attention: Mansformer uses a combination of local attention and global attention, which allows the model to capture both fine-grained details and global context in the image. This mixed attention mechanism has been shown to be more effective than using a single attention type.
-
Multi-Axis Attention: In addition to mixed attention, Mansformer also employs "multi-axis attention", which computes attention along multiple spatial dimensions (e.g., height, width, and depth) to better capture the 3D structure of the image.
-
Efficient Transformer Design: The paper also explores various design techniques to improve the efficiency of the transformer model, such as using a smaller number of attention heads and layers.
The Mansformer model is evaluated on a range of image-related tasks, including image deblurring, image super-resolution, and medical image segmentation. The results show that Mansformer outperforms other state-of-the-art models while being more efficient in terms of computational resources and training time.
Critical Analysis
The paper presents a thorough evaluation of the Mansformer model, including comparisons to other leading approaches. However, there are a few potential limitations and areas for further research:
-
Generalization to Other Tasks: While the model demonstrates strong performance on the evaluated tasks, it's unclear how well it would generalize to a broader range of image-related problems. Further testing on a more diverse set of benchmarks would help validate the model's versatility.
-
Interpretability: As with many deep learning models, the internal workings of Mansformer may be difficult to interpret, making it challenging to understand the specific mechanisms behind its improved performance. Incorporating interpretability techniques could help provide more insights into the model's decision-making process.
-
Real-World Deployment: The paper focuses on evaluating the model's performance on standard benchmarks, but there may be additional challenges in deploying Mansformer in real-world applications, such as handling diverse image data, dealing with hardware constraints, or integrating with other system components. Further research on these practical deployment considerations would be valuable.
Overall, the Mansformer paper presents a promising approach to improving the efficiency and effectiveness of transformer models for image-related tasks. The combination of mixed attention and multi-axis attention mechanisms, along with the efficient design choices, makes it an interesting contribution to the field of computer vision.
Conclusion
The Mansformer model introduced in this paper represents a significant advancement in the field of image-related transformer architectures. By combining multiple attention mechanisms, including mixed attention and multi-axis attention, the model demonstrates state-of-the-art performance on tasks like image deblurring while being more efficient than previous approaches.
The paper's findings suggest that Mansformer could be a valuable tool for a wide range of applications, from computational photography to medical image analysis. As the field of computer vision continues to evolve, the innovations presented in this research could pave the way for more efficient and effective transformer-based models that can tackle complex visual processing challenges.
Related Papers
🌐
Multi-scale Attention Network for Single Image Super-Resolution
Yan Wang, Yusen Li, Gang Wang, Xiaoguang Liu
0
0
ConvNets can compete with transformers in high-level tasks by exploiting larger receptive fields. To unleash the potential of ConvNet in super-resolution, we propose a multi-scale attention network (MAN), by coupling classical multi-scale mechanism with emerging large kernel attention. In particular, we proposed multi-scale large kernel attention (MLKA) and gated spatial attention unit (GSAU). Through our MLKA, we modify large kernel attention with multi-scale and gate schemes to obtain the abundant attention map at various granularity levels, thereby aggregating global and local information and avoiding potential blocking artifacts. In GSAU, we integrate gate mechanism and spatial attention to remove the unnecessary linear layer and aggregate informative spatial context. To confirm the effectiveness of our designs, we evaluate MAN with multiple complexities by simply stacking different numbers of MLKA and GSAU. Experimental results illustrate that our MAN can perform on par with SwinIR and achieve varied trade-offs between state-of-the-art performance and computations.
4/16/2024
MLP Can Be A Good Transformer Learner
Sihao Lin, Pumeng Lyu, Dongrui Liu, Tao Tang, Xiaodan Liang, Andy Song, Xiaojun Chang
0
0
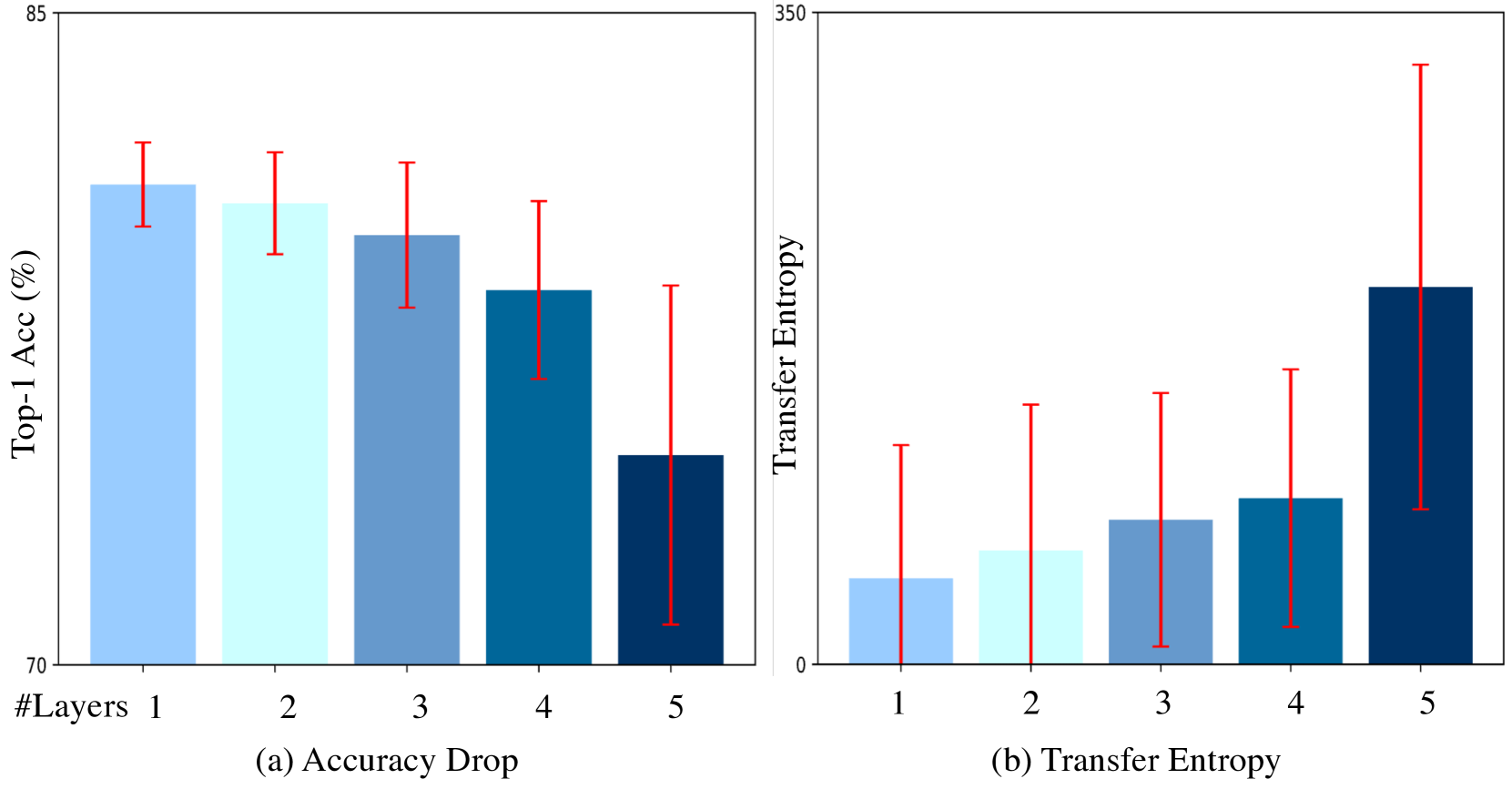
Self-attention mechanism is the key of the Transformer but often criticized for its computation demands. Previous token pruning works motivate their methods from the view of computation redundancy but still need to load the full network and require same memory costs. This paper introduces a novel strategy that simplifies vision transformers and reduces computational load through the selective removal of non-essential attention layers, guided by entropy considerations. We identify that regarding the attention layer in bottom blocks, their subsequent MLP layers, i.e. two feed-forward layers, can elicit the same entropy quantity. Meanwhile, the accompanied MLPs are under-exploited since they exhibit smaller feature entropy compared to those MLPs in the top blocks. Therefore, we propose to integrate the uninformative attention layers into their subsequent counterparts by degenerating them into identical mapping, yielding only MLP in certain transformer blocks. Experimental results on ImageNet-1k show that the proposed method can remove 40% attention layer of DeiT-B, improving throughput and memory bound without performance compromise. Code is available at https://github.com/sihaoevery/lambda_vit.
4/9/2024
NiNformer: A Network in Network Transformer with Token Mixing Generated Gating Function
Abdullah Nazhat Abdullah, Tarkan Aydin
0
0
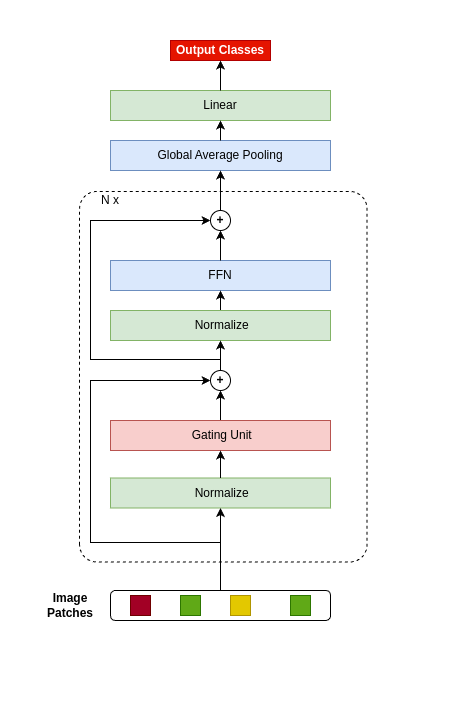
The Attention mechanism is the main component of the Transformer architecture, and since its introduction, it has led to significant advancements in Deep Learning that span many domains and multiple tasks. The Attention Mechanism was utilized in Computer Vision as the Vision Transformer ViT, and its usage has expanded into many tasks in the vision domain, such as classification, segmentation, object detection, and image generation. While this mechanism is very expressive and capable, it comes with the drawback of being computationally expensive and requiring datasets of considerable size for effective optimization. To address these shortcomings, many designs have been proposed in the literature to reduce the computational burden and alleviate the data size requirements. Examples of such attempts in the vision domain are the MLP-Mixer, the Conv-Mixer, the Perciver-IO, and many more. This paper introduces a new computational block as an alternative to the standard ViT block that reduces the compute burdens by replacing the normal Attention layers with a Network in Network structure that enhances the static approach of the MLP Mixer with a dynamic system of learning an element-wise gating function by a token mixing process. Extensive experimentation shows that the proposed design provides better performance than the baseline architectures on multiple datasets applied in the image classification task of the vision domain.
4/26/2024
👨🏫
Transformer-Aided Semantic Communications
Matin Mortaheb, Erciyes Karakaya, Mohammad A. Amir Khojastepour, Sennur Ulukus
0
0
The transformer structure employed in large language models (LLMs), as a specialized category of deep neural networks (DNNs) featuring attention mechanisms, stands out for their ability to identify and highlight the most relevant aspects of input data. Such a capability is particularly beneficial in addressing a variety of communication challenges, notably in the realm of semantic communication where proper encoding of the relevant data is critical especially in systems with limited bandwidth. In this work, we employ vision transformers specifically for the purpose of compression and compact representation of the input image, with the goal of preserving semantic information throughout the transmission process. Through the use of the attention mechanism inherent in transformers, we create an attention mask. This mask effectively prioritizes critical segments of images for transmission, ensuring that the reconstruction phase focuses on key objects highlighted by the mask. Our methodology significantly improves the quality of semantic communication and optimizes bandwidth usage by encoding different parts of the data in accordance with their semantic information content, thus enhancing overall efficiency. We evaluate the effectiveness of our proposed framework using the TinyImageNet dataset, focusing on both reconstruction quality and accuracy. Our evaluation results demonstrate that our framework successfully preserves semantic information, even when only a fraction of the encoded data is transmitted, according to the intended compression rates.
5/3/2024