Multi-scale Bottleneck Transformer for Weakly Supervised Multimodal Violence Detection

0
👨🏫
Sign in to get full access
Overview
- Weakly supervised multimodal violence detection leverages multiple data sources (RGB, optical flow, audio) to learn a violence detection model, with only video-level annotations available.
- Key challenges include information redundancy, modality imbalance, and modality asynchrony.
- This paper proposes a new weakly supervised multimodal violence detection method that addresses these challenges.
Plain English Explanation
This research aims to develop a system that can detect violence in videos, using information from multiple sources like visual, motion, and audio data. The challenge is that the training data only provides information about whether a whole video contains violence or not, without specifying which parts of the video are violent.
To address this, the researchers propose a new technique that explicitly handles three key issues: information redundancy, modality imbalance, and modality asynchrony.
Information redundancy refers to the fact that the different data sources (e.g., RGB, optical flow, audio) may contain overlapping information, which can make the model inefficient. Modality imbalance means that some data sources may be more informative for violence detection than others, so the model needs to focus on the most relevant information. Modality asynchrony arises because the different data sources may not be perfectly synchronized in time, which can confuse the model.
The proposed technique, called multi-scale bottleneck transformer (MSBT) fusion, addresses these challenges by gradually condensing the information from the different data sources and using a weighting scheme to highlight the most important fused features. Additionally, a temporal consistency contrast loss is used to align the fused features in time.
The researchers evaluated their method on a large dataset of violent videos and showed that it outperforms state-of-the-art approaches. This work contributes to the development of more robust and trustworthy multimodal fusion systems for various applications, such as emotion recognition and anomaly detection.
Technical Explanation
The proposed method, called Multi-Scale Bottleneck Transformer (MSBT) fusion, addresses the key challenges of multimodal violence detection:
-
Information Redundancy: The MSBT fusion module employs a reduced number of "bottleneck tokens" to gradually condense information and fuse each pair of modalities. This helps eliminate redundant information and extract the most relevant features.
-
Modality Imbalance: The MSBT fusion module uses a bottleneck token-based weighting scheme to highlight the more important fused features, allowing the model to focus on the most informative data sources for violence detection.
-
Modality Asynchrony: The researchers introduce a temporal consistency contrast loss to semantically align the pairwise fused features, addressing the issue of imperfect synchronization between the different data sources.
Experiments on the XD-Violence dataset, the largest publicly available dataset for multimodal violence detection, demonstrate that the proposed MSBT fusion method achieves state-of-the-art performance, outperforming existing approaches.
Critical Analysis
The paper provides a comprehensive and well-designed solution to the key challenges in weakly supervised multimodal violence detection. The MSBT fusion module and the temporal consistency contrast loss effectively address the issues of information redundancy, modality imbalance, and modality asynchrony.
However, the paper does not discuss the potential limitations of the proposed method. For example, it would be valuable to understand how the method performs with different types of violence or in more diverse real-world scenarios. Additionally, the paper does not explore the computational complexity or the runtime efficiency of the MSBT fusion module, which could be important considerations for practical deployment.
Furthermore, the paper could have benefited from a more thorough discussion of the ethical implications of violence detection systems, such as potential biases, privacy concerns, and the responsible use of such technologies. As these systems become more advanced, it is crucial to consider their societal impact and ensure they are developed and deployed ethically.
Conclusion
This research presents a novel weakly supervised multimodal violence detection method that significantly advances the state-of-the-art by addressing key challenges in information redundancy, modality imbalance, and modality asynchrony. The proposed MSBT fusion module and temporal consistency contrast loss demonstrate impressive performance on a large-scale dataset, highlighting the potential of this approach for practical applications.
As the field of multimodal fusion continues to evolve, this work contributes valuable insights and techniques that can inspire further research towards more robust, trustworthy, and ethically-conscious multimodal systems for a wide range of domains, including emotion recognition, anomaly detection, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👨🏫
0
Multi-scale Bottleneck Transformer for Weakly Supervised Multimodal Violence Detection
Shengyang Sun, Xiaojin Gong
Weakly supervised multimodal violence detection aims to learn a violence detection model by leveraging multiple modalities such as RGB, optical flow, and audio, while only video-level annotations are available. In the pursuit of effective multimodal violence detection (MVD), information redundancy, modality imbalance, and modality asynchrony are identified as three key challenges. In this work, we propose a new weakly supervised MVD method that explicitly addresses these challenges. Specifically, we introduce a multi-scale bottleneck transformer (MSBT) based fusion module that employs a reduced number of bottleneck tokens to gradually condense information and fuse each pair of modalities and utilizes a bottleneck token-based weighting scheme to highlight more important fused features. Furthermore, we propose a temporal consistency contrast loss to semantically align pairwise fused features. Experiments on the largest-scale XD-Violence dataset demonstrate that the proposed method achieves state-of-the-art performance. Code is available at https://github.com/shengyangsun/MSBT.
Read more5/9/2024

0
A Multimodal Transformer for Live Streaming Highlight Prediction
Jiaxin Deng, Shiyao Wang, Dong Shen, Liqin Zhao, Fan Yang, Guorui Zhou, Gaofeng Meng
Recently, live streaming platforms have gained immense popularity. Traditional video highlight detection mainly focuses on visual features and utilizes both past and future content for prediction. However, live streaming requires models to infer without future frames and process complex multimodal interactions, including images, audio and text comments. To address these issues, we propose a multimodal transformer that incorporates historical look-back windows. We introduce a novel Modality Temporal Alignment Module to handle the temporal shift of cross-modal signals. Additionally, using existing datasets with limited manual annotations is insufficient for live streaming whose topics are constantly updated and changed. Therefore, we propose a novel Border-aware Pairwise Loss to learn from a large-scale dataset and utilize user implicit feedback as a weak supervision signal. Extensive experiments show our model outperforms various strong baselines on both real-world scenarios and public datasets. And we will release our dataset and code to better assess this topic.
Read more7/18/2024
0
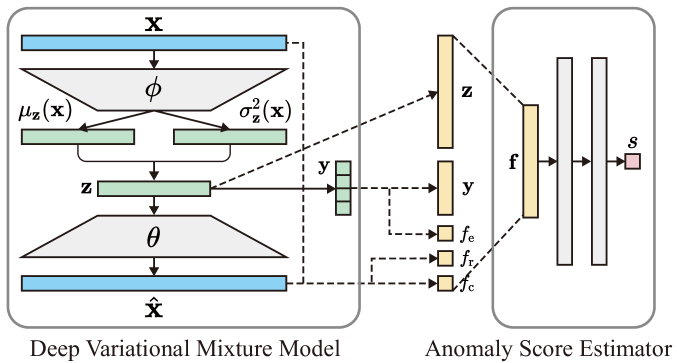
Weakly-supervised anomaly detection for multimodal data distributions
Xu Tan, Junqi Chen, Sylwan Rahardja, Jiawei Yang, Susanto Rahardja
Weakly-supervised anomaly detection can outperform existing unsupervised methods with the assistance of a very small number of labeled anomalies, which attracts increasing attention from researchers. However, existing weakly-supervised anomaly detection methods are limited as these methods do not factor in the multimodel nature of the real-world data distribution. To mitigate this, we propose the Weakly-supervised Variational-mixture-model-based Anomaly Detector (WVAD). WVAD excels in multimodal datasets. It consists of two components: a deep variational mixture model, and an anomaly score estimator. The deep variational mixture model captures various features of the data from different clusters, then these features are delivered to the anomaly score estimator to assess the anomaly levels. Experimental results on three real-world datasets demonstrate WVAD's superiority.
Read more6/14/2024
✨
0
Reliable Object Tracking by Multimodal Hybrid Feature Extraction and Transformer-Based Fusion
Hongze Sun, Rui Liu, Wuque Cai, Jun Wang, Yue Wang, Huajin Tang, Yan Cui, Dezhong Yao, Daqing Guo
Visual object tracking, which is primarily based on visible light image sequences, encounters numerous challenges in complicated scenarios, such as low light conditions, high dynamic ranges, and background clutter. To address these challenges, incorporating the advantages of multiple visual modalities is a promising solution for achieving reliable object tracking. However, the existing approaches usually integrate multimodal inputs through adaptive local feature interactions, which cannot leverage the full potential of visual cues, thus resulting in insufficient feature modeling. In this study, we propose a novel multimodal hybrid tracker (MMHT) that utilizes frame-event-based data for reliable single object tracking. The MMHT model employs a hybrid backbone consisting of an artificial neural network (ANN) and a spiking neural network (SNN) to extract dominant features from different visual modalities and then uses a unified encoder to align the features across different domains. Moreover, we propose an enhanced transformer-based module to fuse multimodal features using attention mechanisms. With these methods, the MMHT model can effectively construct a multiscale and multidimensional visual feature space and achieve discriminative feature modeling. Extensive experiments demonstrate that the MMHT model exhibits competitive performance in comparison with that of other state-of-the-art methods. Overall, our results highlight the effectiveness of the MMHT model in terms of addressing the challenges faced in visual object tracking tasks.
Read more5/29/2024