Multi-Scale Representation Learning for Image Restoration with State-Space Model

0
Sign in to get full access
Overview
- The research paper proposes a novel multi-scale representation learning approach for image restoration tasks using a state-space model.
- The key idea is to learn a multi-scale representation of the image that can capture both local and global features, enabling more effective restoration.
- The state-space model is used to explicitly model the hierarchical and multi-scale structure of natural images, leading to improved performance on tasks like super-resolution, denoising, and deblurring.
Plain English Explanation
The researchers developed a new way to restore images that works better than previous methods. The core idea is to learn multiple scales of information about the image, from small local details to larger global patterns.
They use a type of machine learning model called a state-space model to capture this multi-scale structure. The state-space model can represent the image at different levels of detail, kind of like how you might look at a map that shows both the overall country and the individual streets.
By learning this hierarchical, multi-scale representation of the image, the model is better able to fix problems in the image, like making a blurry image clear, removing noise, or increasing the resolution. The multi-scale approach captures both the fine details and the broader context, leading to more accurate and naturalistic image restoration.
Technical Explanation
The paper introduces a multi-scale representation learning framework for image restoration tasks, built upon a state-space model. The key innovation is the use of a hierarchical, multi-scale state-space structure to capture both local and global image features.
At the core of the approach is a recurrent neural network that operates on a pyramid of image features at different scales. The recurrent structure allows the model to propagate and refine information across these scales, gradually building up a rich, multi-resolution representation of the image.
The state-space formulation provides an explicit way to model the underlying structure of natural images, which tend to exhibit strong hierarchical and multi-scale properties. By incorporating this structural prior, the model is able to better reason about the image and produce higher-quality restoration results.
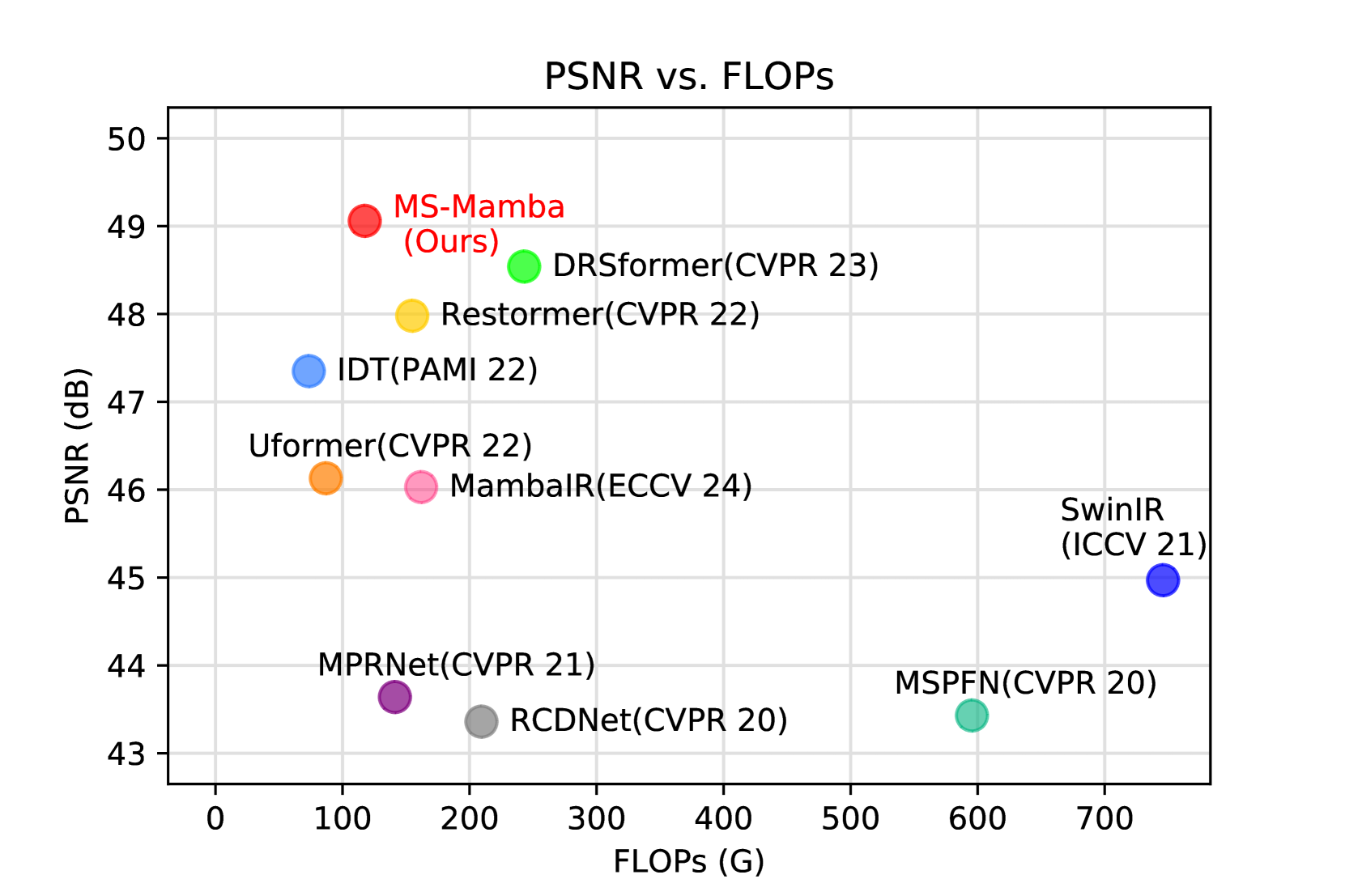
The authors demonstrate the effectiveness of their approach on a range of image restoration tasks, including super-resolution, denoising, and deblurring. The multi-scale state-space model consistently outperforms previous single-scale and non-hierarchical approaches, highlighting the benefits of the proposed representation learning framework.
Critical Analysis
The paper presents a well-designed and theoretically grounded approach to image restoration, with a strong focus on learning effective multi-scale representations. The use of a state-space model to capture the hierarchical structure of natural images is a particularly novel and promising aspect of the work.
However, the authors do not provide a deep analysis of the limitations or potential drawbacks of their method. For example, they do not discuss the computational complexity or real-world deployment challenges of the multi-scale state-space architecture, which could be important considerations for practical applications.
Additionally, while the experimental results are impressive, the paper could benefit from a more thorough comparison to other state-of-the-art image restoration techniques, including those that do not rely on explicit multi-scale or hierarchical modeling. This would help to better contextualize the contributions and identify the unique strengths of the proposed approach.
Overall, the research represents a significant advancement in the field of image restoration and demonstrates the value of incorporating structural priors and multi-scale representations into deep learning models. Further exploration of the method's limitations and potential trade-offs would strengthen the critical analysis and provide a more comprehensive understanding of its merits and drawbacks.
Conclusion
The multi-scale representation learning framework with a state-space model presented in this paper offers a novel and promising approach to image restoration tasks. By explicitly modeling the hierarchical and multi-scale structure of natural images, the proposed method is able to outperform previous techniques in super-resolution, denoising, and deblurring.
The core innovation lies in the state-space formulation, which provides a principled way to incorporate structural priors into the deep learning model. This, combined with the recurrent, multi-scale architecture, enables the model to capture both local and global image features, leading to more accurate and naturalistic restoration results.
While the paper does not delve deeply into the limitations of the approach, the research represents an important step forward in the field of image restoration. The multi-scale state-space model showcases the benefits of learning rich, hierarchical representations for complex visual tasks, and could inspire further advancements in this direction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multi-Scale Representation Learning for Image Restoration with State-Space Model
Yuhong He, Long Peng, Qiaosi Yi, Chen Wu, Lu Wang
Image restoration endeavors to reconstruct a high-quality, detail-rich image from a degraded counterpart, which is a pivotal process in photography and various computer vision systems. In real-world scenarios, different types of degradation can cause the loss of image details at various scales and degrade image contrast. Existing methods predominantly rely on CNN and Transformer to capture multi-scale representations. However, these methods are often limited by the high computational complexity of Transformers and the constrained receptive field of CNN, which hinder them from achieving superior performance and efficiency in image restoration. To address these challenges, we propose a novel Multi-Scale State-Space Model-based (MS-Mamba) for efficient image restoration that enhances the capacity for multi-scale representation learning through our proposed global and regional SSM modules. Additionally, an Adaptive Gradient Block (AGB) and a Residual Fourier Block (RFB) are proposed to improve the network's detail extraction capabilities by capturing gradients in various directions and facilitating learning details in the frequency domain. Extensive experiments on nine public benchmarks across four classic image restoration tasks, image deraining, dehazing, denoising, and low-light enhancement, demonstrate that our proposed method achieves new state-of-the-art performance while maintaining low computational complexity. The source code will be publicly available.
Read more8/20/2024

0
Serpent: Scalable and Efficient Image Restoration via Multi-scale Structured State Space Models
Mohammad Shahab Sepehri, Zalan Fabian, Mahdi Soltanolkotabi
The landscape of computational building blocks of efficient image restoration architectures is dominated by a combination of convolutional processing and various attention mechanisms. However, convolutional filters, while efficient, are inherently local and therefore struggle with modeling long-range dependencies in images. In contrast, attention excels at capturing global interactions between arbitrary image regions, but suffers from a quadratic cost in image dimension. In this work, we propose Serpent, an efficient architecture for high-resolution image restoration that combines recent advances in state space models (SSMs) with multi-scale signal processing in its core computational block. SSMs, originally introduced for sequence modeling, can maintain a global receptive field with a favorable linear scaling in input size. We propose a novel hierarchical architecture inspired by traditional signal processing principles, that converts the input image into a collection of sequences and processes them in a multi-scale fashion. Our experimental results demonstrate that Serpent can achieve reconstruction quality on par with state-of-the-art techniques, while requiring orders of magnitude less compute (up to $150$ fold reduction in FLOPS) and a factor of up to $5times$ less GPU memory while maintaining a compact model size. The efficiency gains achieved by Serpent are especially notable at high image resolutions.
Read more5/31/2024

0
CU-Mamba: Selective State Space Models with Channel Learning for Image Restoration
Rui Deng, Tianpei Gu
Reconstructing degraded images is a critical task in image processing. Although CNN and Transformer-based models are prevalent in this field, they exhibit inherent limitations, such as inadequate long-range dependency modeling and high computational costs. To overcome these issues, we introduce the Channel-Aware U-Shaped Mamba (CU-Mamba) model, which incorporates a dual State Space Model (SSM) framework into the U-Net architecture. CU-Mamba employs a Spatial SSM module for global context encoding and a Channel SSM component to preserve channel correlation features, both in linear computational complexity relative to the feature map size. Extensive experimental results validate CU-Mamba's superiority over existing state-of-the-art methods, underscoring the importance of integrating both spatial and channel contexts in image restoration.
Read more4/19/2024

0
LFMamba: Light Field Image Super-Resolution with State Space Model
Wang xia, Yao Lu, Shunzhou Wang, Ziqi Wang, Peiqi Xia, Tianfei Zhou
Recent years have witnessed significant advancements in light field image super-resolution (LFSR) owing to the progress of modern neural networks. However, these methods often face challenges in capturing long-range dependencies (CNN-based) or encounter quadratic computational complexities (Transformer-based), which limit their performance. Recently, the State Space Model (SSM) with selective scanning mechanism (S6), exemplified by Mamba, has emerged as a superior alternative in various vision tasks compared to traditional CNN- and Transformer-based approaches, benefiting from its effective long-range sequence modeling capability and linear-time complexity. Therefore, integrating S6 into LFSR becomes compelling, especially considering the vast data volume of 4D light fields. However, the primary challenge lies in emph{designing an appropriate scanning method for 4D light fields that effectively models light field features}. To tackle this, we employ SSMs on the informative 2D slices of 4D LFs to fully explore spatial contextual information, complementary angular information, and structure information. To achieve this, we carefully devise a basic SSM block characterized by an efficient SS2D mechanism that facilitates more effective and efficient feature learning on these 2D slices. Based on the above two designs, we further introduce an SSM-based network for LFSR termed LFMamba. Experimental results on LF benchmarks demonstrate the superior performance of LFMamba. Furthermore, extensive ablation studies are conducted to validate the efficacy and generalization ability of our proposed method. We expect that our LFMamba shed light on effective representation learning of LFs with state space models.
Read more6/19/2024