Multi-Track Timeline Control for Text-Driven 3D Human Motion Generation
2401.08559
0
0
🛸
Abstract
Recent advances in generative modeling have led to promising progress on synthesizing 3D human motion from text, with methods that can generate character animations from short prompts and specified durations. However, using a single text prompt as input lacks the fine-grained control needed by animators, such as composing multiple actions and defining precise durations for parts of the motion. To address this, we introduce the new problem of timeline control for text-driven motion synthesis, which provides an intuitive, yet fine-grained, input interface for users. Instead of a single prompt, users can specify a multi-track timeline of multiple prompts organized in temporal intervals that may overlap. This enables specifying the exact timings of each action and composing multiple actions in sequence or at overlapping intervals. To generate composite animations from a multi-track timeline, we propose a new test-time denoising method. This method can be integrated with any pre-trained motion diffusion model to synthesize realistic motions that accurately reflect the timeline. At every step of denoising, our method processes each timeline interval (text prompt) individually, subsequently aggregating the predictions with consideration for the specific body parts engaged in each action. Experimental comparisons and ablations validate that our method produces realistic motions that respect the semantics and timing of given text prompts. Our code and models are publicly available at https://mathis.petrovich.fr/stmc.
Create account to get full access
Overview
- Researchers have made significant progress in generating 3D human motion from text prompts, allowing users to create character animations from short descriptions.
- However, the existing methods lack the fine-grained control needed by animators, such as composing multiple actions and defining precise durations for parts of the motion.
- To address this, the researchers introduce a new problem called "timeline control for text-driven motion synthesis," which allows users to specify a multi-track timeline of text prompts with overlapping intervals, enabling the composition of multiple actions with precise timing.
- The researchers propose a new test-time denoising method that can be integrated with pre-trained motion diffusion models to synthesize realistic motions that accurately reflect the specified timeline.
Plain English Explanation
The paper describes a new way to create 3D animations of human motion using text. Previous methods allowed users to generate character animations from short prompts, but these didn't give animators much control over the details of the motion.
The researchers' new approach lets users create a "timeline" of text prompts, where they can specify multiple actions and exactly when each one should happen. For example, you could say "The character walks for 5 seconds, then raises their arms for 3 seconds, then turns around for 2 seconds." This gives animators much more fine-grained control over the motion.
To generate the animations from these detailed timelines, the researchers developed a new "denoising" technique. This method can work with existing machine learning models that generate 3D motions from text, and it processes each part of the timeline separately before combining the results. This helps ensure the final animation accurately reflects all the details specified in the timeline.
The researchers tested their method and showed that it produces realistic motions that respect the semantics and timing of the text prompts. Their code and models are publicly available, so other researchers and animators can use this new technique.
Technical Explanation
The paper introduces the new problem of "timeline control for text-driven motion synthesis," which aims to give users more fine-grained control over 3D character animations generated from text prompts.
Instead of a single text prompt as input, the researchers allow users to specify a multi-track timeline of multiple prompts organized in temporal intervals that may overlap. This enables users to compose multiple actions in sequence or at overlapping intervals, and to define the precise durations for each part of the motion.
To generate composite animations from these multi-track timelines, the researchers propose a new test-time denoising method. This method can be integrated with any pre-trained motion diffusion model, which are state-of-the-art models for generating 3D human motions from text.
The key idea of the denoising method is to process each timeline interval (text prompt) individually during the iterative denoising process, and then aggregate the predictions while considering the specific body parts engaged in each action. This allows the model to synthesize realistic motions that accurately reflect the semantics and timing specified in the multi-track timeline.
The researchers conducted extensive experiments and ablations to validate their approach. They show that their method produces motions that respect the given text prompts, both in terms of the semantics and the precise timing of the different actions.
Critical Analysis
The researchers address an important limitation of existing text-to-motion synthesis methods, which is the lack of fine-grained control over the generated animations. Their timeline-based input interface is a promising step towards giving animators and users more flexibility and precision when creating 3D character motions from text.
However, the paper does not discuss some potential limitations or challenges with this approach. For example, it's unclear how well the method would scale to very complex timelines with many overlapping actions, or how robust it would be to ambiguous or contradictory text prompts.
Additionally, the paper focuses solely on generating motions from text and does not consider integrating the motion with 3D scenes and environments, which could be an important next step for enabling more comprehensive text-driven animation creation.
Overall, the researchers have made a valuable contribution by introducing the timeline control problem and demonstrating a effective solution. But there is still room for further research to address the scalability, robustness, and real-world applicability of text-driven animation systems.
Conclusion
This paper presents a new approach for giving users fine-grained control over 3D character animations generated from text prompts. By allowing users to specify a multi-track timeline of text inputs, the method enables the composition of complex motions with precise timing.
The key technical innovation is a test-time denoising technique that can be integrated with pre-trained motion diffusion models to synthesize realistic animations that accurately reflect the specified timeline. Experiments show this method produces motions that respect the semantics and timing of the text prompts.
Overall, this research advances the state-of-the-art in text-driven animation by addressing a important limitation in existing systems. The publicly available code and models can enable further developments in this area, potentially leading to more expressive and controllable tools for 3D character animation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Generating Human Interaction Motions in Scenes with Text Control
Hongwei Yi, Justus Thies, Michael J. Black, Xue Bin Peng, Davis Rempe
0
0
We present TeSMo, a method for text-controlled scene-aware motion generation based on denoising diffusion models. Previous text-to-motion methods focus on characters in isolation without considering scenes due to the limited availability of datasets that include motion, text descriptions, and interactive scenes. Our approach begins with pre-training a scene-agnostic text-to-motion diffusion model, emphasizing goal-reaching constraints on large-scale motion-capture datasets. We then enhance this model with a scene-aware component, fine-tuned using data augmented with detailed scene information, including ground plane and object shapes. To facilitate training, we embed annotated navigation and interaction motions within scenes. The proposed method produces realistic and diverse human-object interactions, such as navigation and sitting, in different scenes with various object shapes, orientations, initial body positions, and poses. Extensive experiments demonstrate that our approach surpasses prior techniques in terms of the plausibility of human-scene interactions, as well as the realism and variety of the generated motions. Code will be released upon publication of this work at https://research.nvidia.com/labs/toronto-ai/tesmo.
4/17/2024

Text-guided 3D Human Motion Generation with Keyframe-based Parallel Skip Transformer
Zichen Geng, Caren Han, Zeeshan Hayder, Jian Liu, Mubarak Shah, Ajmal Mian
0
0
Text-driven human motion generation is an emerging task in animation and humanoid robot design. Existing algorithms directly generate the full sequence which is computationally expensive and prone to errors as it does not pay special attention to key poses, a process that has been the cornerstone of animation for decades. We propose KeyMotion, that generates plausible human motion sequences corresponding to input text by first generating keyframes followed by in-filling. We use a Variational Autoencoder (VAE) with Kullback-Leibler regularization to project the keyframes into a latent space to reduce dimensionality and further accelerate the subsequent diffusion process. For the reverse diffusion, we propose a novel Parallel Skip Transformer that performs cross-modal attention between the keyframe latents and text condition. To complete the motion sequence, we propose a text-guided Transformer designed to perform motion-in-filling, ensuring the preservation of both fidelity and adherence to the physical constraints of human motion. Experiments show that our method achieves state-of-theart results on the HumanML3D dataset outperforming others on all R-precision metrics and MultiModal Distance. KeyMotion also achieves competitive performance on the KIT dataset, achieving the best results on Top3 R-precision, FID, and Diversity metrics.
5/27/2024
⚙️
Generating Human Motion in 3D Scenes from Text Descriptions
Zhi Cen, Huaijin Pi, Sida Peng, Zehong Shen, Minghui Yang, Shuai Zhu, Hujun Bao, Xiaowei Zhou
0
0
Generating human motions from textual descriptions has gained growing research interest due to its wide range of applications. However, only a few works consider human-scene interactions together with text conditions, which is crucial for visual and physical realism. This paper focuses on the task of generating human motions in 3D indoor scenes given text descriptions of the human-scene interactions. This task presents challenges due to the multi-modality nature of text, scene, and motion, as well as the need for spatial reasoning. To address these challenges, we propose a new approach that decomposes the complex problem into two more manageable sub-problems: (1) language grounding of the target object and (2) object-centric motion generation. For language grounding of the target object, we leverage the power of large language models. For motion generation, we design an object-centric scene representation for the generative model to focus on the target object, thereby reducing the scene complexity and facilitating the modeling of the relationship between human motions and the object. Experiments demonstrate the better motion quality of our approach compared to baselines and validate our design choices.
5/14/2024
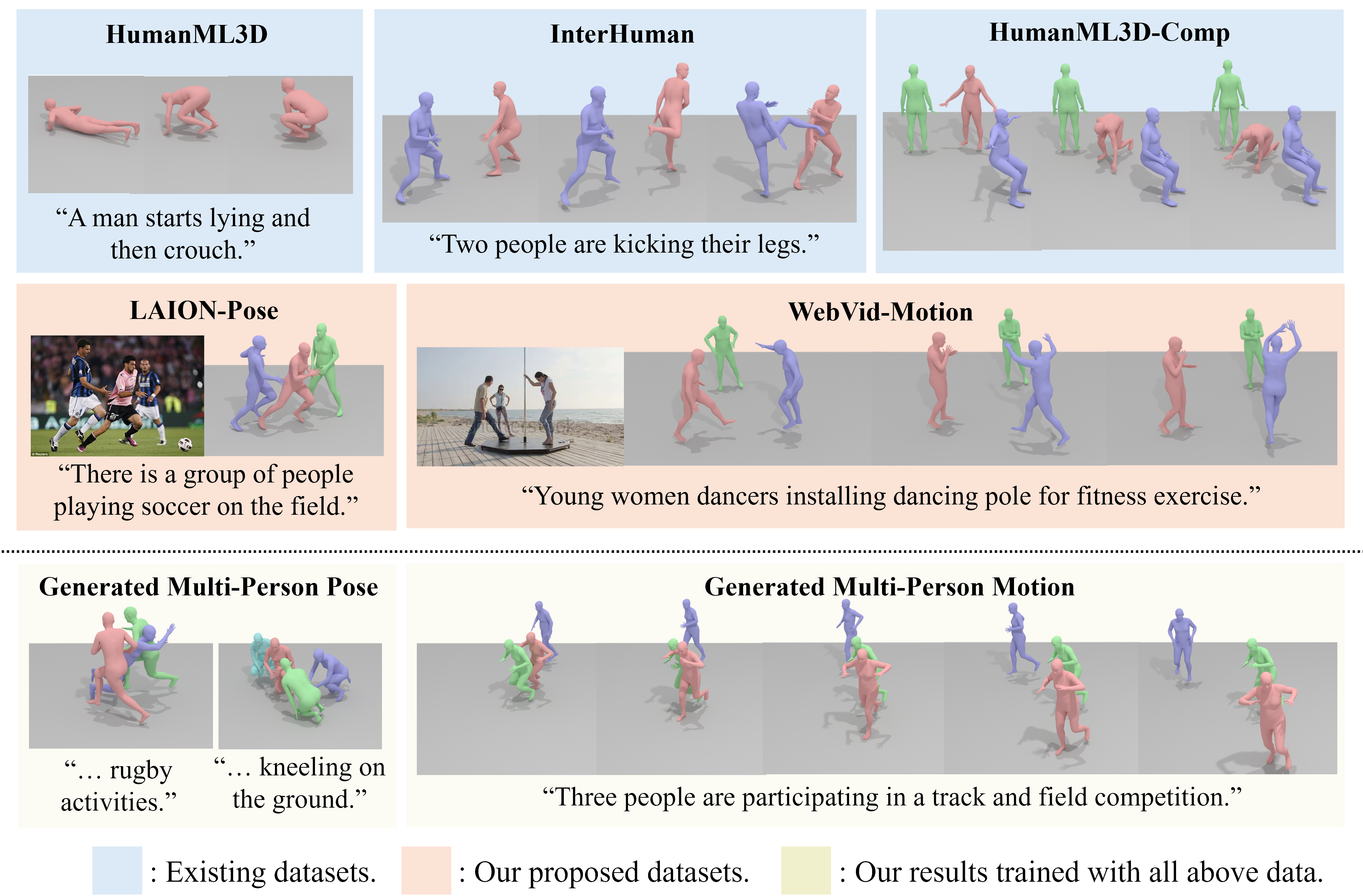
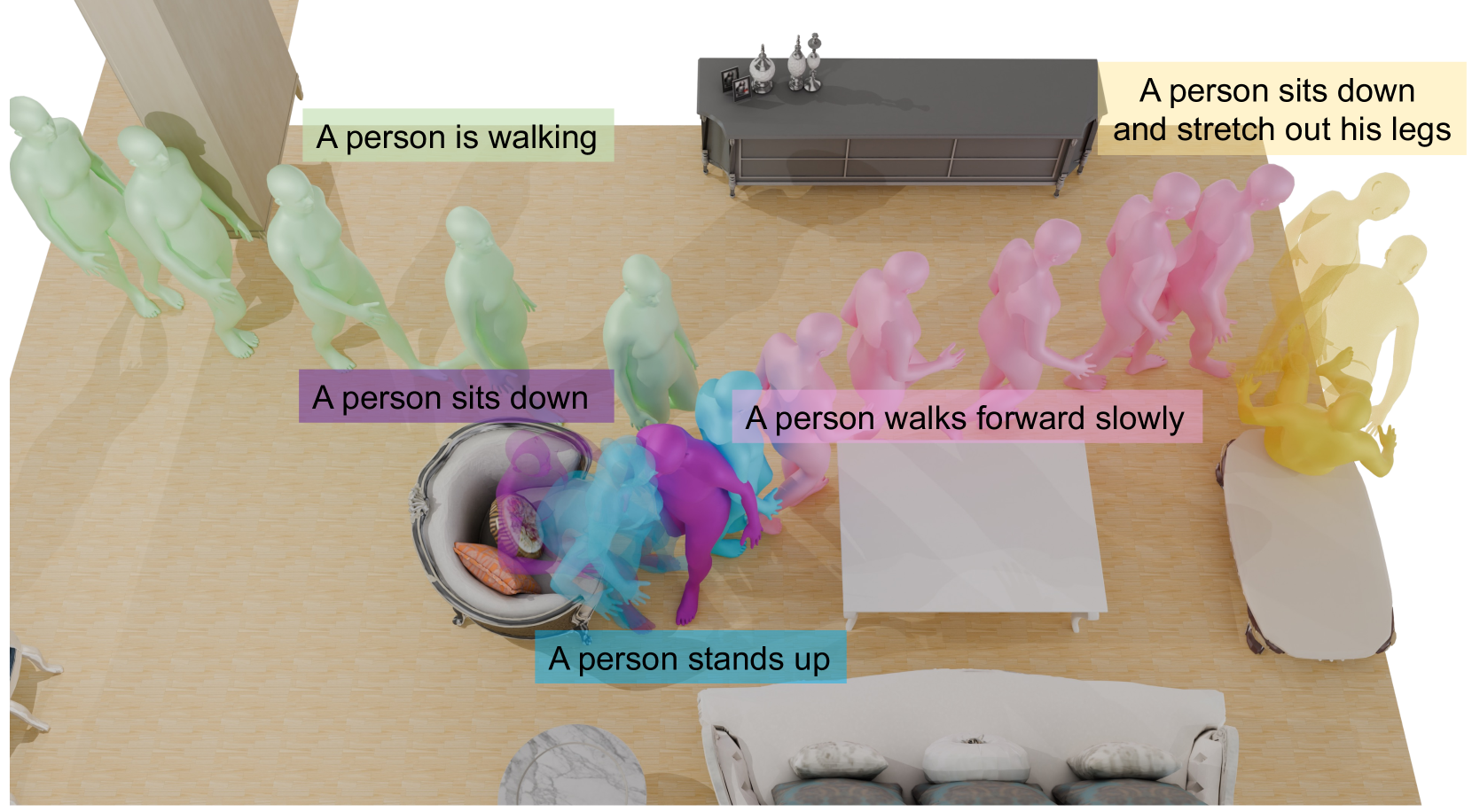
Towards Open Domain Text-Driven Synthesis of Multi-Person Motions
Mengyi Shan, Lu Dong, Yutao Han, Yuan Yao, Tao Liu, Ifeoma Nwogu, Guo-Jun Qi, Mitch Hill
0
0
This work aims to generate natural and diverse group motions of multiple humans from textual descriptions. While single-person text-to-motion generation is extensively studied, it remains challenging to synthesize motions for more than one or two subjects from in-the-wild prompts, mainly due to the lack of available datasets. In this work, we curate human pose and motion datasets by estimating pose information from large-scale image and video datasets. Our models use a transformer-based diffusion framework that accommodates multiple datasets with any number of subjects or frames. Experiments explore both generation of multi-person static poses and generation of multi-person motion sequences. To our knowledge, our method is the first to generate multi-subject motion sequences with high diversity and fidelity from a large variety of textual prompts.
5/30/2024