Multi-view Aggregation Network for Dichotomous Image Segmentation
2404.07445
0
0

Abstract
Dichotomous Image Segmentation (DIS) has recently emerged towards high-precision object segmentation from high-resolution natural images. When designing an effective DIS model, the main challenge is how to balance the semantic dispersion of high-resolution targets in the small receptive field and the loss of high-precision details in the large receptive field. Existing methods rely on tedious multiple encoder-decoder streams and stages to gradually complete the global localization and local refinement. Human visual system captures regions of interest by observing them from multiple views. Inspired by it, we model DIS as a multi-view object perception problem and provide a parsimonious multi-view aggregation network (MVANet), which unifies the feature fusion of the distant view and close-up view into a single stream with one encoder-decoder structure. With the help of the proposed multi-view complementary localization and refinement modules, our approach established long-range, profound visual interactions across multiple views, allowing the features of the detailed close-up view to focus on highly slender structures.Experiments on the popular DIS-5K dataset show that our MVANet significantly outperforms state-of-the-art methods in both accuracy and speed. The source code and datasets will be publicly available at href{https://github.com/qianyu-dlut/MVANet}{MVANet}.
Create account to get full access
Overview
- This paper presents a novel "Multi-view Aggregation Network" for dichotomous image segmentation, which aims to effectively combine information from multiple views of an image.
- Dichotomous image segmentation is the task of separating an image into two distinct regions, such as foreground and background.
- The proposed network leverages information from different perspectives to improve the accuracy and robustness of the segmentation.
Plain English Explanation
The paper describes a new deep learning model called the "Multi-view Aggregation Network" that is designed to perform dichotomous image segmentation. Dichotomous segmentation is the process of dividing an image into two distinct parts, like the main subject (foreground) and everything else (background).
The key idea behind this model is to combine information from multiple "views" or perspectives of the same image. By considering the image from different angles, the network can make more informed decisions about where the boundaries between the foreground and background should be. This multi-view approach is intended to improve the accuracy and robustness of the segmentation compared to using a single view.
The authors demonstrate that their Multi-view Aggregation Network outperforms other state-of-the-art segmentation models on several benchmark datasets. This suggests that leveraging multiple perspectives can be a powerful technique for this type of image analysis task.
Technical Explanation
The paper proposes a "Multi-view Aggregation Network" for dichotomous image segmentation. Dichotomous image segmentation is the task of separating an image into two distinct regions, such as foreground and background.
The key innovation of this work is the use of multiple "views" of the input image, which are combined to improve the segmentation performance. Specifically, the network takes as input several transformed versions of the image, such as rotated or flipped variants. These multiple views are then processed through a shared encoder network to extract features from each perspective.
The encoded features from the different views are then aggregated using a novel fusion module. This module learns how to effectively combine the multi-view representations to produce a unified feature map. This fused representation is then used by a decoder network to generate the final segmentation mask.
The authors demonstrate the effectiveness of their Multi-view Aggregation Network on several standard dichotomous segmentation benchmarks. They show that their approach outperforms other state-of-the-art segmentation models, indicating that leveraging multiple views of the input can be a powerful technique for this task.
Critical Analysis
The paper makes a compelling case for the benefits of using a multi-view approach for dichotomous image segmentation. By considering the image from multiple perspectives, the network is able to extract more robust and informative features, leading to improved segmentation performance.
However, one potential limitation of the proposed approach is the computational overhead of processing multiple views of the input. Depending on the number of views and the complexity of the network, this could result in increased inference time, which may be a concern for real-world applications that require fast processing.
Additionally, the paper does not thoroughly explore the tradeoffs between the number of views and the segmentation accuracy. It would be interesting to see how the performance scales as the number of views is increased, and whether there is an optimal balance between accuracy and computational cost.
Finally, the authors mention that their approach is generalizable to other computer vision tasks beyond dichotomous segmentation, such as object detection and 3D reconstruction. Further research could investigate the effectiveness of the Multi-view Aggregation Network on these other applications to fully assess its potential and limitations.
Conclusion
This paper presents a novel "Multi-view Aggregation Network" for dichotomous image segmentation, which leverages information from multiple perspectives of the input image to improve the accuracy and robustness of the segmentation. The authors demonstrate the effectiveness of their approach on several benchmark datasets, outperforming other state-of-the-art segmentation models.
While the multi-view approach shows promise, there are some potential limitations to consider, such as the computational overhead and the need to further explore the tradeoffs between the number of views and segmentation performance. Nevertheless, this work represents an interesting step forward in leveraging diverse information sources for image understanding tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

MVDiff: Scalable and Flexible Multi-View Diffusion for 3D Object Reconstruction from Single-View
Emmanuelle Bourigault, Pauline Bourigault
0
0
Generating consistent multiple views for 3D reconstruction tasks is still a challenge to existing image-to-3D diffusion models. Generally, incorporating 3D representations into diffusion model decrease the model's speed as well as generalizability and quality. This paper proposes a general framework to generate consistent multi-view images from single image or leveraging scene representation transformer and view-conditioned diffusion model. In the model, we introduce epipolar geometry constraints and multi-view attention to enforce 3D consistency. From as few as one image input, our model is able to generate 3D meshes surpassing baselines methods in evaluation metrics, including PSNR, SSIM and LPIPS.
6/14/2024

Rethinking Multi-view Representation Learning via Distilled Disentangling
Guanzhou Ke, Bo Wang, Xiaoli Wang, Shengfeng He
0
0
Multi-view representation learning aims to derive robust representations that are both view-consistent and view-specific from diverse data sources. This paper presents an in-depth analysis of existing approaches in this domain, highlighting a commonly overlooked aspect: the redundancy between view-consistent and view-specific representations. To this end, we propose an innovative framework for multi-view representation learning, which incorporates a technique we term 'distilled disentangling'. Our method introduces the concept of masked cross-view prediction, enabling the extraction of compact, high-quality view-consistent representations from various sources without incurring extra computational overhead. Additionally, we develop a distilled disentangling module that efficiently filters out consistency-related information from multi-view representations, resulting in purer view-specific representations. This approach significantly reduces redundancy between view-consistent and view-specific representations, enhancing the overall efficiency of the learning process. Our empirical evaluations reveal that higher mask ratios substantially improve the quality of view-consistent representations. Moreover, we find that reducing the dimensionality of view-consistent representations relative to that of view-specific representations further refines the quality of the combined representations. Our code is accessible at: https://github.com/Guanzhou-Ke/MRDD.
4/1/2024

Open3DIS: Open-Vocabulary 3D Instance Segmentation with 2D Mask Guidance
Phuc D. A. Nguyen, Tuan Duc Ngo, Evangelos Kalogerakis, Chuang Gan, Anh Tran, Cuong Pham, Khoi Nguyen
0
0
We introduce Open3DIS, a novel solution designed to tackle the problem of Open-Vocabulary Instance Segmentation within 3D scenes. Objects within 3D environments exhibit diverse shapes, scales, and colors, making precise instance-level identification a challenging task. Recent advancements in Open-Vocabulary scene understanding have made significant strides in this area by employing class-agnostic 3D instance proposal networks for object localization and learning queryable features for each 3D mask. While these methods produce high-quality instance proposals, they struggle with identifying small-scale and geometrically ambiguous objects. The key idea of our method is a new module that aggregates 2D instance masks across frames and maps them to geometrically coherent point cloud regions as high-quality object proposals addressing the above limitations. These are then combined with 3D class-agnostic instance proposals to include a wide range of objects in the real world. To validate our approach, we conducted experiments on three prominent datasets, including ScanNet200, S3DIS, and Replica, demonstrating significant performance gains in segmenting objects with diverse categories over the state-of-the-art approaches.
4/9/2024
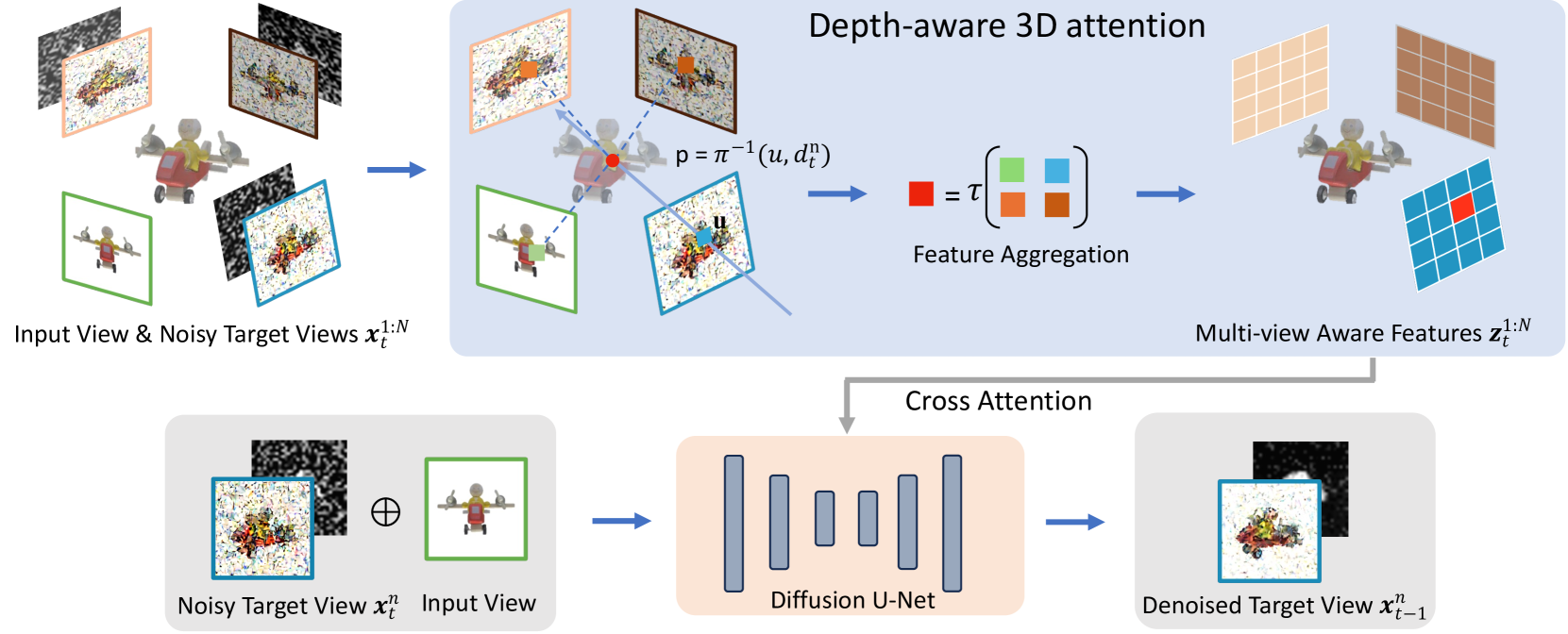
MVD-Fusion: Single-view 3D via Depth-consistent Multi-view Generation
Hanzhe Hu, Zhizhuo Zhou, Varun Jampani, Shubham Tulsiani
0
0
We present MVD-Fusion: a method for single-view 3D inference via generative modeling of multi-view-consistent RGB-D images. While recent methods pursuing 3D inference advocate learning novel-view generative models, these generations are not 3D-consistent and require a distillation process to generate a 3D output. We instead cast the task of 3D inference as directly generating mutually-consistent multiple views and build on the insight that additionally inferring depth can provide a mechanism for enforcing this consistency. Specifically, we train a denoising diffusion model to generate multi-view RGB-D images given a single RGB input image and leverage the (intermediate noisy) depth estimates to obtain reprojection-based conditioning to maintain multi-view consistency. We train our model using large-scale synthetic dataset Obajverse as well as the real-world CO3D dataset comprising of generic camera viewpoints. We demonstrate that our approach can yield more accurate synthesis compared to recent state-of-the-art, including distillation-based 3D inference and prior multi-view generation methods. We also evaluate the geometry induced by our multi-view depth prediction and find that it yields a more accurate representation than other direct 3D inference approaches.
4/5/2024