MVD-Fusion: Single-view 3D via Depth-consistent Multi-view Generation
2404.03656
0
0
Abstract
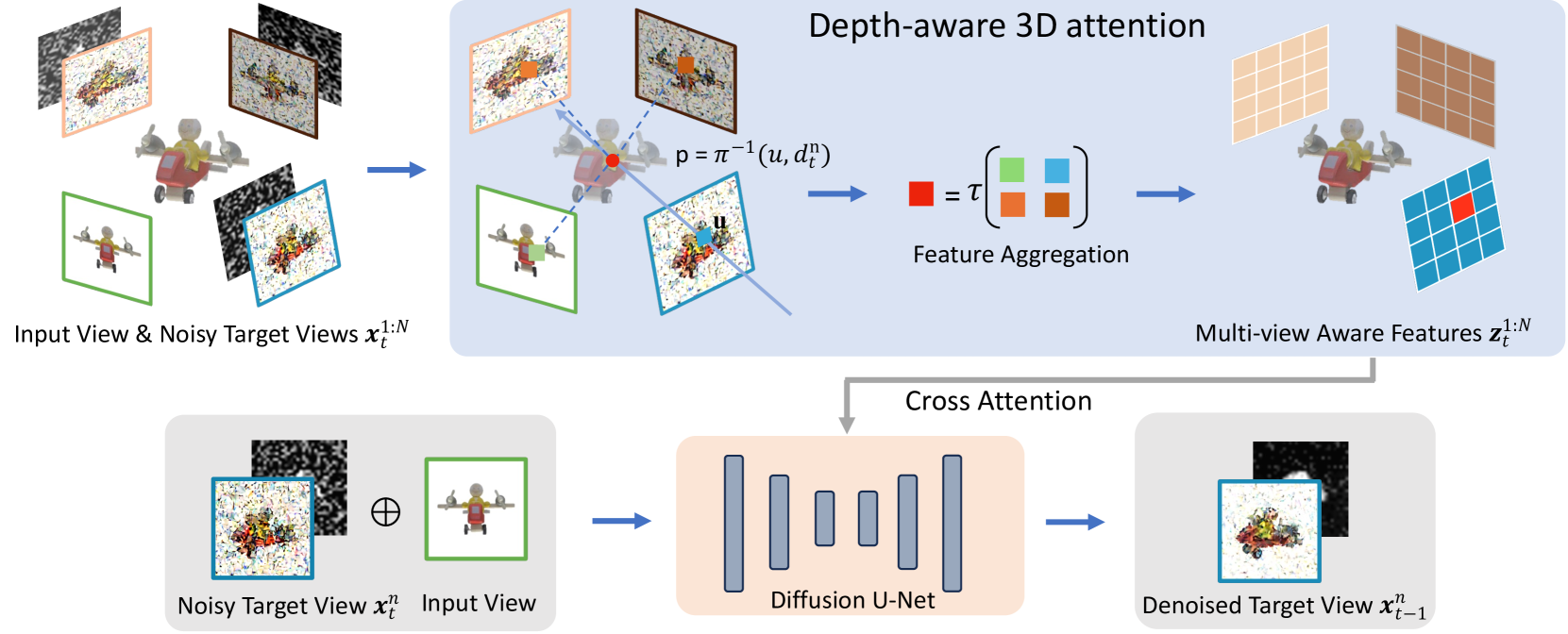
We present MVD-Fusion: a method for single-view 3D inference via generative modeling of multi-view-consistent RGB-D images. While recent methods pursuing 3D inference advocate learning novel-view generative models, these generations are not 3D-consistent and require a distillation process to generate a 3D output. We instead cast the task of 3D inference as directly generating mutually-consistent multiple views and build on the insight that additionally inferring depth can provide a mechanism for enforcing this consistency. Specifically, we train a denoising diffusion model to generate multi-view RGB-D images given a single RGB input image and leverage the (intermediate noisy) depth estimates to obtain reprojection-based conditioning to maintain multi-view consistency. We train our model using large-scale synthetic dataset Obajverse as well as the real-world CO3D dataset comprising of generic camera viewpoints. We demonstrate that our approach can yield more accurate synthesis compared to recent state-of-the-art, including distillation-based 3D inference and prior multi-view generation methods. We also evaluate the geometry induced by our multi-view depth prediction and find that it yields a more accurate representation than other direct 3D inference approaches.
Get summaries of the top AI research delivered straight to your inbox:
Overview
• This paper presents MVD-Fusion, a novel approach for generating high-quality 3D models from a single input image.
• The key idea is to leverage depth-consistent multi-view generation to overcome the challenge of 3D reconstruction from a single viewpoint.
• The method involves training a generative model to produce multiple, depth-consistent views of the 3D object, which are then fused to obtain the final 3D reconstruction.
Plain English Explanation
Imagine you have a single photo of an object, and you want to create a 3D model of that object. This can be a challenging task, as a single photo only provides information from one perspective. MVD-Fusion addresses this problem by generating multiple, consistent views of the 3D object from the single input image.
The researchers train a machine learning model to take the single photo as input and output several different views of the 3D object, all of which are designed to be depth-consistent. This means that the views are coordinated and aligned, so that when you put them together, you get a coherent 3D representation of the original object.
This approach is powerful because it allows you to reconstruct 3D models from just a single image, without needing multiple photos or other additional information. By generating multiple, consistent views, the method is able to overcome the limitations of working with a single viewpoint.
Technical Explanation
The core of the MVD-Fusion approach is a generative model that can produce multiple, depth-consistent views of a 3D object from a single input image. The model is trained on a dataset of 3D object scans, where each object is represented by multiple camera views.
During training, the model learns to map the single input image to a set of depth-consistent output views. This is achieved through the use of a novel multi-view depth consistency loss, which ensures that the generated views are aligned and exhibit coherent depth information.
At inference time, the trained model takes a single input image and outputs multiple, depth-consistent views of the 3D object. These views are then fused using a 3D reconstruction algorithm to obtain the final 3D model.
The authors demonstrate the effectiveness of MVD-Fusion on several benchmarks, showing that it outperforms existing single-view 3D reconstruction methods in terms of both accuracy and visual quality.
Critical Analysis
The MVD-Fusion approach is a promising step towards more robust and practical 3D reconstruction from single images. By leveraging depth-consistent multi-view generation, the method is able to overcome some of the inherent limitations of working with a single viewpoint.
However, the paper does not address several potential limitations of the approach. For example, the method may struggle with highly complex or occluded objects, as the generative model may not be able to accurately predict the multiple, consistent views. Additionally, the reliance on 3D object scans for training data could limit the method's applicability to real-world scenarios where such data may not be readily available.
Further research could explore ways to make the MVD-Fusion approach more generalizable, perhaps by incorporating additional cues or adapting the method to work with more diverse input data. Additionally, a more thorough analysis of the method's failure cases and potential biases would help provide a more complete understanding of its strengths and limitations.
Conclusion
The MVD-Fusion paper presents a novel approach for generating high-quality 3D models from a single input image. By leveraging depth-consistent multi-view generation, the method is able to overcome the challenges of single-view 3D reconstruction and produce accurate 3D representations.
This research represents an important step forward in the field of 3D computer vision, with potential applications in areas such as augmented reality, robotics, and digital content creation. While the method has some limitations, the core ideas and insights presented in this paper could inspire further advancements in this rapidly evolving field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
MVDiffusion++: A Dense High-resolution Multi-view Diffusion Model for Single or Sparse-view 3D Object Reconstruction
Shitao Tang, Jiacheng Chen, Dilin Wang, Chengzhou Tang, Fuyang Zhang, Yuchen Fan, Vikas Chandra, Yasutaka Furukawa, Rakesh Ranjan
0
0
This paper presents a neural architecture MVDiffusion++ for 3D object reconstruction that synthesizes dense and high-resolution views of an object given one or a few images without camera poses. MVDiffusion++ achieves superior flexibility and scalability with two surprisingly simple ideas: 1) A ``pose-free architecture'' where standard self-attention among 2D latent features learns 3D consistency across an arbitrary number of conditional and generation views without explicitly using camera pose information; and 2) A ``view dropout strategy'' that discards a substantial number of output views during training, which reduces the training-time memory footprint and enables dense and high-resolution view synthesis at test time. We use the Objaverse for training and the Google Scanned Objects for evaluation with standard novel view synthesis and 3D reconstruction metrics, where MVDiffusion++ significantly outperforms the current state of the arts. We also demonstrate a text-to-3D application example by combining MVDiffusion++ with a text-to-image generative model. The project page is at https://mvdiffusion-plusplus.github.io.
5/1/2024

MVDiff: Scalable and Flexible Multi-View Diffusion for 3D Object Reconstruction from Single-View
Emmanuelle Bourigault, Pauline Bourigault
0
0
Generating consistent multiple views for 3D reconstruction tasks is still a challenge to existing image-to-3D diffusion models. Generally, incorporating 3D representations into diffusion model decrease the model's speed as well as generalizability and quality. This paper proposes a general framework to generate consistent multi-view images from single image or leveraging scene representation transformer and view-conditioned diffusion model. In the model, we introduce epipolar geometry constraints and multi-view attention to enforce 3D consistency. From as few as one image input, our model is able to generate 3D meshes surpassing baselines methods in evaluation metrics, including PSNR, SSIM and LPIPS.
5/8/2024
🛸
MVDream: Multi-view Diffusion for 3D Generation
Yichun Shi, Peng Wang, Jianglong Ye, Mai Long, Kejie Li, Xiao Yang
0
0
We introduce MVDream, a diffusion model that is able to generate consistent multi-view images from a given text prompt. Learning from both 2D and 3D data, a multi-view diffusion model can achieve the generalizability of 2D diffusion models and the consistency of 3D renderings. We demonstrate that such a multi-view diffusion model is implicitly a generalizable 3D prior agnostic to 3D representations. It can be applied to 3D generation via Score Distillation Sampling, significantly enhancing the consistency and stability of existing 2D-lifting methods. It can also learn new concepts from a few 2D examples, akin to DreamBooth, but for 3D generation.
4/19/2024
💬
WildFusion: Learning 3D-Aware Latent Diffusion Models in View Space
Katja Schwarz, Seung Wook Kim, Jun Gao, Sanja Fidler, Andreas Geiger, Karsten Kreis
0
0
Modern learning-based approaches to 3D-aware image synthesis achieve high photorealism and 3D-consistent viewpoint changes for the generated images. Existing approaches represent instances in a shared canonical space. However, for in-the-wild datasets a shared canonical system can be difficult to define or might not even exist. In this work, we instead model instances in view space, alleviating the need for posed images and learned camera distributions. We find that in this setting, existing GAN-based methods are prone to generating flat geometry and struggle with distribution coverage. We hence propose WildFusion, a new approach to 3D-aware image synthesis based on latent diffusion models (LDMs). We first train an autoencoder that infers a compressed latent representation, which additionally captures the images' underlying 3D structure and enables not only reconstruction but also novel view synthesis. To learn a faithful 3D representation, we leverage cues from monocular depth prediction. Then, we train a diffusion model in the 3D-aware latent space, thereby enabling synthesis of high-quality 3D-consistent image samples, outperforming recent state-of-the-art GAN-based methods. Importantly, our 3D-aware LDM is trained without any direct supervision from multiview images or 3D geometry and does not require posed images or learned pose or camera distributions. It directly learns a 3D representation without relying on canonical camera coordinates. This opens up promising research avenues for scalable 3D-aware image synthesis and 3D content creation from in-the-wild image data. See https://katjaschwarz.github.io/wildfusion for videos of our 3D results.
4/15/2024