Multilingual Prompts in LLM-Based Recommenders: Performance Across Languages

0

Sign in to get full access
Overview
- This paper examines the performance of multilingual prompts in large language model (LLM)-based recommender systems across different languages.
- The researchers explore how well LLM-based recommenders can handle prompts in multiple languages and provide recommendations.
- The study aims to understand the challenges and opportunities of developing multilingual recommender systems using LLMs.
Plain English Explanation
The paper looks at how well recommender systems that use large language models (LLMs) perform when they receive prompts in different languages. Recommender systems are algorithms that suggest products, content, or information to users based on their preferences and behavior.
The researchers wanted to see if these LLM-based recommenders could handle prompts (requests for recommendations) in multiple languages, not just the language the system was trained on. This is important because many users around the world speak different languages, and having a recommender system that can work across languages could make it more useful and accessible.
The study explores the challenges and opportunities of building multilingual recommender systems using LLMs. LLMs are powerful AI models that can understand and generate human-like text in many languages. By testing how well LLM-based recommenders perform with prompts in different languages, the researchers aimed to understand the potential and limitations of this approach for creating recommender systems that can serve diverse, multilingual audiences.
Technical Explanation
The paper presents an empirical study on the performance of multilingual prompts in LLM-based recommender systems. The researchers evaluated several LLM-based recommender models on their ability to provide relevant recommendations in response to prompts across multiple languages, including English, Spanish, French, and German.
The experiment design involved:
- Selecting a set of LLM-based recommender models, including prompting-based and other approaches.
- Translating a common set of product recommendation prompts into the target languages.
- Evaluating the recommender models' performance on the multilingual prompts using standard recommendation metrics, such as precision, recall, and normalized discounted cumulative gain (NDCG).
The results show that the LLM-based recommenders generally maintained good performance across the different languages, with some variation in the relative performance between models. The paper discusses the implications of these findings for the development of multilingual recommender systems that can serve diverse user populations.
Critical Analysis
The paper provides valuable insights into the capabilities and limitations of using LLMs for building multilingual recommender systems. While the results suggest that LLM-based recommenders can handle prompts in multiple languages reasonably well, the authors acknowledge that further research is needed to fully understand the challenges and best practices for developing robust, multilingual recommender systems.
One potential limitation of the study is the relatively small set of target languages (English, Spanish, French, and German) used in the experiments. Expanding the evaluation to include a wider range of languages, particularly those with more diverse linguistic structures, could provide additional insights into the generalizability of the findings.
Additionally, the paper does not explore the impact of cultural and contextual factors on the performance of multilingual recommenders. Recommendations that are relevant and engaging for users in one language or region may not necessarily translate well to other cultural contexts. Addressing these nuances could be an important area for future research.
Conclusion
This paper presents an important step towards understanding the potential and challenges of using LLMs to power multilingual recommender systems. The researchers demonstrate that LLM-based recommenders can maintain good performance across multiple languages, suggesting that this approach could be a viable option for developing recommender systems that can serve diverse, global audiences.
However, the study also highlights the need for further research to fully address the complexities of building robust, culturally-sensitive multilingual recommenders. By continuing to explore these issues, the field can work towards creating recommender systems that are truly inclusive and accessible to users around the world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multilingual Prompts in LLM-Based Recommenders: Performance Across Languages
Makbule Gulcin Ozsoy
Large language models (LLMs) are increasingly used in natural language processing tasks. Recommender systems traditionally use methods such as collaborative filtering and matrix factorization, as well as advanced techniques like deep learning and reinforcement learning. Although language models have been applied in recommendation, the recent trend have focused on leveraging the generative capabilities of LLMs for more personalized suggestions. While current research focuses on English due to its resource richness, this work explores the impact of non-English prompts on recommendation performance. Using OpenP5, a platform for developing and evaluating LLM-based recommendations, we expanded its English prompt templates to include Spanish and Turkish. Evaluation on three real-world datasets, namely ML1M, LastFM, and Amazon-Beauty, showed that usage of non-English prompts generally reduce performance, especially in less-resourced languages like Turkish. We also retrained an LLM-based recommender model with multilingual prompts to analyze performance variations. Retraining with multilingual prompts resulted in more balanced performance across languages, but slightly reduced English performance. This work highlights the need for diverse language support in LLM-based recommenders and suggests future research on creating evaluation datasets, using newer models and additional languages.
Read more9/14/2024
💬
0
LLM-Rec: Personalized Recommendation via Prompting Large Language Models
Hanjia Lyu, Song Jiang, Hanqing Zeng, Yinglong Xia, Qifan Wang, Si Zhang, Ren Chen, Christopher Leung, Jiajie Tang, Jiebo Luo
Text-based recommendation holds a wide range of practical applications due to its versatility, as textual descriptions can represent nearly any type of item. However, directly employing the original item descriptions may not yield optimal recommendation performance due to the lack of comprehensive information to align with user preferences. Recent advances in large language models (LLMs) have showcased their remarkable ability to harness commonsense knowledge and reasoning. In this study, we introduce a novel approach, coined LLM-Rec, which incorporates four distinct prompting strategies of text enrichment for improving personalized text-based recommendations. Our empirical experiments reveal that using LLM-augmented text significantly enhances recommendation quality. Even basic MLP (Multi-Layer Perceptron) models achieve comparable or even better results than complex content-based methods. Notably, the success of LLM-Rec lies in its prompting strategies, which effectively tap into the language model's comprehension of both general and specific item characteristics. This highlights the importance of employing diverse prompts and input augmentation techniques to boost the recommendation effectiveness of LLMs.
Read more4/3/2024
💬
0
New!Large Language Models are Good Multi-lingual Learners : When LLMs Meet Cross-lingual Prompts
Teng Wang, Zhenqi He, Wing-Yin Yu, Xiaojin Fu, Xiongwei Han
With the advent of Large Language Models (LLMs), generating rule-based data for real-world applications has become more accessible. Due to the inherent ambiguity of natural language and the complexity of rule sets, especially in long contexts, LLMs often struggle to follow all specified rules, frequently omitting at least one. To enhance the reasoning and understanding of LLMs on long and complex contexts, we propose a novel prompting strategy Multi-Lingual Prompt, namely MLPrompt, which automatically translates the error-prone rule that an LLM struggles to follow into another language, thus drawing greater attention to it. Experimental results on public datasets across various tasks have shown MLPrompt can outperform state-of-the-art prompting methods such as Chain of Thought, Tree of Thought, and Self-Consistency. Additionally, we introduce a framework integrating MLPrompt with an auto-checking mechanism for structured data generation, with a specific case study in text-to-MIP instances. Further, we extend the proposed framework for text-to-SQL to demonstrate its generation ability towards structured data synthesis.
Read more9/18/2024
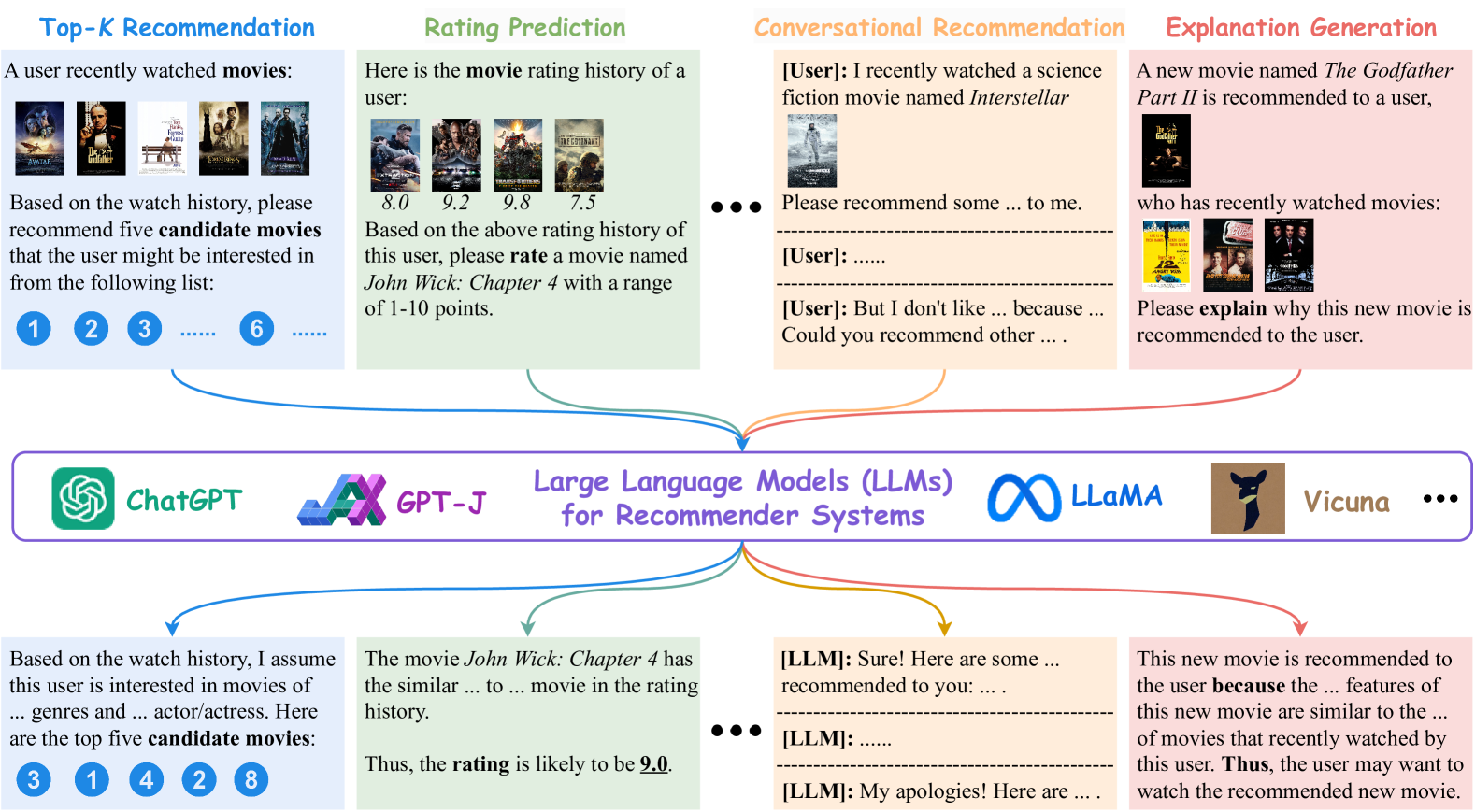
2
Recommender Systems in the Era of Large Language Models (LLMs)
Zihuai Zhao, Wenqi Fan, Jiatong Li, Yunqing Liu, Xiaowei Mei, Yiqi Wang, Zhen Wen, Fei Wang, Xiangyu Zhao, Jiliang Tang, Qing Li
With the prosperity of e-commerce and web applications, Recommender Systems (RecSys) have become an important component of our daily life, providing personalized suggestions that cater to user preferences. While Deep Neural Networks (DNNs) have made significant advancements in enhancing recommender systems by modeling user-item interactions and incorporating textual side information, DNN-based methods still face limitations, such as difficulties in understanding users' interests and capturing textual side information, inabilities in generalizing to various recommendation scenarios and reasoning on their predictions, etc. Meanwhile, the emergence of Large Language Models (LLMs), such as ChatGPT and GPT4, has revolutionized the fields of Natural Language Processing (NLP) and Artificial Intelligence (AI), due to their remarkable abilities in fundamental responsibilities of language understanding and generation, as well as impressive generalization and reasoning capabilities. As a result, recent studies have attempted to harness the power of LLMs to enhance recommender systems. Given the rapid evolution of this research direction in recommender systems, there is a pressing need for a systematic overview that summarizes existing LLM-empowered recommender systems, to provide researchers in relevant fields with an in-depth understanding. Therefore, in this paper, we conduct a comprehensive review of LLM-empowered recommender systems from various aspects including Pre-training, Fine-tuning, and Prompting. More specifically, we first introduce representative methods to harness the power of LLMs (as a feature encoder) for learning representations of users and items. Then, we review recent techniques of LLMs for enhancing recommender systems from three paradigms, namely pre-training, fine-tuning, and prompting. Finally, we comprehensively discuss future directions in this emerging field.
Read more4/23/2024