Multimodality Invariant Learning for Multimedia-Based New Item Recommendation

0
Sign in to get full access
Overview
- This paper proposes a new approach for multimedia-based new item recommendation called Multimodality Invariant Learning (MIL).
- MIL aims to learn a robust and effective recommendation model that can handle missing modalities during inference.
- The key idea is to learn modality-invariant representations that capture the underlying semantics of items, enabling accurate recommendations even when some modalities are unavailable.
Plain English Explanation
The paper tackles the challenge of multimedia-based recommendation, where information about items comes from different sources like images, text, and audio. This is useful for recommending new products, articles, or other content to users.
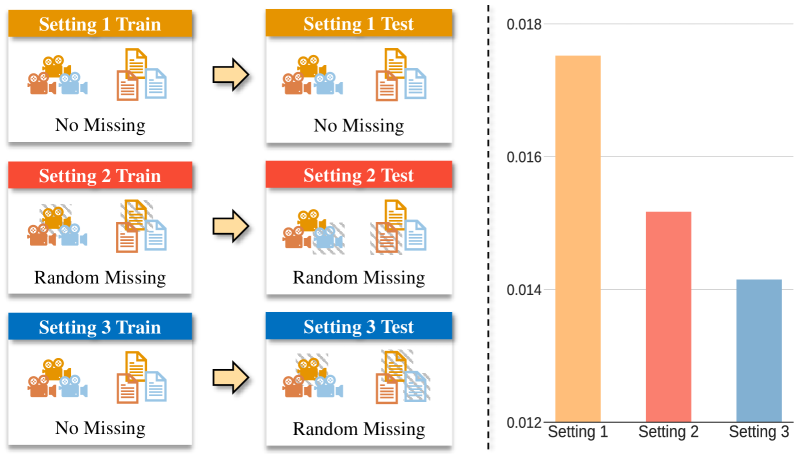
The problem is that during actual use, some of these information sources might be missing - for example, a new product might not have any images available yet. Traditional recommendation models struggle in this case, as they rely on all the available modalities to make accurate predictions.
The researchers propose a new approach called Multimodality Invariant Learning (MIL) that can learn representations of items that are robust to missing modalities. The key idea is to train the model to extract the underlying meaning or "semantics" of an item, rather than just memorizing the specific combinations of modalities.
This means the model can still make good recommendations even when some of the information sources are unavailable, by focusing on the core essence of the item. The authors demonstrate through experiments that MIL outperforms other multimodal recommendation approaches in scenarios with missing modalities.
Technical Explanation
The core of the MIL approach is a novel neural network architecture that learns modality-invariant representations of items. It consists of several key components:
-
Multimodal Encoder: This module takes the available modalities (e.g. image, text, audio) as input and learns a joint representation capturing the semantics of the item.
-
Modality-Specific Encoders: These sub-networks specialize in encoding each individual modality, which helps the model leverage the unique information in each data source.
-
Modality-Invariant Projection: A key innovation is a projection layer that maps the multimodal representation into a modality-invariant latent space. This ensures the learned representation captures the underlying semantics rather than just superficial correlations between modalities.
-
Recommendation Head: This final component takes the modality-invariant representation and produces the desired recommendation outputs, such as item rankings or ratings.
The model is trained end-to-end using a combination of reconstruction loss (to preserve modality-specific information) and invariance loss (to encourage modality-agnostic representations). Extensive experiments on real-world datasets demonstrate the advantages of MIL, especially in scenarios with missing modalities during inference.
Critical Analysis
The paper makes a strong case for the importance of learning modality-invariant representations in multimedia recommendation systems. The proposed MIL approach represents a principled way to address the challenge of missing modalities, which is a common problem in real-world deployment.
However, the authors acknowledge some limitations of their work. For example, the current formulation assumes independence between modalities, whereas in practice there may be complex relationships that could be better exploited. Additionally, the experiments focus on relatively simple recommendation tasks, and it remains to be seen how well MIL scales to more complex, large-scale scenarios.
Future research could explore ways to further improve the modality-invariance property, perhaps by incorporating ideas from contrastive learning or adversarial training. Investigating the interpretability and explainability of the learned representations could also be a fruitful direction.
Conclusion
This paper presents a novel Multimodality Invariant Learning (MIL) approach for multimedia-based new item recommendation. MIL learns modality-agnostic representations that capture the underlying semantics of items, enabling accurate recommendations even when some information sources are missing.
The technical innovations and empirical results demonstrate the potential of this approach to improve the robustness and practical applicability of multimedia recommendation systems. As the field of multimodal machine learning continues to evolve, techniques like MIL will likely play an important role in building intelligent systems that can seamlessly handle real-world data and user scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!