Multiply Robust Estimation for Local Distribution Shifts with Multiple Domains
2402.14145
0
0

Abstract
Distribution shifts are ubiquitous in real-world machine learning applications, posing a challenge to the generalization of models trained on one data distribution to another. We focus on scenarios where data distributions vary across multiple segments of the entire population and only make local assumptions about the differences between training and test (deployment) distributions within each segment. We propose a two-stage multiply robust estimation method to improve model performance on each individual segment for tabular data analysis. The method involves fitting a linear combination of the based models, learned using clusters of training data from multiple segments, followed by a refinement step for each segment. Our method is designed to be implemented with commonly used off-the-shelf machine learning models. We establish theoretical guarantees on the generalization bound of the method on the test risk. With extensive experiments on synthetic and real datasets, we demonstrate that the proposed method substantially improves over existing alternatives in prediction accuracy and robustness on both regression and classification tasks. We also assess its effectiveness on a user city prediction dataset from Meta.
Create account to get full access
Overview
- This paper proposes a new method called "Multiply Robust Estimation" for addressing distribution shifts across multiple domains.
- The method aims to provide robust estimates of target quantities, like regression coefficients, under various types of distribution shifts, including covariate shift and label shift.
- The paper introduces theoretical guarantees and an efficient algorithm for the proposed approach, and demonstrates its effectiveness through experiments on both synthetic and real-world datasets.
Plain English Explanation
Machine learning models are often trained on data that doesn't perfectly match the real-world scenarios they'll be used in. This can lead to performance degradation, a problem known as "distribution shift".
The authors of this paper tackle this challenge by proposing a new technique called "Multiply Robust Estimation." The key idea is to leverage multiple sources of information to make the model more resilient to different types of distribution shifts, such as changes in the input features (covariate shift) or changes in the target variable (label shift).
By combining these different sources of information in a principled way, the authors show that their method can provide accurate estimates of target quantities, like regression coefficients, even when the training and test distributions differ in complex ways. This is an important advancement, as it can help machine learning models perform better in the real world, where distribution shifts are commonly encountered.
Technical Explanation
The key technical contribution of this paper is the "Multiply Robust Estimation" (MRE) framework, which builds on ideas from causal inference and robust statistics. The method assumes access to multiple "domains" or datasets, each with potentially different input and output distributions.
The authors show that by leveraging information from these multiple domains, they can obtain estimates of target quantities that are robust to a wide range of distribution shifts, including covariate shift and label shift. Specifically, the MRE approach combines estimates from different "nuisance" models (e.g., propensity scores, outcome models) in a way that is guaranteed to be consistent as long as at least one of the nuisance models is correctly specified.
The paper provides theoretical guarantees for the MRE approach, including bounds on the estimation error and the breakdown point (the maximum fraction of corrupted data the method can tolerate). The authors also propose an efficient algorithm for implementing MRE in practice, and demonstrate its effectiveness through experiments on both synthetic and real-world datasets, including applications in causal inference and domain adaptation.
Critical Analysis
The authors of this paper make a compelling case for the Multiply Robust Estimation (MRE) framework as a powerful tool for addressing distribution shifts in machine learning. The theoretical guarantees and the experimental results suggest that MRE can indeed provide robust estimates in the face of complex distribution shifts, which is a significant advancement over existing methods.
One potential limitation of the MRE approach is that it requires access to multiple datasets or "domains" to leverage the different sources of information. In some real-world scenarios, this may not always be feasible, and the method may not be applicable. Additionally, the paper does not explore the sample complexity requirements of the MRE approach, which could be an important consideration in practical applications.
Furthermore, the paper does not delve into the computational complexity of the proposed algorithm, which could be a concern when dealing with large-scale datasets or high-dimensional problems. It would be valuable for future work to investigate the scalability of the MRE method and explore potential ways to improve its efficiency.
Despite these minor caveats, the Multiply Robust Estimation framework represents an important contribution to the field of domain adaptation and robust machine learning. The authors have laid a solid theoretical foundation and provided convincing empirical evidence for the effectiveness of their approach, which could have significant implications for a wide range of real-world applications where distribution shifts are a common challenge.
Conclusion
This paper introduces a novel "Multiply Robust Estimation" (MRE) framework for addressing distribution shifts in machine learning, which can arise due to changes in input features (covariate shift) or target variables (label shift). By leveraging information from multiple datasets or "domains," the MRE approach can provide robust estimates of target quantities, such as regression coefficients, even in the presence of complex distribution shifts.
The key idea behind MRE is to combine estimates from different "nuisance" models in a way that guarantees consistency as long as at least one of the nuisance models is correctly specified. This allows the method to be more resilient to model misspecification compared to traditional approaches. The paper provides strong theoretical guarantees for the MRE framework and demonstrates its effectiveness through experiments on both synthetic and real-world datasets.
The Multiply Robust Estimation framework represents an important advancement in the field of domain adaptation and robust machine learning. It could have significant practical implications for a wide range of applications where distribution shifts are a common challenge, such as causal inference and out-of-distribution generalization. As the authors have noted, future work could explore the scalability of the MRE method and investigate its applicability in additional real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
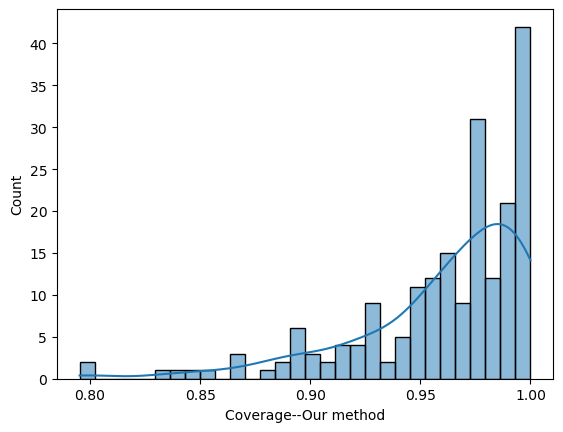
Optimal Aggregation of Prediction Intervals under Unsupervised Domain Shift
Jiawei Ge, Debarghya Mukherjee, Jianqing Fan
0
0
As machine learning models are increasingly deployed in dynamic environments, it becomes paramount to assess and quantify uncertainties associated with distribution shifts. A distribution shift occurs when the underlying data-generating process changes, leading to a deviation in the model's performance. The prediction interval, which captures the range of likely outcomes for a given prediction, serves as a crucial tool for characterizing uncertainties induced by their underlying distribution. In this paper, we propose methodologies for aggregating prediction intervals to obtain one with minimal width and adequate coverage on the target domain under unsupervised domain shift, under which we have labeled samples from a related source domain and unlabeled covariates from the target domain. Our analysis encompasses scenarios where the source and the target domain are related via i) a bounded density ratio, and ii) a measure-preserving transformation. Our proposed methodologies are computationally efficient and easy to implement. Beyond illustrating the performance of our method through a real-world dataset, we also delve into the theoretical details. This includes establishing rigorous theoretical guarantees, coupled with finite sample bounds, regarding the coverage and width of our prediction intervals. Our approach excels in practical applications and is underpinned by a solid theoretical framework, ensuring its reliability and effectiveness across diverse contexts.
5/17/2024
💬
On the Need of a Modeling Language for Distribution Shifts: Illustrations on Tabular Datasets
Jiashuo Liu, Tianyu Wang, Peng Cui, Hongseok Namkoong
0
0
Different distribution shifts require different interventions, and algorithms must be grounded in the specific shifts they address. However, methodological development for ''robust'' methods typically relies on structural assumptions that lack empirical validation. Advocating for an empirically grounded inductive approach to research, we build an empirical testbed comprising natural shifts across 5 tabular datasets and 60,000 method configurations encompassing imbalanced learning methods and distributionally robust optimization (DRO) methods. We find $Y|X$-shifts are most prevalent on our testbed, in stark contrast to the heavy focus on $X$ (covariate)-shifts in the ML literature. The performance of ''robust'' methods varies significantly over shift types, and is no better than that of vanilla methods. To understand why, we conduct an in-depth empirical analysis of DRO methods and find that although often neglected by researchers, implementation details -- such as the choice of underlying model class (e.g., XGBoost) and hyperparameter selection -- have a bigger impact on performance than the ambiguity set or its radius. To further bridge that gap between methodological research and practice, we design case studies that illustrate how such a refined, inductive understanding of distribution shifts can enhance both data-centric and algorithmic interventions.
6/26/2024
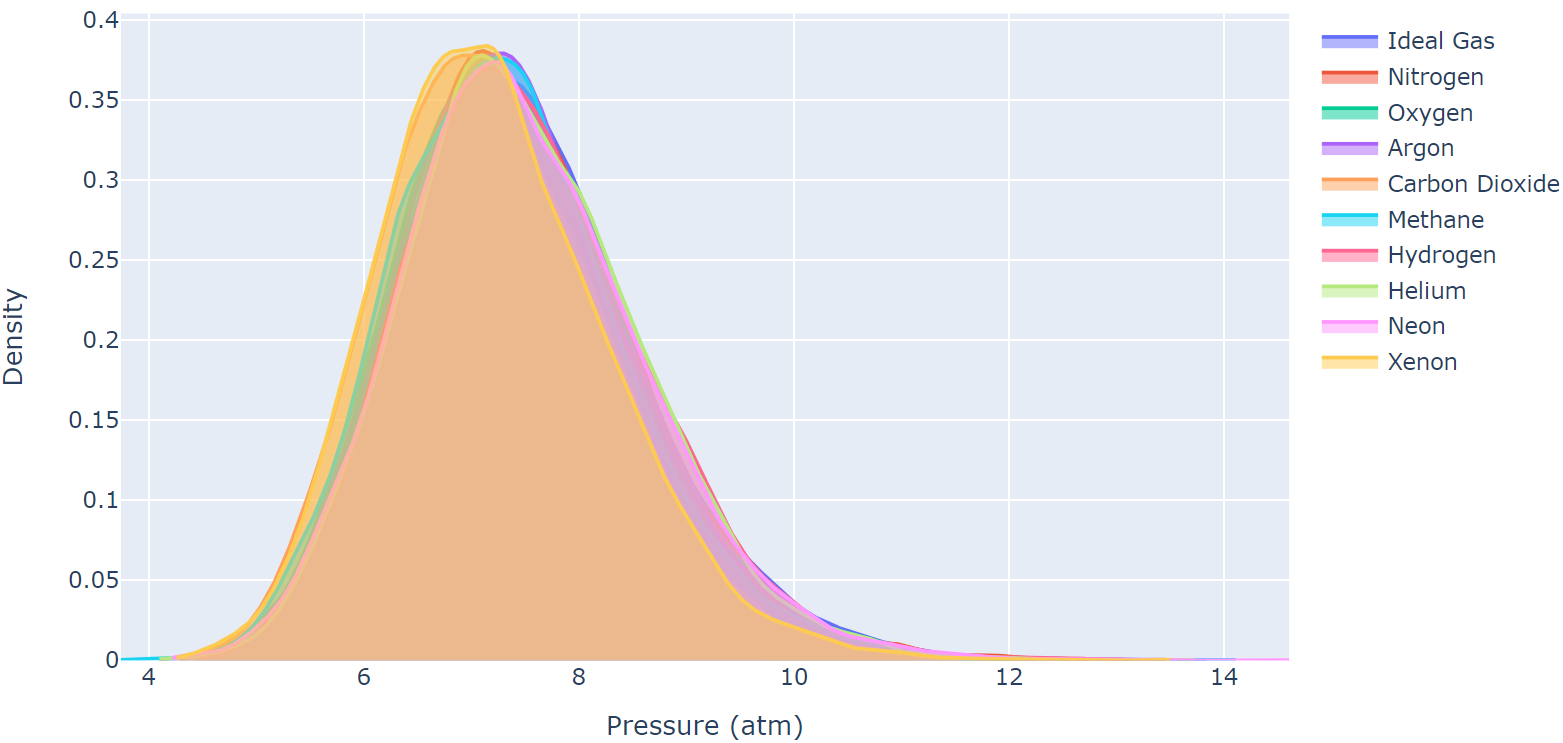
Quantifying Distribution Shifts and Uncertainties for Enhanced Model Robustness in Machine Learning Applications
Vegard Flovik
0
0
Distribution shifts, where statistical properties differ between training and test datasets, present a significant challenge in real-world machine learning applications where they directly impact model generalization and robustness. In this study, we explore model adaptation and generalization by utilizing synthetic data to systematically address distributional disparities. Our investigation aims to identify the prerequisites for successful model adaptation across diverse data distributions, while quantifying the associated uncertainties. Specifically, we generate synthetic data using the Van der Waals equation for gases and employ quantitative measures such as Kullback-Leibler divergence, Jensen-Shannon distance, and Mahalanobis distance to assess data similarity. These metrics en able us to evaluate both model accuracy and quantify the associated uncertainty in predictions arising from data distribution shifts. Our findings suggest that utilizing statistical measures, such as the Mahalanobis distance, to determine whether model predictions fall within the low-error interpolation regime or the high-error extrapolation regime provides a complementary method for assessing distribution shift and model uncertainty. These insights hold significant value for enhancing model robustness and generalization, essential for the successful deployment of machine learning applications in real-world scenarios.
5/6/2024

Multiply-Robust Causal Change Attribution
Victor Quintas-Martinez, Mohammad Taha Bahadori, Eduardo Santiago, Jeff Mu, Dominik Janzing, David Heckerman
0
0
Comparing two samples of data, we observe a change in the distribution of an outcome variable. In the presence of multiple explanatory variables, how much of the change can be explained by each possible cause? We develop a new estimation strategy that, given a causal model, combines regression and re-weighting methods to quantify the contribution of each causal mechanism. Our proposed methodology is multiply robust, meaning that it still recovers the target parameter under partial misspecification. We prove that our estimator is consistent and asymptotically normal. Moreover, it can be incorporated into existing frameworks for causal attribution, such as Shapley values, which will inherit the consistency and large-sample distribution properties. Our method demonstrates excellent performance in Monte Carlo simulations, and we show its usefulness in an empirical application. Our method is implemented as part of the Python library DoWhy (arXiv:2011.04216, arXiv:2206.06821).
6/4/2024